图片获取太麻烦?python爬虫实战:百度百万级图片采集
Posted lland5201314
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图片获取太麻烦?python爬虫实战:百度百万级图片采集相关的知识,希望对你有一定的参考价值。
项目分析
效果展示
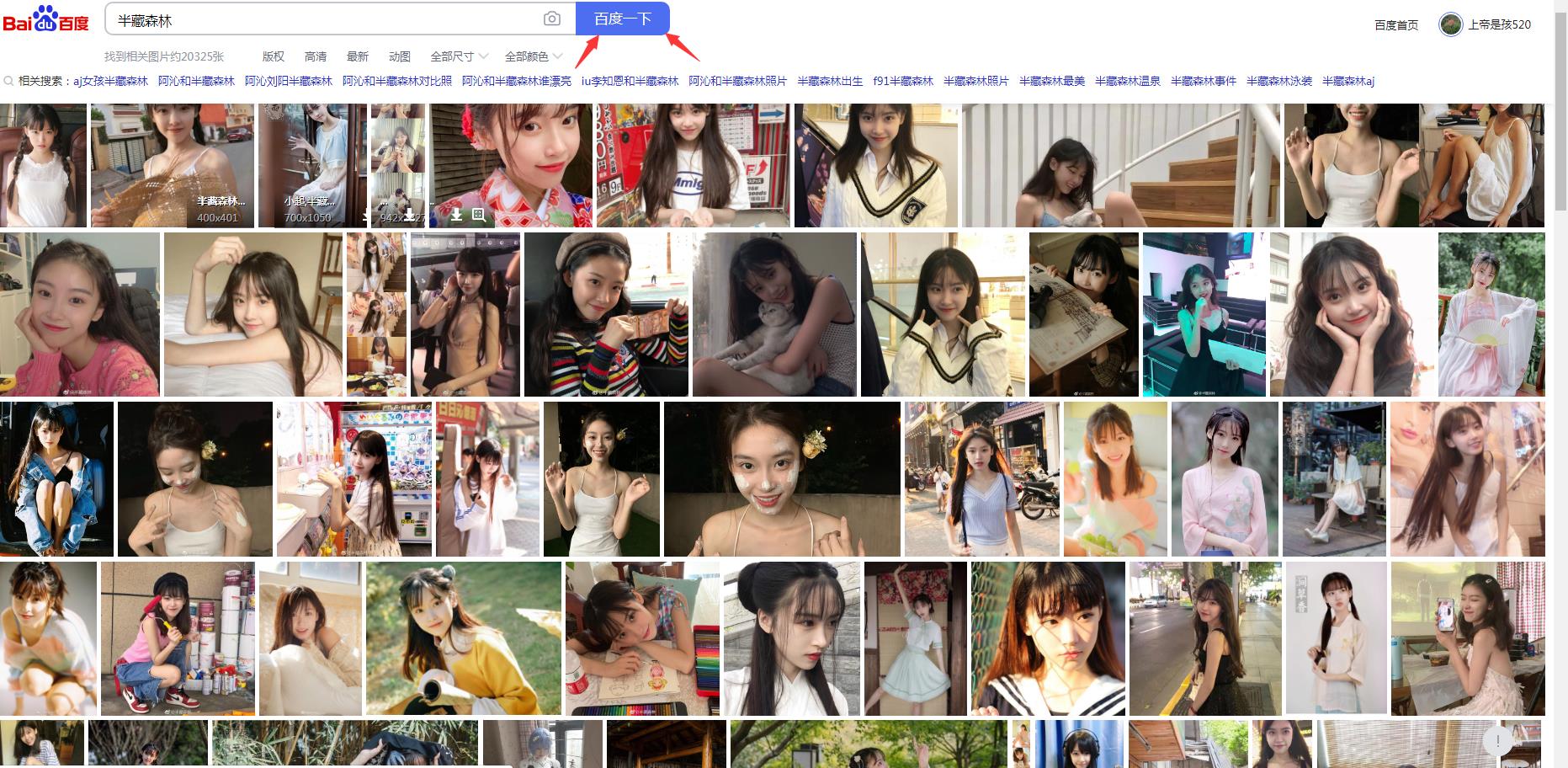
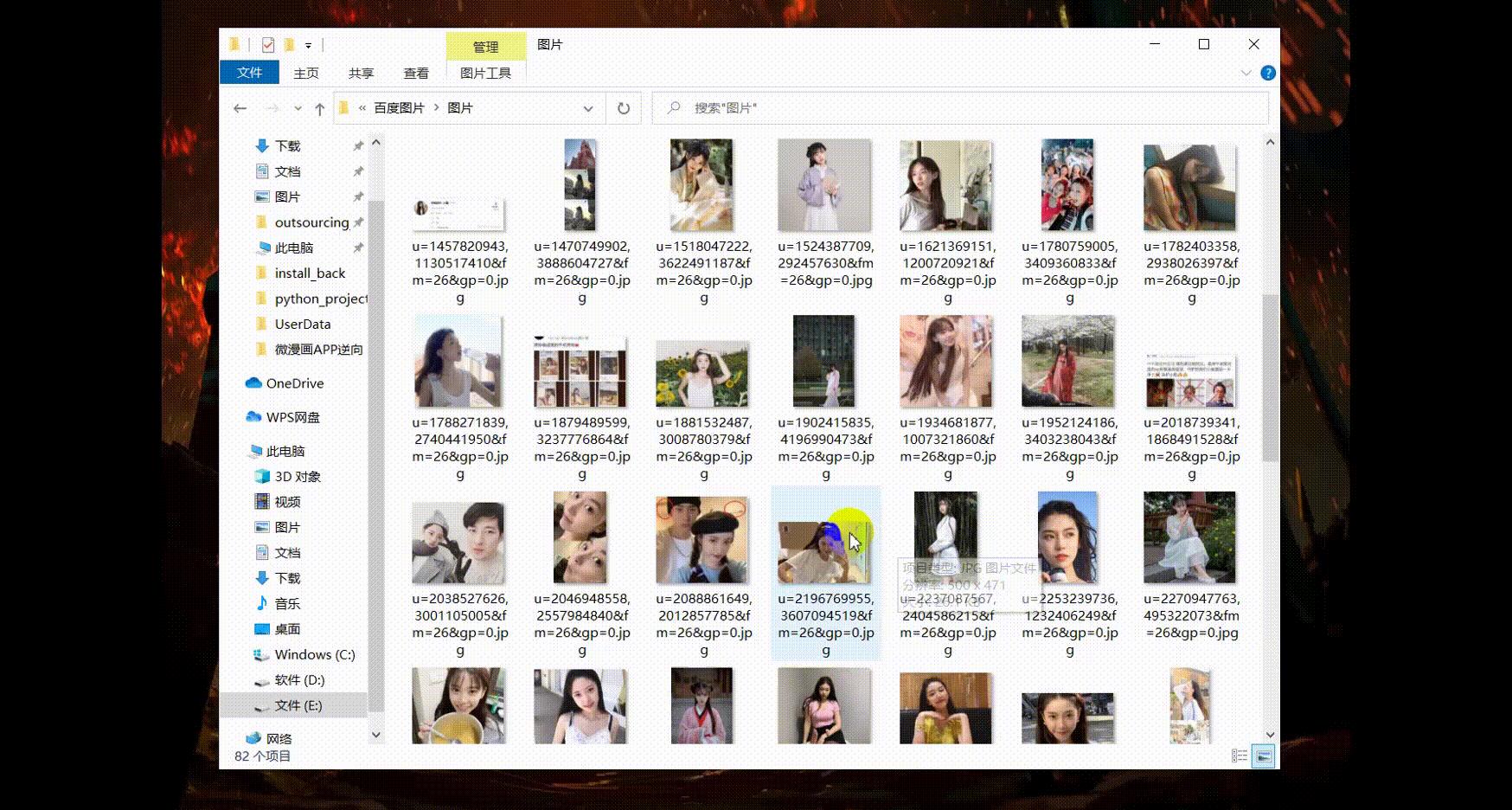
开发工具
开发环境: Python3.7 + win10
开发工具: pycharm + chrome
主要内容:
1.获取网址数据
2.正则提取数据
3.保存表格数据
项目解析
找到图片的动态数据接口
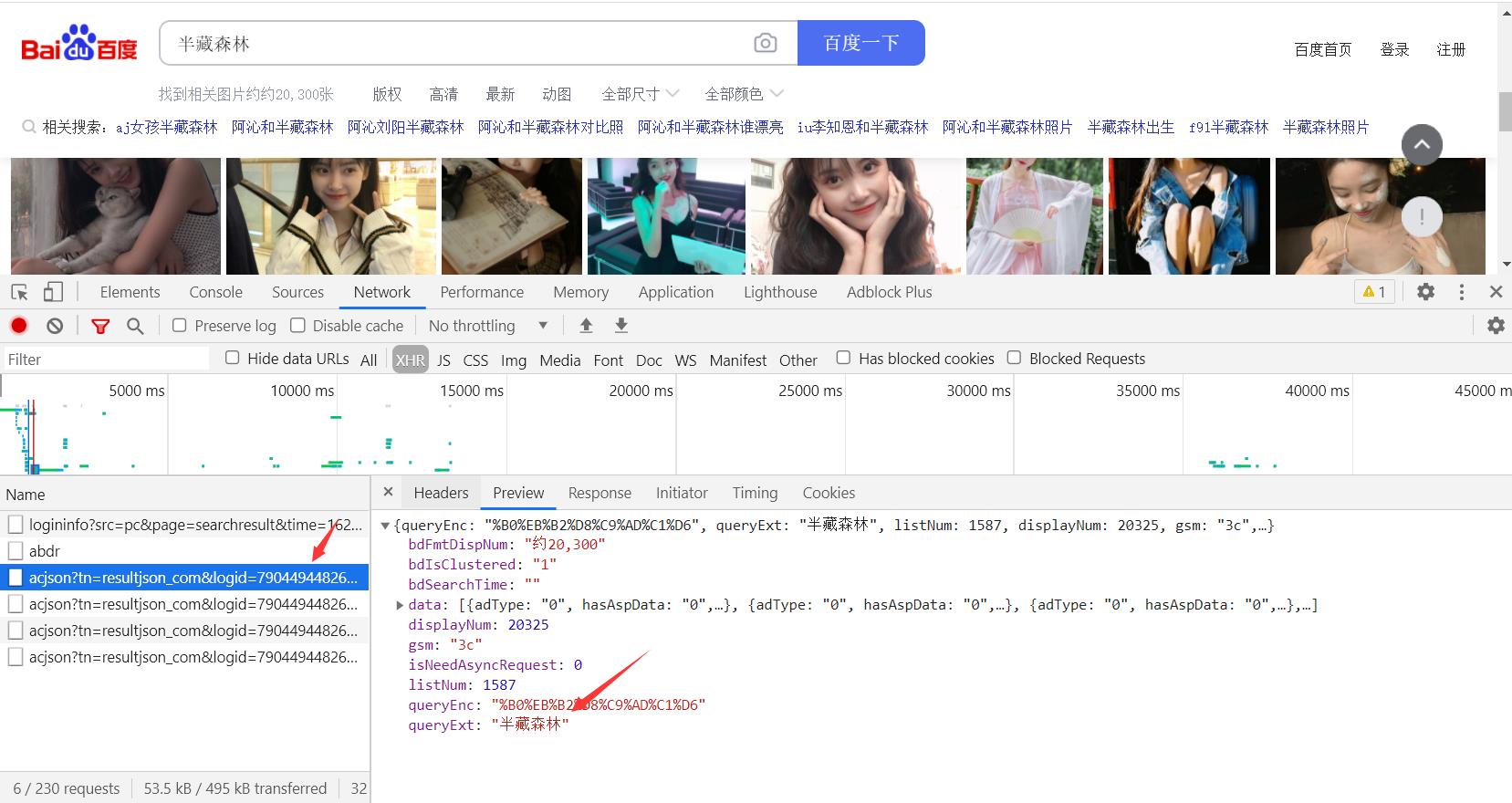
找到图片的url地址

请求当前动态的接口网址
提取图片的网址信息
再次对图片网址发送请求
保存数据
源码展示
import requests # 导入请求的工具包
import re # 正则匹配工具包
# 添加请求头
headers = {
# cookie信息
"Cookie": "BDqhfp=%E6%98%8E%E6%98%9F%E5%8D%95%E4%BA%BA%E7%85%A7%26%260-10-1undefined%26%261132%26%263; PSTM=1606885275; BAIDUID=D9B7A2A3C7555B9A30BC448DE032D13B:FG=1; BIDUPSID=5EEB8A912FC8FDCB0C187D519FABA455; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; BDSFRCVID=RxtOJeC62CaLjt3rvnJAhLqAYfS_AG3TH6ao5bUjY3stbaPxsXJ7EG0P8f8g0KubzcDrogKKLmOTHpKF_2uxOjjg8UtVJeC6EG0Ptf8g0f5; H_BDCLCKID_SF=tJPD_CLKtDI3fP36qRQtbt00qxby26nfa6T9aJ5nJDoNqIopb5bK54CkXM7rbxok3gQ3Lqo8QpP-HJ7zbxRqQhkD3NQXJU3p2erEKl0MLU7tbb0xynoDMbtNMfnMBMnramOnaPJc3fAKftnOM46JehL3346-35543bRTLnLy5KJYMDF4jj-hj5QLjaRf-b-X2CjyWb88Kb7VbUo95MnkbfJBD4bKWPTJt5rqWqcp2pRaEfTI0pnNQTt7yajK25QaQCQko-O2KJjmJ-Oyy6JpQT8reMDOK5OibCrE3hb-ab3vOpRzXpO1KMPzBN5thURB2DkO-4bCWJ5TMl5jDh3Mb6ksDMDtqtJHKbDDVILMJMK; BDUSS=g5U3pnMlhCRWJWT1lYQzR3SVBuSUN0MUNkWERaSDJHV2xKN3NHUDJzMFhGZTlmRUFBQUFBJCQAAAAAAAAAAAEAAAAIs6iyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABeIx18XiMdfRE; BDUSS_BFESS=g5U3pnMlhCRWJWT1lYQzR3SVBuSUN0MUNkWERaSDJHV2xKN3NHUDJzMFhGZTlmRUFBQUFBJCQAAAAAAAAAAAEAAAAIs6iyAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAABeIx18XiMdfRE; delPer=0; PSINO=6; __yjsv5_shitong=1.0_7_65901da49a5a59037e920cbd2020d5073dda_300_1606918958343_113.240.215.138_cdf8224b; H_PS_PSSID=1468_32855_33059_33098_33100_33199_33147_22160; BA_HECTOR=20050k2gakah8100r71fsguaf0q; BDRCVFR[X_XKQks0S63]=mk3SLVN4HKm; firstShowTip=1; cleanHistoryStatus=0; BDRCVFR[dG2JNJb_ajR]=mk3SLVN4HKm; userFrom=tupian.baidu.com; BDRCVFR[-pGxjrCMryR]=mk3SLVN4HKm; indexPageSugList=%5B%22%E6%98%8E%E6%98%9F%E5%8D%95%E4%BA%BA%E7%85%A7%22%2C%22%E6%98%8E%E6%98%9F%22%5D",
# 用户代理
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/70.0.3538.67 Safari/537.36",
# 请求数据来源
"Referer": "https://tupian.baidu.com/search/index",
"Host": "tupian.baidu.com"
}
key = input("请输入要下载的图片:")
# 保存图片的地址
path = r"E:\\\\python_project\\\\vip_course\\\\百度图片\\\\图片\\\\"
# 请求数据接口
for i in range(5, 50):
url = "https://tupian.baidu.com/search/acjson?tn=resultjson_com&logid=11528842549528169565&ipn=rj&ct=201326592&is=&fp=result&queryWord={}&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=-1&z=&ic=0&hd=&latest=©right=&word={}&s=&se=&tab=&width=&height=&face=0&istype=2&qc=&nc=1&fr=&expermode=&force=&pn={}&rn=30&gsm=78&1606974013784=".format(key, key, i*30)
# 发送请求
response = requests.get(url, headers=headers)
# 正则匹配数据
url_list = re.findall('"thumbURL":"(.*?)",', response.text)
print(url_list)
# 循环取出图片url 和 name
for new_url in url_list:
# 再次对图片发送请求
result = requests.get(new_url).content
# 分割网址获取图片名字
name = new_url.split("/")[-1]
print(name)
# 写入文件
with open(path + name, "wb")as f:
f.write(result)
①3000多本Python电子书有
②Python开发环境安装教程有
③Python400集自学视频有
④软件开发常用词汇有
⑤Python学习路线图有
⑥项目源码案例分享有
如果你用得到的话可以直接拿走,在我的QQ技术交流群里(纯技术交流和资源共享,广告勿入)可以自助拿走,群号是764406565。
以上是关于图片获取太麻烦?python爬虫实战:百度百万级图片采集的主要内容,如果未能解决你的问题,请参考以下文章