面试官:了解雪崩效应吗?了解Hystrix吗?怎么解决雪崩效应吗?(大型社死现场,教你运筹帷幄之中)
Posted IT挖掘机y
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官:了解雪崩效应吗?了解Hystrix吗?怎么解决雪崩效应吗?(大型社死现场,教你运筹帷幄之中)相关的知识,希望对你有一定的参考价值。
上篇我们模拟了高并发场景下,系统资源被耗尽导致其他接口访问非常之慢。至此,这篇给出了五种解决方案(当然这个是次要的,主要还是理解原理)
上篇地址:https://blog.csdn.net/Kevinnsm/article/details/117302197?spm=1001.2014.3001.5501
文章目录
一、雪崩效应是什么?
在微服务项目当中,服务之间的调用是错综复杂的,服务之间相互依赖;一旦某个服务发生了问题,那么将可能出现链式反应,导致整个系统崩溃,这就是所谓的雪崩效应
(大白话说就是A服务依赖(调用)B服务,B服务依赖C服务,一旦C服务出了问题,那么A、B服务将一直处于阻塞状态)

二、什么是Hystrix?
Hystrix是由Netflix开源的一个服务隔离组件,通过服务隔离来避免由于依赖延迟、异常,引起资源耗尽导致系统不可用的解决方案。
Hystrix地址:https://github.com/Netflix/Hystrix

三、Hystrix用来解决什么问题?
服务之间错综复杂的调用,如果某一个服务出现了问题,那么就会出现我们前面介绍的雪崩效应问题。而Hystrix为这个服务故障提供了一套解决方案。
例如:
1、请求缓存
2、请求合并
3、服务隔离
4、服务熔断
5、服务降级
当你回答到这,面试官估计会对你嘿嘿一笑,说:来做CTO吧

上篇我们模拟了高并发场景下,系统资源被耗尽导致其他接口访问非常慢。至此,这篇给出了五种解决方案
演示代码免费下载地址:https://download.csdn.net/download/Kevinnsm/19098746
四、雪崩效应的五大解决方案
1、请求缓存
Ⅰ、redis安装
此处为了方便,我直接在windows上进行快速安装
另外我也使用了Reids Desktop Manager(图形化界面),这个现在收费了,不过对于我们来说,肯定白嫖!

Ⅱ、代码配置
在consumer模块配置RedisConfig文件
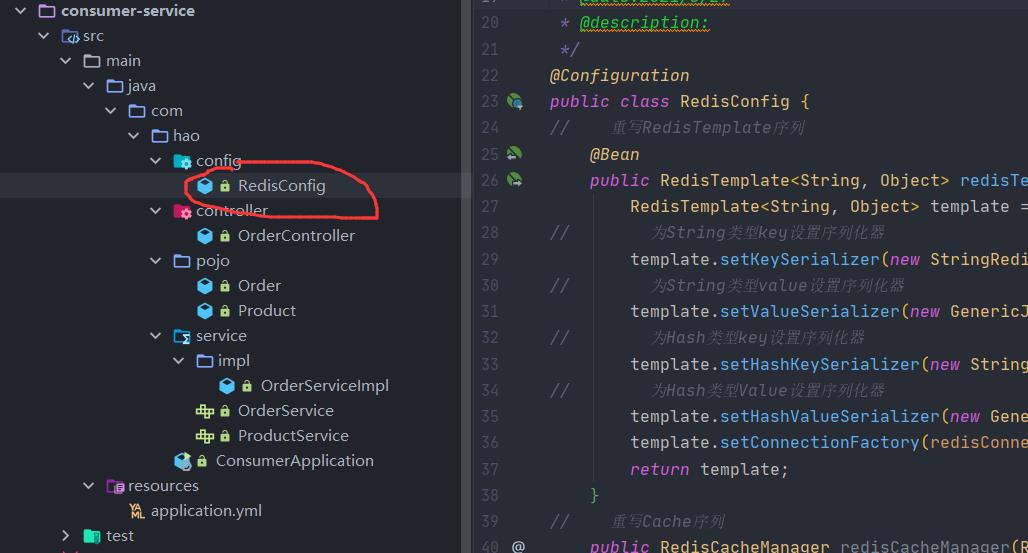
@Configuration
public class RedisConfig {
// 重写RedisTemplate序列
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 为String类型key设置序列化器
template.setKeySerializer(new StringRedisSerializer());
// 为String类型value设置序列化器
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
// 为Hash类型key设置序列化器
template.setHashKeySerializer(new StringRedisSerializer());
// 为Hash类型Value设置序列化器
template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
template.setConnectionFactory(redisConnectionFactory);
return template;
}
// 重写Cache序列
public RedisCacheManager redisCacheManager(RedisTemplate redisTemplate) {
RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisTemplate.getConnectionFactory());
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
// 设置默认时间为30秒
.entryTtl(Duration.ofMinutes(30))
// 设置key和value的序列化
.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(redisTemplate.getKeySerializer()))
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisTemplate.getValueSerializer()));
return new RedisCacheManager(redisCacheWriter, redisCacheConfiguration);
}
}
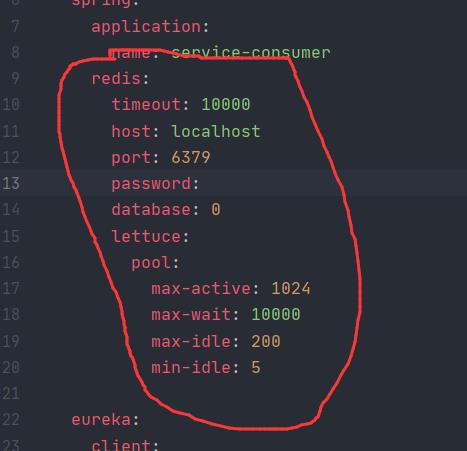
redis配置
在启动类上开启缓存
在远程调用接口上开启缓存配置(第一个接口和第三个接口)
具体不明白的可以参考上一篇
@FeignClient(value = "service-provider")
public interface ProductService {
@GetMapping(value = "/product/list")
@Cacheable(cacheNames = "orderService:product:list")
List<Product> selectProductList();
@GetMapping(value = "/product/byIds")
List<Product> selectProductListByIds(@RequestBody List<Integer> ids);
@GetMapping(value = "/search/{id}")
@Cacheable(cacheNames = "orderService:product:single", key = "#id")
Product selectProductById(@PathVariable("id") Integer id);
}
Ⅲ、启动测试接口
启动这四个服务访问http://localhost:9090/select/1
由于我们在第一个消费接口的服务提供类的接口处暂停了两秒,所以当我们访问时,第一次会耗时>2s,后面就会非常快了,因为从缓存读取了嘛!
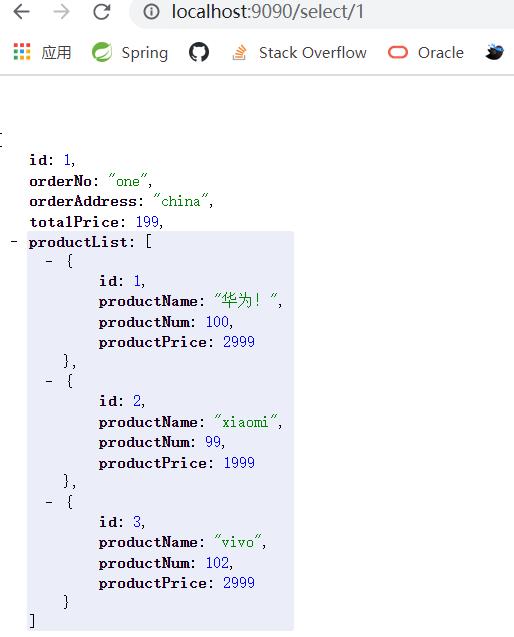
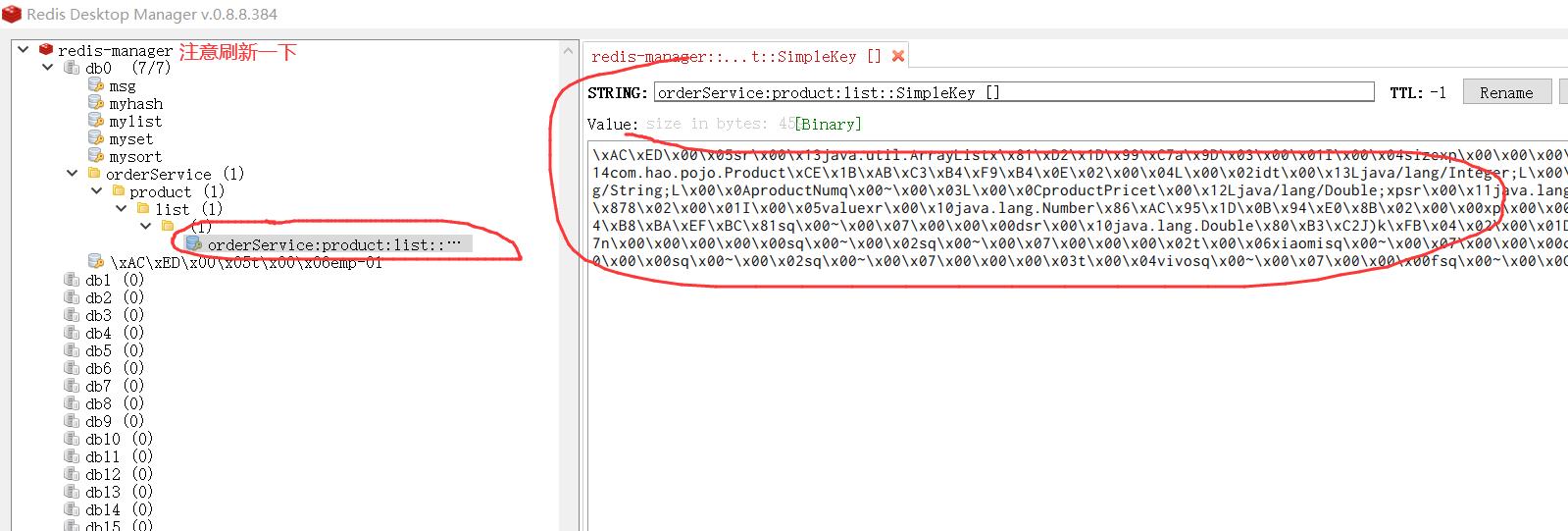
之后我们从RedisManager查看结果
Ⅳ、模拟2500访问量高并发测试
和上一篇操作一样:https://blog.csdn.net/Kevinnsm/article/details/117302197?spm=1001.2014.3001.5501
此时我们可以看到结果
为什么2500个请求很快就完成了呢?究其原因还是缓存的功劳嘛!一般情况下从第二个请求开始就一直从缓存中取的数据。虽然我暂停了两秒,但那和缓存没毛线关系(就第一次走那个路线)。
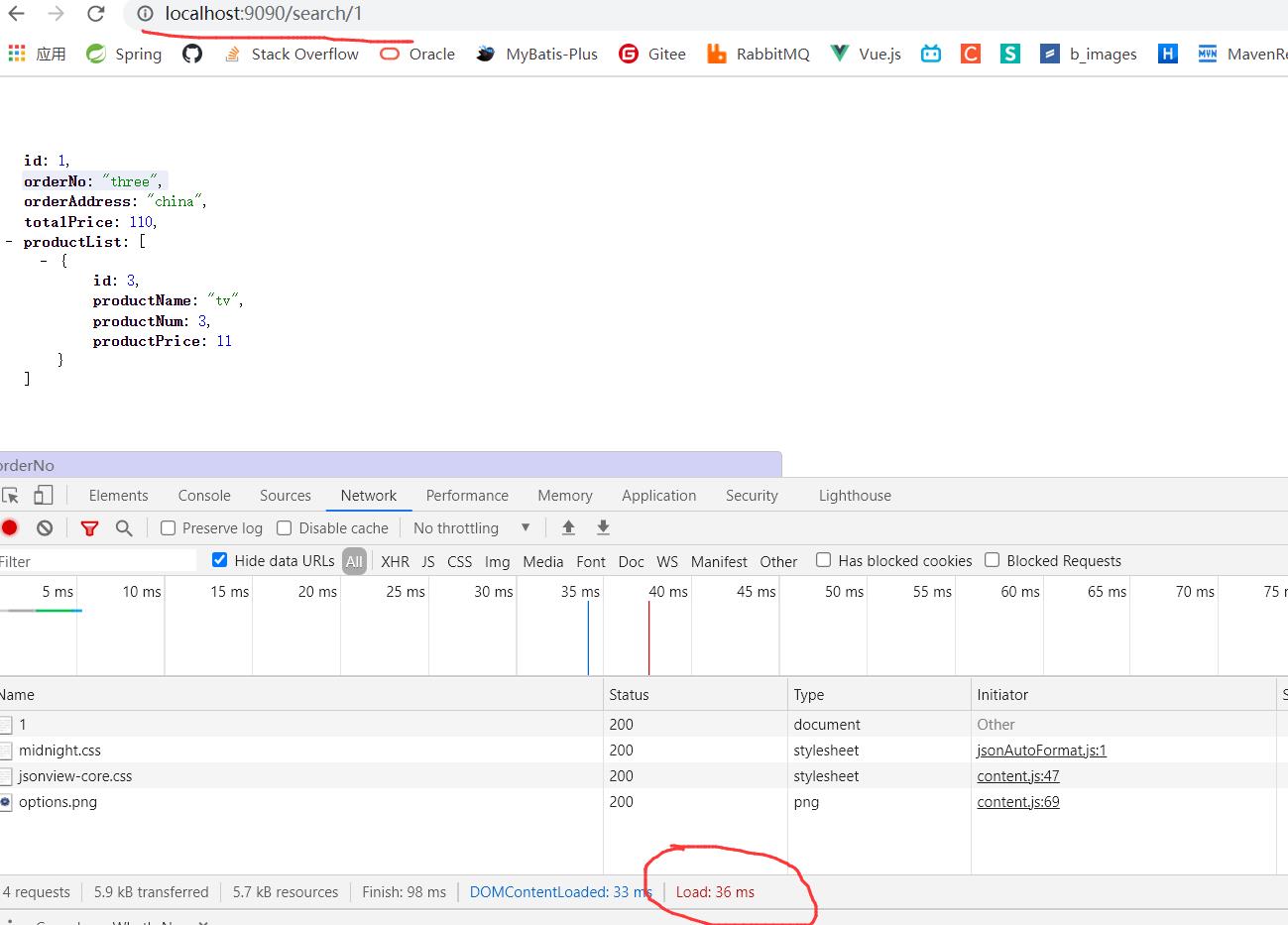
在那2500个请求的过程中,访问第三个接口,有可能2499个请求都找缓存去了,然后就不存在线程资源竞争嘛!当然就很快了
2、请求合并
什么是请求合并?
在高并发场景下,一个请求就需要一个线程进行处理;一旦访问量很大,那么就会浪费很多的资源;所以引入了请求合并,将多个请求进行拼接,只进行一次访问即可。
hystrix依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<version>2.2.8.RELEASE</version>
</dependency>
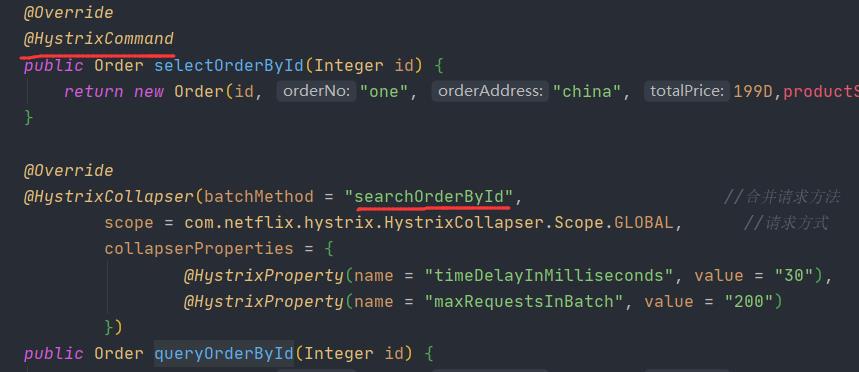
这两个注解配置一下即可
@HystrixCollapser(batchMethod = "searchOrderById", //合并请求方法
scope = com.netflix.hystrix.HystrixCollapser.Scope.GLOBAL, //请求方式
collapserProperties = {
//请求的最大等待时间 - 30s ,默认20s
@HystrixProperty(name = "timeDelayInMilliseconds", value = "30"),
//最多合并多少个请求 - 200个
@HystrixProperty(name = "maxRequestsInBatch", value = "200")
})
注意启动类上需要开启Hystrix熔断。
3、服务隔离
1、线程隔离
什么是线程隔离?
我们以前没有使用线程隔离的项目的所有接口都运行在一个ThreadPool中,一旦某一个接口压力过大就会造成资源耗尽,从而导致其他接口的正常使用;如使用了线程隔离技术,我们可以将某个实例接口单独使用ThreadPool隔离起来,一旦它出现故障,不会影响其他接口的使用,如下图详解两种方式
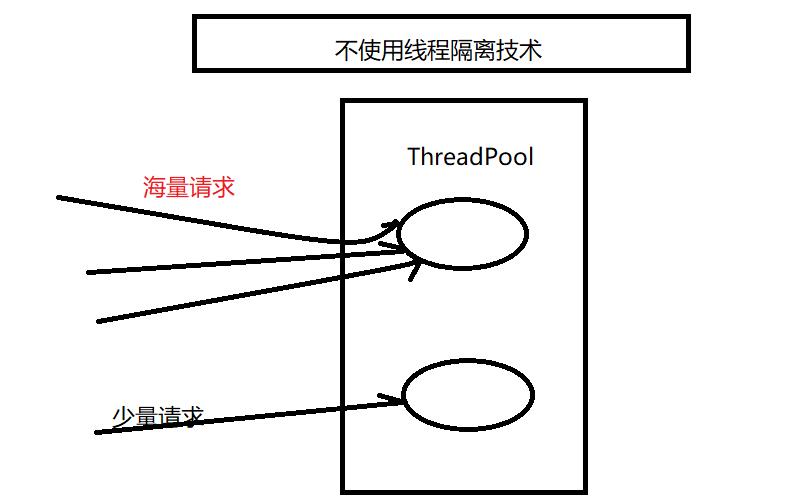
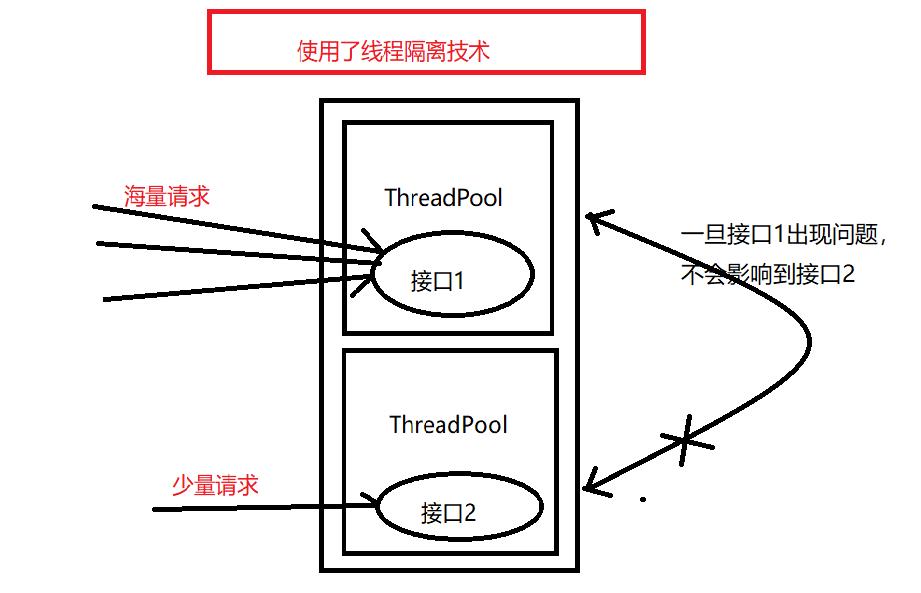
异步,提高了系统的并发性;但是如果隔离的实例过多,还是推荐使用这种方式
使用注解方式实现线程隔离,注解方式和配置方式各有优缺点
配置方式可以在服务在线时进行修改配置,但是一个实例需要一个配置类,一旦需要隔离较多的实例就要写很多类
注解方式虽然很方便,但是不能在服务在线时进行修改配置
@Service
public class OrderServiceImpl implements OrderService {
@Autowired
private ProductService productService;
@Override
@HystrixCommand(groupKey = "consumer-product-pool-1", //服务名称
commandKey = "selectOrderById", //接口名称,默认方法名
threadPoolKey = "consumer-product-pool-1", //线程池名称,相同名称使用一个线程此
commandProperties = {
//超时时间。默认1000ms
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",
value = "5000")
},
threadPoolProperties = {
//线程大小
@HystrixProperty(name = "coreSize", value = "6"),
//队列等待阈值
@HystrixProperty(name = "maxQueueSize", value = "100"),
//线程存活时间
@HystrixProperty(name = "keepAliveTimeMinutes", value = "30"),
//超出队列等待阈值执行拒绝策略
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "100")
})
public Order selectOrderById(Integer id) {
return new Order(id, "one", "china", 199D,productService.selectProductList());
}
private List<Product> selectProductListFallback() {
return Arrays.asList(
new Product(1, "默认数据1", 9, 100D),
new Product(2, "默认数据2", 15, 200D),
new Product(3, "默认数据3", 13, 300D)
);
}
@Override
public Order queryOrderById(Integer id) {
return new Order(id, "two", "nyist", 11D, productService.selectProductListByIds(Arrays.asList(1, 2)));
}
@Override
@HystrixCommand(groupKey = "consumer-product-pool-2", //服务名称
commandKey = "searchOrderById", //接口名称,默认方法名
threadPoolKey = "consumer-product-pool-1", //线程池名称,相同名称使用一个线程此
commandProperties = {
//超时时间。默认1000ms
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",
value = "5000")
},
threadPoolProperties = {
//线程大小
@HystrixProperty(name = "coreSize", value = "3"),
//队列等待阈值
@HystrixProperty(name = "maxQueueSize", value = "100"),
//线程存活时间
@HystrixProperty(name = "keepAliveTimeMinutes", value = "2"),
//超出队列等待阈值执行拒绝策略
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "100")
})
public Order searchOrderById(Integer id) {
return new Order(id, "three", "china", 110D, Arrays.asList(productService.selectProductById(3)));
}
}
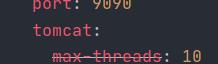
在tomcat进行配置系统最多只能使用10个线程,方便查看结果
使用JMeter进行测试
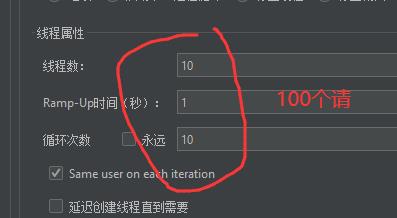
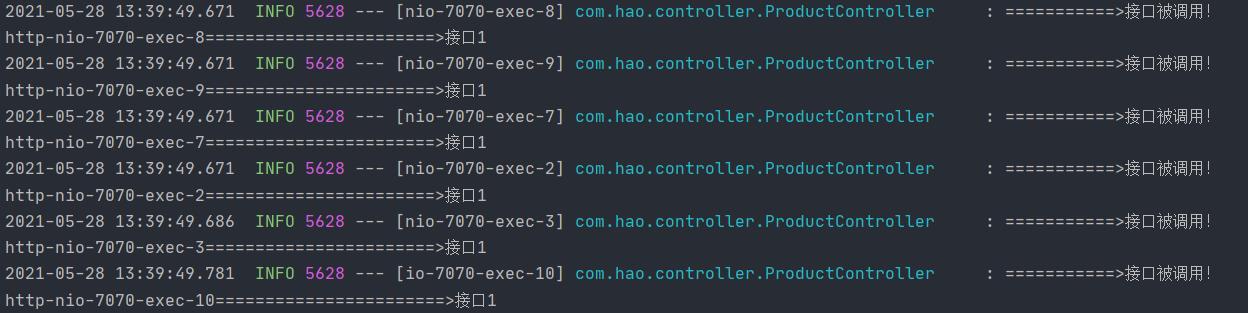
由于我在注解中配置了该接口每次只能使用6个线程进行处理,可以发现每次会打印6个日志。(我暂停两秒的那个接口)
2、信号量隔离
什么是信号量隔离?
信号量有一个大小,一旦请求的线程数超过了这个信号量的大小,直接获取失败做fallback处理。获取到信号量的线程继续访问,访问完成后归还信号量;当然可以通过上调信号量的大小,来提高系统的性能
同步调用,信号量是不能用于网络环境的;多用于本地环境。
@HystrixCommand(commandProperties = {
// 超时时间
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds",value = "5000"),
//信号量隔离
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_STRATEGY, value = "SEMAPHORE"),
//信号量最大并发
@HystrixProperty(name = HystrixPropertiesManager.EXECUTION_ISOLATION_SEMAPHORE_MAX_CONCURRENT_REQUESTS, value = "10")
})
public Order selectOrderById(Integer id) {
return new Order(id, "one", "china", 199D,productService.selectProductList());
}
4、服务熔断
为什么要进行服务熔断?
在微服务架构中,可能由于某种原因导致服务出现了过载现象,有可能引发整个系统发生故障;为防止这种情况发生引入服务熔断技术;可以将熔断理解为我们生活中的闸刀。
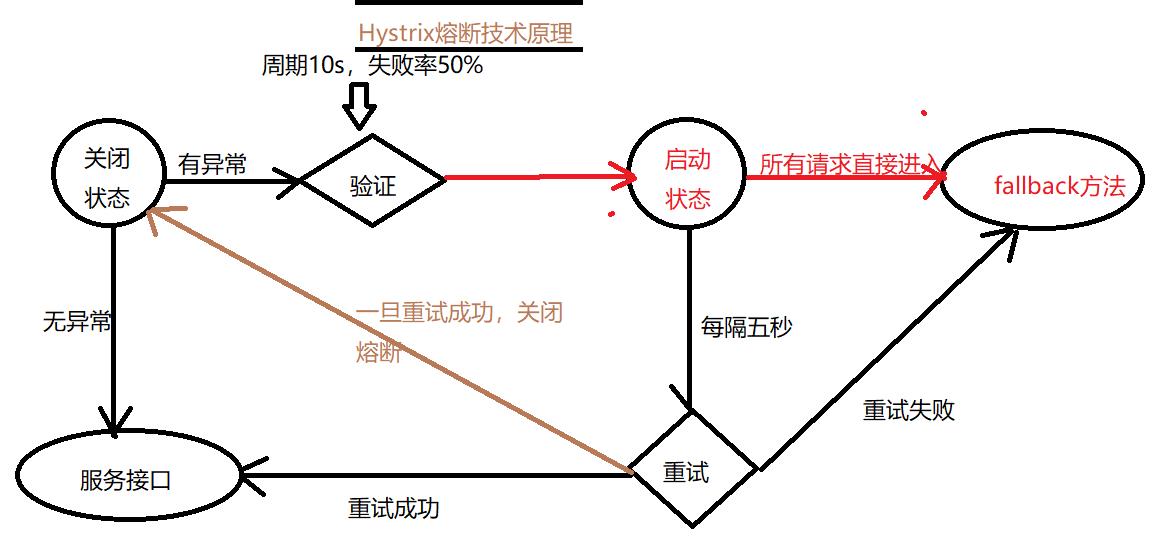
Hystrix熔断技术原理:
服务模块业务类代码
为了模拟服务熔断,我手动加入异常,使其开启熔断。
访问id=1,下面会报运行时异常,然后就会走fallback函数。
@HystrixCommand(commandProperties = {
//10s内请求大于10个就启动熔断器,默认20个
@HystrixProperty(name = HystrixPropertiesManager.CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD, value = "10"),
//请求错误率大于50%就启动熔断器
@HystrixProperty(name = HystrixPropertiesManager.CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE, value = "50"),
//熔断5s进行重试请求, 默认5s
@HystrixProperty(name = HystrixPropertiesManager.CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS, value = "5000")
},fallbackMethod = "selectProductListFallback")
public Order queryOrderById(Integer id) {
if (id ==1 )
throw new RuntimeException("id=1的信息异常,开始进行服务熔断处理!");
return new Order(id, "two", "nyist", 11D, productService.selectProductListByIds(Arrays.asList(1, 2)));
}
服务熔断异常执行函数fallback
private Order selectProductListFallback(Integer id) {
System.out.println("------------》调用了默认数据000《---------------");
return new Order(1, "系统故障,默认数据", "开启熔断", 11D, Arrays.asList(new Product(1,"vim", 2, 11D)));
}
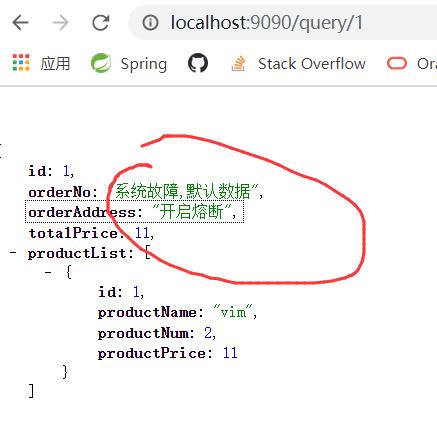
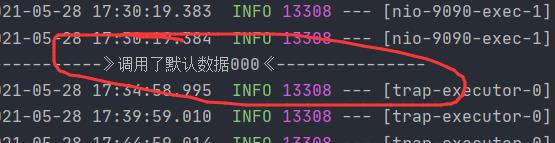
可以发现确实是走的fallback函数,服务熔断模拟成功!
5、服务降级
如何理解服务降级?
服务降级是为了保留核心业务,舍弃边缘业务。
@HystrixCommand(fallbackMethod = "selectProductListFallback")
进行服务降级只需添加这一行代码即可,前面服务熔断已经使用过。
有几种触发条件
1、发生异常
2、调用超时
3、超出服务隔离设置的上限
4、开启服务熔断
五、总结
到这里基本就结束了,这里讲述的都是基于Hystrix的雪崩解决方案,当然其他技术也能实现,比如Feign实现熔断降级等等。虽然Hystrix已经进入维护之中,但是这个组件真的香,我一直都认为学习不能什么热就学什么,为什么不去探究一下其中的奥妙呢?深入学习之后我发现

溜了溜了!

以上是关于面试官:了解雪崩效应吗?了解Hystrix吗?怎么解决雪崩效应吗?(大型社死现场,教你运筹帷幄之中)的主要内容,如果未能解决你的问题,请参考以下文章