分享给各位道友一份2021年征战蚂蚁金服头条拼多多的面试总结经验包
Posted java路人甲乙丙丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享给各位道友一份2021年征战蚂蚁金服头条拼多多的面试总结经验包相关的知识,希望对你有一定的参考价值。
文章有点长,请耐心看完,绝对有收获!不想听我BB直接进入面试分享:
-
准备过程
-
蚂蚁金服面试分享
-
拼多多面试分享
-
字节跳动面试分享
-
总结
说起来开始进行面试是上周二,上午9点,我还在去公司的公交上,突然收到蚂蚁的面试电话,其实算不上真正的面试。面试官只是和我聊了下他们在做的事情(主要是做6.18这里大促的稳定性保障,偏中间件吧),说的很详细,然后和我沟通了下是否有兴趣,我表示有兴趣,后面就收到正式面试的通知,最后没选择去蚂蚁表示抱歉。
当时我自己也准备出去看看机会,顺便看看自己的实力。当时我其实挺纠结的,一方面现在部门也正需要我,还是可以有一番作为的,另一方面觉得近一年来进步缓慢,没有以前飞速进步的成就感了,而且业务和技术偏于稳定,加上自己也属于那种比较懒散的人,骨子里还是希望能够突破现状,持续在技术上有所精进。
在开始正式的总结之前,还是希望各位同仁能否听我继续发泄一会,抱拳!
我翻开自己2021年初立的flag,觉得甚是惭愧。其中就有一条是保持一周写一篇博客,奈何中间因为各种原因没能坚持下去。细细想来,主要是自己没能真正静下来心认真投入到技术的研究和学习,那么为什么会这样?说白了还是因为没有确定目标或者目标不明确,没有目标或者目标不明确都可能导致行动的失败。
那么问题来了,目标是啥?就我而言,短期目标是深入研究某一项技术,比如最近在研究mysql,那么深入研究一定要动手实践并且有所产出,这就够了么?还需要我们能够举一反三,结合实际开发场景想一想日常开发要注意什么,这中间有没有什么坑?可以看出,要进步真的不是一件简单的事,这种反人类的行为需要我们克服自我的弱点,逐渐形成习惯。真正牛逼的人,从不觉得认真学习是一件多么难的事,因为这已经形成了他的习惯,就和早上起床刷牙洗脸那么自然简单。
扯了那么多,开始进入正题,先后进行了蚂蚁、拼多多和字节跳动的面试。
准备过程
先说说我自己的情况,我2018先在蚂蚁实习了将近三个月,然后去了我现在的老东家,2.5年工作经验,可以说毕业后就一直老老实实在老东家打怪升级,虽说有蚂蚁的实习经历,但是因为时间太短,还是有点虚的。所以面试官看到我简历第一个问题绝对是这样的。
“哇,你在蚂蚁待过,不错啊”,面试官笑嘻嘻地问到。“是的,还好”,我说。“为啥才三个月?”,面试官脸色一沉问到。“哗啦啦解释一通。。。”,我解释道。“哦,原来如此,那我们开始面试吧”,面试官一本正经说到。
尼玛,早知道不写蚂蚁的实习经历了,后面仔细一想,当初写上蚂蚁不就给简历加点料嘛。
言归正传,准备过程其实很早开始了(当然这不是说我工作时老想着跳槽,因为我明白现在的老东家并不是终点,我还需要不断提升),具体可追溯到从蚂蚁离职的时候,当时出来也面了很多公司,没啥大公司,面了大概5家公司,都拿到offer了。
工作之余常常会去额外研究自己感兴趣的技术以及工作用到的技术,力求把原理搞明白,并且会自己实践一把。此外,买了N多书,基本有时间就会去看,补补基础,什么操作系统、数据结构与算法、MySQL、JDK之类的源码,基本都好好温习了(文末会列一下自己看过的书和一些好的资料)。我深知基础就像“木桶效应”的短板,决定了能装多少水。
此外,在正式决定看机会之前,我给自己列了一个提纲,主要包括Java要掌握的核心要点,有不懂的就查资料搞懂。我给自己定位还是Java工程师,所以Java体系是一定要做到心中有数的,很多东西没有常年的积累面试的时候很容易露馅,学习要对得起自己,不要骗人。
剩下的就是找平台和内推了,除了蚂蚁,头条和拼多多都是找人内推的,感谢蚂蚁面试官对我的欣赏,以后说不定会去蚂蚁咯。
平台:脉脉、GitHub、v2
蚂蚁金服

一面
一面就做了一道算法题,要求两小时内完成,给了长度为N的有重复元素的数组,要求输出第10大的数。典型的TopK问题,快排算法搞定。
算法题要注意的是合法性校验、边界条件以及异常的处理。另外,如果要写测试用例,一定要保证测试覆盖场景尽可能全。加上平时刷刷算法题,这种考核应该没问题的。
二面
-
自我介绍下呗
-
开源项目贡献过代码么?(Dubbo提过一个打印accesslog的bug算么)
-
目前在部门做什么,业务简单介绍下,内部有哪些系统,作用和交互过程说下
-
Dubbo踩过哪些坑,分别是怎么解决的?(说了异常处理时业务异常捕获的问题,自定义了一个异常拦截器)
-
开始进入正题,说下你对线程安全的理解(多线程访问同一个对象,如果不需要考虑额外的同步,调用对象的行为就可以获得正确的结果就是线程安全)
-
事务有哪些特性?(ACID)
-
怎么理解原子性?(同一个事务下,多个操作要么成功要么失败,不存在部分成功或者部分失败的情况)
-
乐观锁和悲观锁的区别?(悲观锁假定会发生冲突,访问的时候都要先获得锁,保证同一个时刻只有线程获得锁,读读也会阻塞;乐观锁假设不会发生冲突,只有在提交操作的时候检查是否有冲突)这两种锁在Java和MySQL分别是怎么实现的?(Java乐观锁通过CAS实现,悲观锁通过synchronize实现。mysql乐观锁通过MVCC,也就是版本实现,悲观锁可以通过select... for update加上排它锁)
-
HashMap为什么不是线程安全的?(多线程操作无并发控制,顺便说了在扩容的时候多线程访问时会造成死锁,会形成一个环,不过扩容时多线程操作形成环的问题再JDK1.8已经解决,但多线程下使用HashMap还会有一些其他问题比如数据丢失,所以多线程下不应该使用HashMap,而应该使用ConcurrentHashMap)怎么让HashMap变得线程安全?(Collections的synchronize方法包装一个线程安全的Map,或者直接用ConcurrentHashMap)两者的区别是什么?(前者直接在put和get方法加了synchronize同步,后者采用了分段锁以及CAS支持更高的并发)
-
jdk1.8对ConcurrentHashMap做了哪些优化?(插入的时候如果数组元素使用了红黑树,取消了分段锁设计,synchronize替代了Lock锁)为什么这样优化?(避免冲突严重时链表多长,提高查询效率,时间复杂度从O(N)提高到O(logN))
-
redis主从机制了解么?怎么实现的?
-
有过GC调优的经历么?(有点虚,答得不是很好)
-
有什么想问的么?
三面
-
简单自我介绍下
-
监控系统怎么做的,分为哪些模块,模块之间怎么交互的?用的什么数据库?(MySQL)使用什么存储引擎,为什么使用InnnoDB?(支持事务、聚簇索引、MVCC)
-
订单表有做拆分么,怎么拆的?(垂直拆分和水平拆分)
-
水平拆分后查询过程描述下
-
如果落到某个分片的数据很大怎么办?(按照某种规则,比如哈希取模、range,将单张表拆分为多张表)
-
哈希取模会有什么问题么?(有的,数据分布不均,扩容缩容相对复杂 )
-
分库分表后怎么解决读写压力?(一主多从、多主多从)
-
拆分后主键怎么保证惟一?(UUID、Snowflake算法)
-
Snowflake生成的ID是全局递增唯一么?(不是,只是全局唯一,单机递增)
-
怎么实现全局递增的唯一ID?(讲了TDDL的一次取一批ID,然后再本地慢慢分配的做法)
-
Mysql的索引结构说下(说了B+树,B+树可以对叶子结点顺序查找,因为叶子结点存放了数据结点且有序)
-
主键索引和普通索引的区别(主键索引的叶子结点存放了整行记录,普通索引的叶子结点存放了主键ID,查询的时候需要做一次回表查询)一定要回表查询么?(不一定,当查询的字段刚好是索引的字段或者索引的一部分,就可以不用回表,这也是索引覆盖的原理)
-
你们系统目前的瓶颈在哪里?
-
你打算怎么优化?简要说下你的优化思路
-
有什么想问我么?
四面
-
介绍下自己
-
为什么要做逆向?
-
怎么理解微服务?
-
服务治理怎么实现的?(说了限流、压测、监控等模块的实现)
-
这个不是中间件做的事么,为什么你们部门做?(当时没有单独的中间件团队,微服务刚搞不久,需要进行监控和性能优化)
-
说说Spring的生命周期吧
-
说说GC的过程(说了young gc和full gc的触发条件和回收过程以及对象创建的过程)
-
CMS GC有什么问题?(并发清除算法,浮动垃圾,短暂停顿)
-
怎么避免产生浮动垃圾?(记得有个VM参数设置可以让扫描新生代之前进行一次young gc,但是因为gc是虚拟机自动调度的,所以不保证一定执行。但是还有参数可以让虚拟机强制执行一次young gc)
-
强制young gc会有什么问题?(STW停顿时间变长)
-
知道G1么?(了解一点 )
-
回收过程是怎么样的?(young gc、并发阶段、混合阶段、full gc,说了Remember Set)
-
你提到的Remember Set底层是怎么实现的?
-
有什么想问的么?
五面
五面是HRBP面的,和我提前预约了时间,主要聊了之前在蚂蚁的实习经历、部门在做的事情、职业发展、福利待遇等。阿里面试官确实是具有一票否决权的,很看重你的价值观是否match,一般都比较喜欢皮实的候选人。HR面一定要诚实,不要说谎,只要你说谎HR都会去证实,直接cut了。
-
之前蚂蚁实习三个月怎么不留下来?
-
实习的时候主管是谁?
-
实习做了哪些事情?(尼玛这种也问?)
-
你对技术怎么看?平时使用什么技术栈?(阿里HR真的是既当爹又当妈,)
-
最近有在研究什么东西么
-
你对SRE怎么看
-
对待遇有什么预期么
最后HR还对我说目前稳定性保障部挺缺人的,希望我尽快回复。
小结
蚂蚁面试比较重视基础,所以Java那些基本功一定要扎实。蚂蚁的工作环境还是挺赞的,因为我面的是稳定性保障部门,还有许多单独的小组,什么三年1班,很有青春的感觉。面试官基本水平都比较高,基本都P7以上,除了基础还问了不少架构设计方面的问题,收获还是挺大的。
拼多多

面试前
面完蚂蚁后,早就听闻拼多多这个独角兽,决定也去面一把。首先我在脉脉找了一个拼多多的HR,加了微信聊了下,发了简历便开始我的拼多多面试之旅。这里要非常感谢拼多多HR小姐姐,从面试内推到offer确认一直都在帮我,人真的很nice。
一面
-
为啥蚂蚁只待了三个月?没转正?(转正了,解释了一通。。。)
-
Java中的HashMap、TreeMap解释下?(TreeMap红黑树,有序,HashMap无序,数组+链表)
-
TreeMap查询写入的时间复杂度多少?(O(logN))
-
HashMap多线程有什么问题?(线程安全,死锁)怎么解决?( jdk1.8用了synchronize + CAS,扩容的时候通过CAS检查是否有修改,是则重试)重试会有什么问题么?(CAS(Compare And Swap)是比较和交换,不会导致线程阻塞,但是因为重试是通过自旋实现的,所以仍然会占用CPU时间,还有ABA的问题)怎么解决?(超时,限定自旋的次数,ABA可以通过原理变量AtomicStampedReference解决,原理利用版本号进行比较)超过重试次数如果仍然失败怎么办?(synchronize互斥锁)
-
CAS和synchronize有什么区别?都用synchronize不行么?(CAS是乐观锁,不需要阻塞,硬件级别实现的原子性;synchronize会阻塞,JVM级别实现的原子性。使用场景不同,线程冲突严重时CAS会造成CPU压力过大,导致吞吐量下降,synchronize的原理是先自旋然后阻塞,线程冲突严重仍然有较高的吞吐量,因为线程都被阻塞了,不会占用CPU )
-
如果要保证线程安全怎么办?(ConcurrentHashMap)
-
ConcurrentHashMap怎么实现线程安全的?(分段锁)
-
get需要加锁么,为什么?(不用,volatile关键字)
-
volatile的作用是什么?(保证内存可见性)
-
底层怎么实现的?(说了主内存和工作内存,读写内存屏障,happen-before,并在纸上画了线程交互图)
-
在多核CPU下,可见性怎么保证?(思考了一会,总线嗅探技术)
-
聊项目,系统之间是怎么交互的?
-
系统并发多少,怎么优化?
-
给我一张纸,画了一个九方格,都填了数字,给一个MN矩阵,从1开始逆时针打印这MN个数,要求时间复杂度尽可能低(内心OS:之前貌似碰到过这题,最优解是怎么实现来着)思考中。。。
-
可以先说下你的思路(想起来了,说了什么时候要变换方向的条件,向右、向下、向左、向上,依此循环)
-
有什么想问我的?
二面
-
自我介绍下
-
手上还有其他offer么?(拿了蚂蚁的offer)
-
部门组织结构是怎样的?(这轮不是技术面么,不过还是老老实实说了)
-
系统有哪些模块,每个模块用了哪些技术,数据怎么流转的?(面试官有点秃顶,一看级别就很高)给了我一张纸,我在上面简单画了下系统之间的流转情况
-
链路追踪的信息是怎么传递的?(RpcContext的attachment,说了Span的结构:parentSpanId + curSpanId)
-
SpanId怎么保证唯一性?(UUID,说了下内部的定制改动)
-
RpcContext是在什么维度传递的?(线程)
-
Dubbo的远程调用怎么实现的?(讲了读取配置、拼装url、创建Invoker、服务导出、服务注册以及消费者通过动态代理、filter、获取Invoker列表、负载均衡等过程(哗啦啦讲了10多分钟),我可以喝口水么)
-
Spring的单例是怎么实现的?(单例注册表)
-
为什么要单独实现一个服务治理框架?(说了下内部刚搞微服务不久,主要对服务进行一些监控和性能优化)
-
谁主导的?内部还在使用么?
-
逆向有想过怎么做成通用么?
-
有什么想问的么?
三面
二面老大面完后就直接HR面了,主要问了些职业发展、是否有其他offer、以及入职意向等问题,顺便说了下公司的福利待遇等,都比较常规啦。不过要说的是手上有其他offer或者大厂经历会有一定加分。
小结
拼多多的面试流程就简单许多,毕竟是一个成立六年多的公司。面试难度中规中矩,只要基础扎实应该不是问题。但不得不说工作强度很大,开始面试前HR就提前和我确认能否接受这样强度的工作,想来的老铁还是要做好准备
字节跳动

面试前
头条的面试是三家里最专业的,每次面试前有专门的HR和你约时间,确定OK后再进行面试。每次都是通过视频面试,因为都是之前都是电话面或现场面,所以视频面试还是有点不自然。也有人觉得视频面试体验很赞,当然萝卜青菜各有所爱。最坑的二面的时候对方面试官的网络老是掉线,最后很冤枉的挂了(当然有一些点答得不好也是原因之一)。所以还是有点遗憾的。
一面
-
先自我介绍下
-
聊项目,逆向系统是什么意思
-
聊项目,逆向系统用了哪些技术
-
线程池的线程数怎么确定?
-
如果是IO操作为主怎么确定?
-
如果计算型操作又怎么确定?
-
Redis熟悉么,了解哪些数据结构?(说了zset) zset底层怎么实现的?(跳表)
-
跳表的查询过程是怎么样的,查询和插入的时间复杂度?(说了先从第一层查找,不满足就下沉到第二层找,因为每一层都是有序的,写入和插入的时间复杂度都是O(logN))
-
红黑树了解么,时间复杂度?(说了是N叉平衡树,O(logN))
-
既然两个数据结构时间复杂度都是O(logN),zset为什么不用红黑树(跳表实现简单,踩坑成本低,红黑树每次插入都要通过旋转以维持平衡,实现复杂)
-
点了点头,说下Dubbo的原理?(说了服务注册与发布以及消费者调用的过程)踩过什么坑没有?(说了dubbo异常处理的和打印accesslog的问题)
-
CAS了解么?(说了CAS的实现)还了解其他同步机制么?(说了synchronize以及两者的区别,一个乐观锁,一个悲观锁)
-
那我们做一道题吧,数组A,2*n个元素,n个奇数、n个偶数,设计一个算法,使得数组奇数下标位置放置的都是奇数,偶数下标位置放置的都是偶数
-
先说下你的思路(从0下标开始遍历,如果是奇数下标判断该元素是否奇数,是则跳过,否则从该位置寻找下一个奇数)
-
下一个奇数?怎么找?(有点懵逼,思考中。。)
-
有思路么?(仍然是先遍历一次数组,并对下标进行判断,如果下标属性和该位置元素不匹配从当前下标的下一个遍历数组元素,然后替换)
-
你这样时间复杂度有点高,如果要求O(N)要怎么做(思考一会,答道“定义两个指针,分别从下标0和1开始遍历,遇见奇数位是是偶数和偶数位是奇数就停下,交换内容”)
-
时间差不多了,先到这吧。你有什么想问我的?
二面
-
面试官和蔼很多,你先介绍下自己吧
-
你对服务治理怎么理解的?
-
项目中的限流怎么实现的?(Guava ratelimiter,令牌桶算法)
-
具体怎么实现的?(要点是固定速率且令牌数有限)
-
如果突然很多线程同时请求令牌,有什么问题?(导致很多请求积压,线程阻塞)
-
怎么解决呢?(可以把积压的请求放到消息队列,然后异步处理)
-
如果不用消息队列怎么解决?(说了RateLimiter预消费的策略)
-
分布式追踪的上下文是怎么存储和传递的?(ThreadLocal + spanId,当前节点的spanId作为下个节点的父spanId)
-
Dubbo的RpcContext是怎么传递的?(ThreadLocal)主线程的ThreadLocal怎么传递到线程池?(说了先在主线程通过ThreadLocal的get方法拿到上下文信息,在线程池创建新的ThreadLocal并把之前获取的上下文信息设置到ThreadLocal中。这里要注意的线程池创建的ThreadLocal要在finally中手动remove,不然会有内存泄漏的问题)
-
你说的内存泄漏具体是怎么产生的?(说了ThreadLocal的结构,主要分两种场景:主线程仍然对ThreadLocal有引用和主线程不存在对ThreadLocal的引用。第一种场景因为主线程仍然在运行,所以还是有对ThreadLocal的引用,那么ThreadLocal变量的引用和value是不会被回收的。第二种场景虽然主线程不存在对ThreadLocal的引用,且该引用是弱引用,所以会在gc的时候被回收,但是对用的value不是弱引用,不会被内存回收,仍然会造成内存泄漏)
-
线程池的线程是不是必须手动remove才可以回收value?(是的,因为线程池的核心线程是一直存在的,如果不清理,那么核心线程的threadLocals变量会一直持有ThreadLocal变量)
-
那你说的内存泄漏是指主线程还是线程池?(主线程 )
-
可是主线程不是都退出了,引用的对象不应该会主动回收么?(面试官和内存泄漏杠上了),沉默了一会。。。
-
那你说下SpringMVC不同用户登录的信息怎么保证线程安全的?(刚才解释的有点懵逼,一下没反应过来,居然回答成锁了。大脑有点晕了,此时已经一个小时过去了,感觉情况不妙。。。)
-
这个直接用ThreadLocal不就可以么,你见过SpringMVC有锁实现的代码么?(有点晕菜。。。)
-
我们聊聊mysql吧,说下索引结构(说了B+树)
-
为什么使用B+树?( 说了查询效率高,O(logN),可以充分利用磁盘预读的特性,多叉树,深度小,叶子结点有序且存储数据)
-
什么是索引覆盖?(忘记了。。。)
-
Java为什么要设计双亲委派模型?
-
什么时候需要自定义类加载器?
-
我们做一道题吧,手写一个对象池
-
有什么想问我的么?(感觉我很多点都没答好,是不是挂了(结果真的是) )
小结
头条的面试确实很专业,每次面试官会提前给你发一个视频链接,然后准点开始面试,而且考察的点都比较全。
面试官都有一个特点,会抓住一个值得深入的点或者你没说清楚的点深入下去直到你把这个点讲清楚,不然面试官会觉得你并没有真正理解。二面面试官给了我一点建议,研究技术的时候一定要去研究产生的背景,弄明白在什么场景解决什么特定的问题,其实很多技术内部都是相通的。很诚恳,还是很感谢这位面试官大大。
总结
从4月开始面试到头条面完大概一个多月的时间,真的有点身心俱疲的感觉。最后拿到了拼多多、蚂蚁的offer,还是蛮幸运的。头条的面试对我帮助很大,再次感谢面试官对我的诚恳建议,以及拼多多的HR对我的啰嗦的问题详细解答。
这里要说的是面试前要做好两件事:简历和自我介绍,简历要好好回顾下自己做的一些项目,然后挑几个亮点项目。自我介绍基本每轮面试都有,所以最好提前自己练习下,想好要讲哪些东西,分别怎么讲。此外,简历提到的技术一定是自己深入研究过的,没有深入研究也最好找点资料预热下,不打无准备的仗。
这些年看过的书:
《Effective Java》、《现代操作系统》、《TCP/IP详解:卷一》、《代码整洁之道》、《重构》、《Java程序性能优化》、《Spring实战》、《Zookeeper》、《高性能MySQL》、《亿级网站架构核心技术》、《可伸缩服务架构》、《Java编程思想》
说实话这些书很多只看了一部分,我通常会带着问题看书,不然看着看着就睡着了,简直是催眠良药。
最后,附一张面试前准备的脑图:一键三连(点赞+收藏+关注)后直接添加微信:mxh5261 即可免费获取
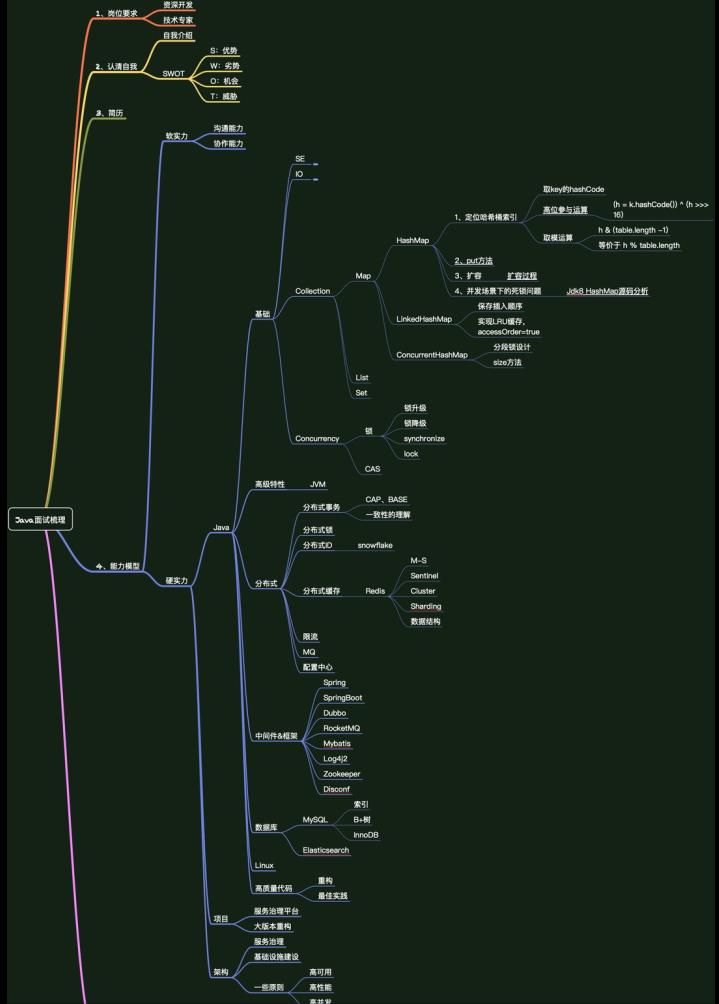
还有更多架构资源,以及面试专题。
由于篇幅限制,就不一一展示了,有需要文中以上分享的全部面试题+脑图的完整版的小伙伴们注意啦:一键三连(点赞+收藏+关注)后直接添加微信:mxh5261 即可百分百免费获取
以上是关于分享给各位道友一份2021年征战蚂蚁金服头条拼多多的面试总结经验包的主要内容,如果未能解决你的问题,请参考以下文章
GitHub 最新蹿火! 蚂蚁金服,拼多多 , 百度面经分享
分享给各位道友,在春招斩获中京东/拼多多/华为/阿里Java岗offer的究极面经