聚类算法讲解:KMEANS和DBSCAN
Posted 人工智能训练营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聚类算法讲解:KMEANS和DBSCAN相关的知识,希望对你有一定的参考价值。
K-MEANS主要是用来处理无监督问题的聚类算法,是聚类算法最简单也是最实用的算法。
此算法首先需要指定K值,也就是想要将数据聚成K类、K簇。第二个概念就是质心,即均值,一簇数据在每个维度取均值即这个簇的质心。第三个概念是距离的度量,用来判断样本点的相似度,最常用的度量方式是欧式距离和余弦相似度。先对数据进行标准化,各维度的单位长度差异比较大,保证取值范围在较小范围内浮动。
优化目标:样本到各类质心的距离越小越好。样本点到质心的距离越近说明,说明此类样本点越距离,聚类越准确。
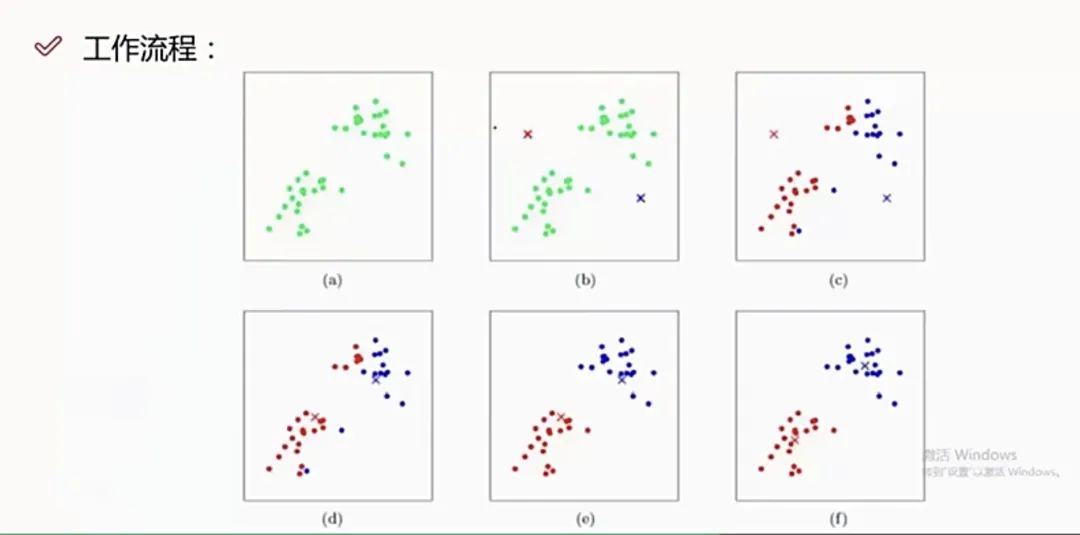
KMEANS工作流程:
1. 先设定K值
2. 随机初始化K个质心点
3. 计算每个样本点到各个质心点的距离,样本点距离哪个质心的距离最小,就归到哪一类中。
4. 所有的样本点都归类结束后,更新质心点。对每个类重新算均值,算质心。
5. 重新遍历样本点,对样本点重新计算距离并归类。
6. 直到样本点分类不在发生变化,停止更新
优点:简单、快速、适合常规数据集
缺点:K值难确定、复杂度与样本数量呈线性关系、很难发现不规则形状的簇
DBSCAN
首先介绍几个概念:
核心对象:若以某个点为圆心,r为半径,若此圆内点的个数不小于设定的阈值minPts,则称此圆心为核心对象。半径r和阈值minPts都需要提前指定。DBSCAN无需设定K值
直接密度可达:若点p在点q的r邻域内,且q是核心对象,则pq直接密度可达。
密度可达:若有一个点的序列q0,q1,…qk,对任意qi到qi-1都是直接密度可达,则称从q0到qk密度可达,这实际上是直接密度可达的传播。
边界点:以边界点为中心的r邻域内除了上线之外没有别的点,即有上线无下线。
噪声点:不属于任何一个簇的点,从任何一个核心对象出发都是密度不可达的。以边界点为中心的r邻域内没有点
工作流程:
1. 数据集
2. 指定半径r
3. 密度阈值
KMEANS具体工作流程如下:
随机选择一个未标记点p将其标记
如果p是核心对象,则将其添加到类C
N是点p r邻域内所有点的集合
对于N内的点遍历,遍历过的都标记
并且这些点如果也是核心对象,那么把这些点r邻域内的点加到N集合中
如果这些点不属于任何类,则归到C类
直到剩下的点都是边界点
对于剩下的没被标记的,选一个点作为点p继续循环上述过程
直到所有点都被标记
半径r的确定:k距离
给定数据集P,计算出Pi到其他点的距离,将距离从小到大进行排序,若距离dk和dk+1的差距非常大,则选择突变点dk为半径r
minPts:一般取小一些。
优势:
1. 不需要指定簇的个数K值
2. 可以发现任意形状的簇
3. 擅长找到离群点,做异常检测任务
4. 两个参数即可
缺点:
1. 高维数据处理起来有点困难
2. 参数难以选择,且对结果的影响比较大
3. 效率比较慢。
以上是关于聚类算法讲解:KMEANS和DBSCAN的主要内容,如果未能解决你的问题,请参考以下文章