R语言文本挖掘| 网页爬虫新闻内容
Posted 菜鸟学数据分析之R语言
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言文本挖掘| 网页爬虫新闻内容相关的知识,希望对你有一定的参考价值。
01
目标
读取该网页的新闻,包括新闻标题,发文日期,时间,每条新闻链接,文章内容
图1 网页部分截图
02
安装与加载包
install.packages("rvest")library(rvest)
03
网页读取
url<-'https://www.thepaper.cn/'web<-read_html(url)news<-web%>%html_nodes('h2 a')
#用浏览器打开网页,右键单击-检查,查看网页源代码特点,可以知道每条新闻位于h2,a节点读取网页节点。
如何查看节点确定每篇新闻所在位置为'h2 a',详见视频:
后台回复【网页节点】查看视频
04
新闻题目title爬取
#获取title
title<-news%>%html_text()#读取新闻题目#查看前6行题目特点
head(link)
图2 link数据特点
从link的数据结构看,我们只需要href,这个就是每个新闻对应的子链接,因此,我们要写一个循环,将link中的href提取出来。
link1<-c(1:length(link))for(i in 1:length(link)){link1[i]<-link[[i]][1]}
#查看link1特点
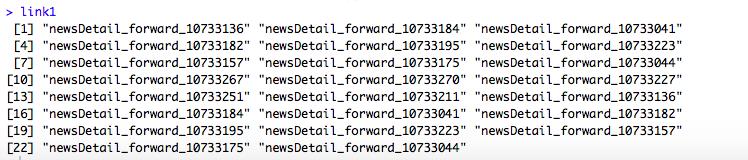
图3 link1数据特点
从link1来看,并不完全是链接格式,接下来利用paste将
https://www.thepaper.cn/与link1中的进行连接得到link2link2<-paste("https://www.thepaper.cn/",link1,sep="")link2
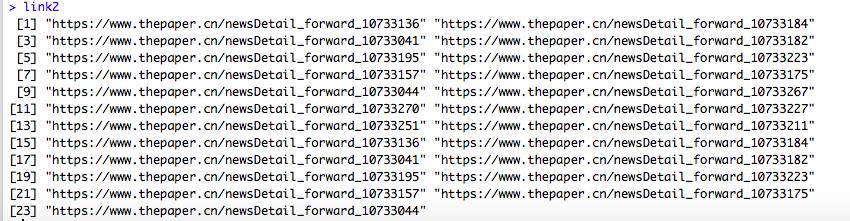
图4 link4结构特点
05
新闻发布日期date、时间time、内容content获取
news_date<-c(1:length(link2))date<-c(1:length(link2))news_time<-c(1:length(link2))news_link<-c(1:length(link2))news_content<-c(1:length(link2))for(i in 1:length(link2)){news_date[i]<-(read_html(link2[i])%>%html_nodes('div p')%>%html_text())[3]date[i]<-strsplit(news_date,split = " ")[[i]][25]news_time[i]<-strsplit(news_date,split=" ")[[i]][26]news_content[i]<-read_html(link2[i])%>%html_nodes(('div.news_txt'))%>%html_text()}
#构建数据框
data_lxl<-data.frame(title,date,news_time,link2,news_content)View(data_lxl)
图4 网页爬虫结果
06
数据分析与可视化
参考往期文章:
文本 | 数据分析 | 可视化
后台回复【网页节点查看视频】
领取相关资料
以上是关于R语言文本挖掘| 网页爬虫新闻内容的主要内容,如果未能解决你的问题,请参考以下文章