喜马拉雅:基于 WeNet 和 gRPC 的语音识别微服务架构的设计和应用
Posted WeNet步行街
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了喜马拉雅:基于 WeNet 和 gRPC 的语音识别微服务架构的设计和应用相关的知识,希望对你有一定的参考价值。
近日,喜马拉雅语音团队在wenet中增加了基于gRPC的流式语音识别的支持。本文由喜马拉雅语音团队撰写,介绍wenet中的gRPC的设计和实现,并介绍喜马拉雅基于wenet和gRPC的语音识别微服务架构的设计和应用。
喜马拉雅科技有限公司是中国最大的有声读物平台,于2012年8月成立,2021年第一季度喜马拉雅全场景流量月活用户达到2.50亿。喜马拉雅AI语音组是喜马拉雅的核心部门,专注于语音合成、识别、语音信号处理、编解码以及智能音效的研究和开发,同时对接公司内外的多项业务和落地场景。
wenet介绍
wenet是由出门问问公司推出的一款开源ASR工具,自问世开始便积聚了大量人气。常规的ASR工具,或把模型训练过程中的复杂细节进行封装,为算法人员的模型训练过程提供便利;或把kaldi的速度与pytorch的便利通过脚本的方式结合了起来,加速了模型的训练过程。
wenet与以往工具不同之处在于,自问世起,它就同时提供了基于python/pytorch的训练脚本和基于c++/libtorch的工程化部署方案,是真正面向工业界的ASR工具。

websocket介绍
既然谈到工业界,就不得不谈到服务。业界大部分公司的流式ASR服务,都会支持websocket接口,这是因为websocket支持双向的流式数据传输,
wenet自身也提供了基于websocket的服务端/客户端示例。诚然,websocket具备轻量级、简单易用的优点,但在大型服务体系中,它的缺点也很明显。
使用过wenet的websocket客户端的朋友们应该清楚,流式识别过程分为三个步骤。wenet中的协议如下,首先,设置模式为发送text,发送形如{{"signal", "start"}{"nbest",1}}的json字符串标志开始,然后,设置模式为发送bytes,发送pcm数据,最后,设置模式为发送text,发送{{"signal", "end"}}的json字符串标志结束。websocket服务端的解析逻辑也是相当麻烦。首先需判断获取的数据是text还是bytes,再执行相应逻辑。若为text,还需尝试进行json解析,判断是否存在signal/nbest这些key,解析过程需加上大量的异常处理逻辑。
对接口设计比较敏感的朋友们肯定已经发现了websocket的弊端,即接口无硬性约束,全靠文档或口头对接,调用过程极易出错。肯定有朋友会说,哎呀我不想写这些乱七八糟的消息构造/解析代码,我就想关注服务调用的主要流程,有没有办法避免掉这些dirty work呢?有的,答案就是gRPC。
gRPC+protobuf介绍
gRPC是由google开发的一套RPC框架,基于http2.0,支持双向流式通信。gRPC的通信使用的是protobuf协议,接口定义更加清晰,还能减少数据传输量。gRPC+protobuf的好处不再赘述,对它们有深入兴趣的朋友们可以看一些详细介绍的博客。总结一下,google大法好。
有一点需要提醒的是,由于gRPC存在多路复用的概念,若朋友们基于k8s平台部署,常规的基于连接层的负载均衡器不会生效。但在我们看来,这恰恰是gRPC先进性的体现,说明它步子迈太大,兄弟们没跟上。大家或者可以使用nginx1.13.10以上版本进行请求转发,或者像喜马拉雅内部有一套consul服务发现/注册系统,客户端可以自行实现负载均衡策略。
wenet的proto设计
gRPC的接口定义描述在以proto为后缀的文件中。在gRPC中,每一个返回字段都有明确的类型定义。从而使得服务端的开发人员,仅通过proto文件,就可轻松得知如何调用gRPC服务。
针对wenet,我们设计了如下的proto文件,位于https://github.com/wenet-e2e/wenet/blob/main/runtime/core/gRPC/wenet.proto。分块介绍如下:
service ASR {
rpc Recognize (stream Request) returns (stream Response) {}
}
以上部分说明,我们的服务名为ASR,实现了Recognize方法,输入输出皆为流式(由stream关键字标示)
message Request {
message DecodeConfig {
int32 nbest_config = 1;
bool continuous_decoding_config = 2;
}
oneof RequestPayload {
DecodeConfig decode_config = 1;
bytes audio_data = 2;
}
}
流式请求的Request是DecodeConfig/bytes中的一种(oneof关键字),其中DecodeConfig包含nbest_config/continuous_decoding_config两个字段,分别为int/bool类型
message Response {
message OneBest {
string sentence = 1;
repeated OnePiece wordpieces = 2;
}
message OnePiece {
string word = 1;
int32 start = 2;
int32 end = 3;
}
enum Status {
ok = 0;
failed = 1;
}
enum Type {
server_ready = 0;
partial_result = 1;
final_result = 2;
speech_end = 3;
}
Status status = 1;
Type type = 2;
repeated OneBest nbest = 3;
}
流式请求的Response含status/type/nbest三个字段,其中status/type为枚举类型,说明它们的赋值必须为范围内的一种。nbest为repeated OneBest类型,OneBest则由sentence和wordpieces字段组成。
大家可以看到,服务端/客户端无需存在任何hard-code的代码,所有字段都可以从Request/Response中以属性的方式获取。
wenet的gRPC实现
基于wenet的gRPC实现,其代码已经进行了merge,代码位于https://github.com/wenet-e2e/wenet/tree/main/runtime/core/{grpc,bin}
首先我们需编译proto文件,得到wenet.grpc.pb.h,wenet.grpc.pb.cc,wenet.pb.h,wenet.pb.cc四个文件。细心的朋友们肯定会发现,wenet.pb.h/cc中存储了protobuf数据格式的定义,wenet.grpc.pb.h中存储了gRPC服务端/客户端的定义。
gRPC服务端
gRPC服务端对纯虚基类ASR::Service进行继承并实现即可。
在Recognize方法中,我们做法与wenet自带的websocket完全相同,即每来一个gRPC请求,初始化一个GRPCConnectionHandler进行处理。通过ServerReaderWriter类型的stream对象,即可实现双向流式通信。
Status GrpcServer::Recognize(ServerContext* context,
ServerReaderWriter<Response, Request>* stream) {
LOG(INFO) << "Get Recognize request" << std::endl;
auto request = std::make_shared<Request>();
auto response = std::make_shared<Response>();
GrpcConnectionHandler handler(stream, request, response, feature_config_,
decode_config_, symbol_table_, model_, fst_);
std::thread t(std::move(handler));
t.join();
return Status::OK;
}
gRPC客户端
客户端则需实例化ASR::Stub,通过ClientReaderWriter类型的stream对象,即可实现双向流式通信。
void GrpcClient::Connect() {
channel_ = grpc::CreateChannel(host_ + ":" + std::to_string(port_),
grpc::InsecureChannelCredentials());
stub_ = ASR::NewStub(channel_);
context_ = std::make_shared<ClientContext>();
stream_ = stub_->Recognize(context_.get());
request_ = std::make_shared<Request>();
response_ = std::make_shared<Response>();
request_->mutable_decode_config()->set_nbest_config(nbest_);
request_->mutable_decode_config()->set_continuous_decoding_config(
continuous_decoding_);
stream_->Write(*request_);
}
喜马拉雅的流式ASR架构设计
通过以上介绍,有些动手能力强的朋友们可能会觉得,不管是gRPC,还是websocket服务,也就那么回事嘛,基于wenet搭建一个服务也并非难事。

其实我们也完全同意这样的看法,搭建一个流式服务并不难。但搭建一个流式服务架构,并在满足业务需求的同时,减轻后端开发/算法同学的工作量,则是一件讲究的事情。接下来,我们将介绍喜马拉雅语音团队及目前的流式微服务架构。
服务开发/算法训练过程中的问题
各位算法/开发同学,有没有碰到过以下情况:
1.我用Pytorch训了个模型,但可惜我们的服务是基于Kaldi的,上不了线
2.我开发了个预处理模块,用了一些Python的库,但我们的服务是Java/C++的,改写难度太大
3.我的服务出bug了,因为开发同学把我的算法逻辑写错了
4.业务有个新需求,要调用新的算法模块。开发同学只好加班加点修改线上服务,把新的算法代码添加到服务中
......
以上问题,如何解决?答案很简单,云原生(当然云原生也不是万能的,还是看服务架构是否适合云原生)
云原生的微服务如何解决该问题
在云原生的理念中,微服务/RPC是其中的精髓。
微服务解决了算法快速上线的问题,不管你是Python/Java/C++/Go,不管你是tensorflow/pytorch/kaldi,你只要将自己的算法模块以微服务的形式上线即可。RPC则提供了对外调用的方式。通过微服务的组合,我们可以对业务快速输出新的能力。
喜马拉雅的流式ASR架构
喜马拉雅的流式ASR目前初步分为4个微服务--业务接入服务/流式VAD服务/流式ASR服务/流式后处理服务。
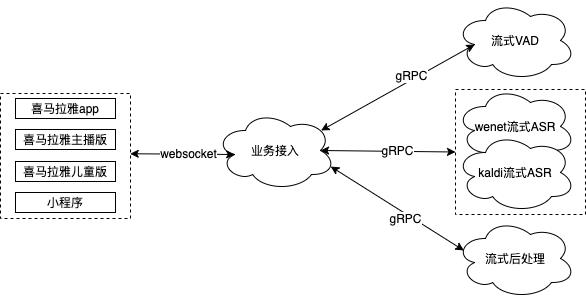
基于websocket的业务接入服务
业务接入服务,即所有业务的入口。对于业务方,我们提供最为通用的接口,即websocket调用方式(当然对于愿意配合的业务方,我们也可以提供原生的gRPC调用方式)。
每个业务在调用我们的流式服务之前,需在接入服务进行注册。注册的内容目前包含:采样率/比特数/通道数/是否定制模型/是否使用热词/何种后处理算法等等配置项。业务接入服务会根据不同业务的配置情况,自由组合后端的流式VAD/ASR/后处理服务,对业务进行输出。
所有的业务逻辑/预处理,如数据统一规整为16k/16bit,都会在业务接入服务进行处理。后端算法服务中不含任何业务逻辑。

基于gRPC的流式VAD/ASR/后处理服务
流式VAD/ASR/后处理服务,我们可以统称为算法服务。因为大部分算法人员对于C++/Java开发并不熟悉,后端算法服务统一基于gRPC进行封装,从而发挥了gRPC跨语言的优势。每个算法模块,其算法验证、服务上线、业务跟进由同一个人负责,极大的增加了算法人员的效率。再也没有算法人员与开发人员互相沟通,最后出现问题面面相觑的情景。
如英文ASR模型开发完毕,由该算法人员使用任意语言如python进行gRPC封装,使用公司的发布平台进行上线,最终向业务接入服务的负责人员提供一个接口即可。
采用微服务架构后的现状
喜马拉雅的流式微服务架构,即吸取了websocket的轻量级优势,又融合了gRPC的工程开发的便捷性,使得喜马拉雅的流式ASR服务可以快速相应业务需求。
对比常规的单体流式服务,从开发的角度,算法/开发人员的工作量极大减轻,只需使用自己最习惯的语言进行服务模块上线即可。从业务的角度,每当有新的业务需求,如业务A无需调用VAD/业务B需使用数字规整等,业务接入服务将后端算法能力进行组合即可,工作量很小。若后端能力已经具备,可以随时上线。
有些比较细心的同学们可能会提出疑问,微服务拆分后增加了模块间通信时间,会不会对实时率有较大影响?我们实践下来发现,微服务拆分带来的额外延时是很小的。一组相关的服务,通常会部署在同一个机房,甚至在k8s的同一个pod中。其通信时间以ms计。相比于给开发/算法人员带来的便利性而言,我们认为额外几十ms的延时是值得的。
往期精彩
| We make the Net better |
长按二维码关注 |
以上是关于喜马拉雅:基于 WeNet 和 gRPC 的语音识别微服务架构的设计和应用的主要内容,如果未能解决你的问题,请参考以下文章