G1垃圾收集器深度剖析
Posted inet_ygssoftware
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了G1垃圾收集器深度剖析相关的知识,希望对你有一定的参考价值。
G1垃圾收集器深度剖析
一、G1垃圾收集器概述
1.1 思考
开始学习前,抛出两个常见面试问题:1.G1的回收原理是什么?为什么G1比传统的GC回收性能好?2.为什么G1如此完美仍然会有ZGC?简单的回顾下CMS垃圾回收机制,下面介绍了一个极端的场景(而且是经常发生的) 在发生Minor GC时,由于Survivor区已经放不下了,多出的对象只能提升(Promotion)到老年代。但是此时老年代因为空间碎片的缘故,会发生Concurrent mode failure的错误。这个时候,就需要降级为Serial Old垃圾回收器进行收集。这就是比concurrent mode failure 更加严重的promotion failed的问题。一个简单的Minor,竟然能演化成耗时最长的Full GC。最要命的是,这个停顿时间是不可预知的。有没有一种方法,能够首先定义一个停顿时间,然后反向推算收集内容呢?就像是领导在年初制定KPI一样,分配的任务多久多干些,任务少就少干点。类似需要徒步一段很长的路,然后在路中有多个里程碑,到达一个后可以休息一会。G1的思路说起来类似,它不要求每次都把垃圾清理的干干净净,只是努力做它认为对的事情。我们要求G1,在任意1秒的时间内,停顿不得超过10ms,这就是在给它制定KPI。G1会尽量达成这个目标,它能够推算出本次要收集的大体区域,以增量的方式完成收集。这也是使用G1垃圾回收器不得不设置的一个参数:-XX:MaxGCPauseMilis=10
1.2 简介
G1(Garbage First)垃圾收集器是当今垃圾回收技术最前沿的成果之一。早在JDK7就已加入JVM的收集器大家庭中,成为HotSpot重点发展的垃圾回收技术。同优秀的CMS垃圾回收器一样,G1也是关注最小时延的垃圾回收器,也同样适合大尺寸堆内存的垃圾收集,官方也推荐使用G1来代替选择CMS。G1最大的特点是引入分区的思路,弱化了分代的概念,合理利用垃圾收集各个周期的资源,解决了其他收集器甚至CMS的众多缺陷。
为解决CMS算法产生空间碎片和其它一系列的问题缺陷,HotSpot提供了另外一种垃圾回收策略,G1(Garbage First)算法,通过参数-XX:+UseG1GC来启用,该算法在JDK 7u4版本被正式推出,官网对此描述如下:
The Garbage-First (G1) collector is a server-style garbage collector, targeted for multi-processor machines with large memories. It meets garbage collection (GC) pause time goals with a high probability, while achieving high throughput. The G1 garbage collector is fully supported in Oracle JDK 7 update 4 and later releases. The G1 collector is designed for applications that: •Can operate concurrently with applications threads like the CMS collector.•Compact free space without lengthy GC induced pause times.•Need more predictable GC pause durations.•Do not want to sacrifice a lot of throughput performance.•Do not require a much larger Java heap.
官网的上述翻译如下:
G1垃圾收集算法主要应用在多CPU大内存的服务中,在满足高吞吐量的同时,竟可能的满足垃圾回收时的暂停时间,该设计主要针对如下应用场景:
•垃圾收集线程和应用线程并发执行,和CMS一样
•空闲内存压缩时避免冗长的暂停时间
•应用需要更多可预测的GC暂停时间
•不希望牺牲太多的吞吐性能
•不需要很大的Java堆 (一般建议8G以上内存使用)
1.3 为什么叫G1?
G1的目标是用来干掉CMS的,它同样是一款软实时垃圾回收器。相比CMS,G1的使用更加人性化。比如,CMS垃圾回收器的相关参数有72个,而G1的参数只有26个。G1的全称是GarbageFirst GC,为了达成上面制定的KPI,它和前面介绍的垃圾回收器,在对堆的划分上有一些不同。其它的回收器,都是对某个年代的整体收集,收集时间上自然不好控制。G1把堆切成了很多份,把每一份当作一个小目标,每一份收集时间自然是很好控制的。那么题又来了:G1有年轻代和老年代区分吗?
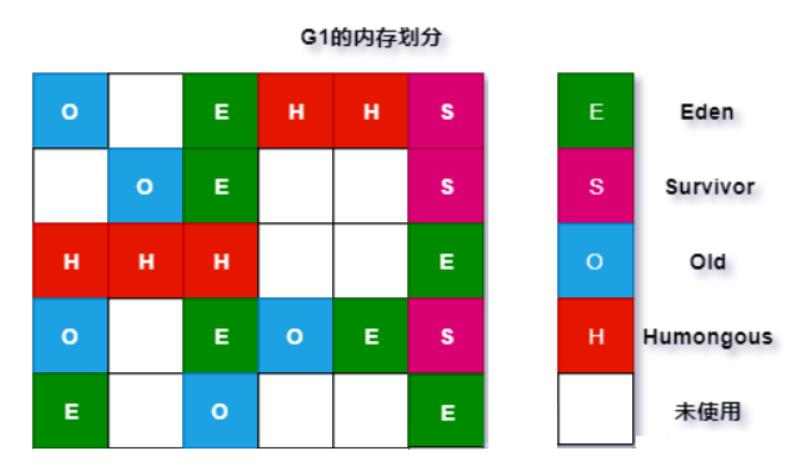
如图所示,G1也是有Eden区和Survivor区的概念的,只不过它们在内存上不是连续的,而是由一小份一小份组成的。这一小份区域的大小是固定的,名字叫做小堆区(Region)。小堆区可以是Eden也可以是Survivor区,还可以是Old区,所以G1的年轻代和老年代的概念都是逻辑上的。每一块Region,大小都是一致的,它的数值在1M-32M字节之间的一个2的幂值数。但假如我的对象太大,一个Region放不下怎们办?注意图中有一块很大的红色区域,叫Humongous Region,大小超过Region 50%的对象,将会在这里分配。Region的大小,可以通过参数进行设置:
-XX:G1HeapRegionSize=M 那么回收的时候,到底回收那些小堆区呢?是随机的吗?当然不是,事实上,垃圾最多的小堆区,会被优先回收,这也是G1名字的由来。
二、G1堆的内存结构
2.1 对比CMS堆结构
以往的垃圾回收算法,如CMS,使用的堆内存结构如下:
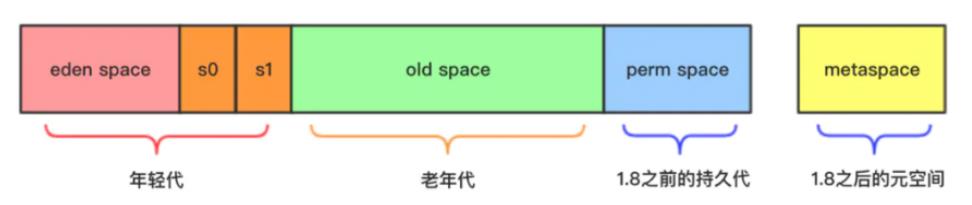
1.新生代:eden space + 2个survivor2.老年代:old space3.持久代:1.8之前的perm space4.元空间:1.8之后的metaspace;以上这些space必须是地址连续的空间。
2.2 G1
在G1算法中,采用了另外一种完全不同的方式组织堆内存,堆内存被划分为多个大小相等的内存块(Region),每个Region是逻辑连续的一段内存,结构如下:
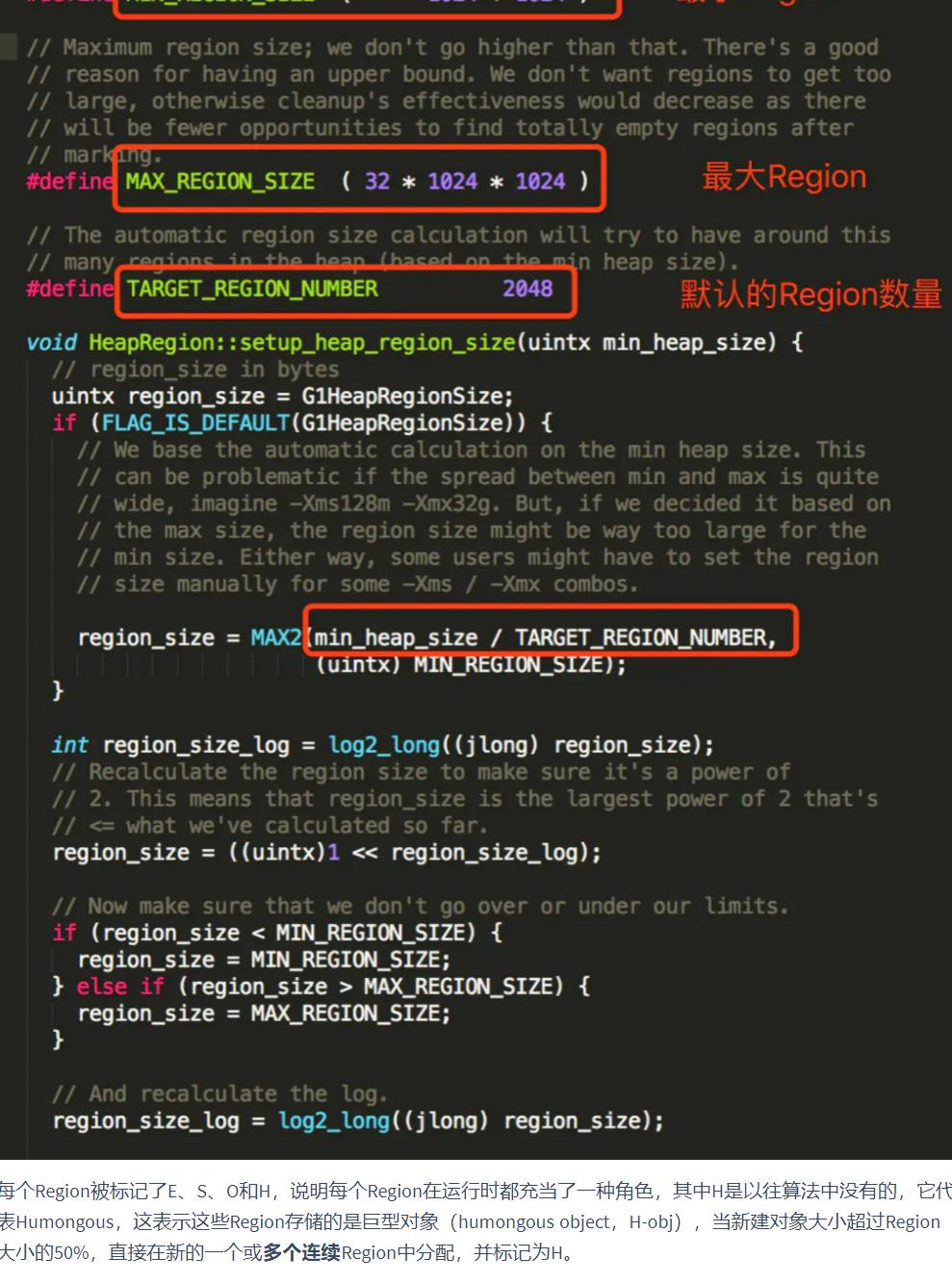
2.3 Region
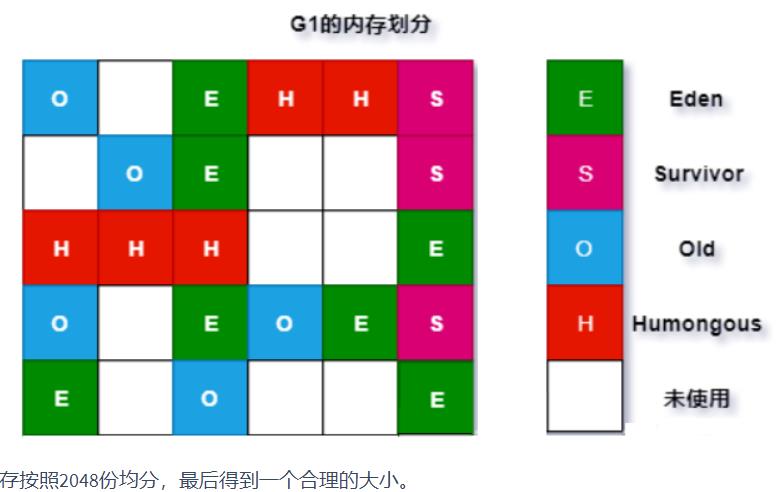
堆内存中一个Region的大小可以通过-XX:G1HeapRegionSize参数指定,大小区间只能是1M、2M、4M、8M、16M和32M,总之是2的幂次方,如果G1HeapRegionSize为默认值,则在堆初始化时计算Region的实际大小,具体实现如下:
三、G1的GC模式
G1中提供了三种模式垃圾回收模式,young gc、mixed gc 和 full gc,在不同的条件下被触发。
3.1 young gc
发生在年轻代的GC算法,一般对象(除了巨型对象)都是在eden region中分配内存,当所有eden region被耗尽无法申请内存时,就会触发一次young gc,这种触发机制和之前的young gc差不多,执行完一次young gc,活跃对象会被拷贝到survivor region或者晋升到old region中,空闲的region会被放入空闲列表中,等待下次被使用。
3.2 mixed gc
当越来越多的对象晋升到老年代old region时,为了避免堆内存被耗尽,虚拟机会触发一个混合的垃圾收集器,即mixed gc,该算法并不是一个old gc,除了回收整个young region,还会回收一部分的old region,这里需要注意:是一部分老年代,而不是全部老年代,可以选择哪些old region进行收集,从而可以对垃圾回收的耗时时间进行控制。
那么mixed gc什么时候被触发?
先回顾一下cms的触发机制,如果添加了以下参数:
-XX:CMSInitiatingOccupancyFraction=80
-XX:+UseCMSInitiatingOccupancyOnly
当老年代的使用率达到80%时,就会触发一次cms gc。相对的,mixed gc中也有一个阈值参数
-XX:InitiatingHeapOccupancyPercent,当老年代大小占整个堆大小百分比达到该阈值时,会触发一次mixed gc.
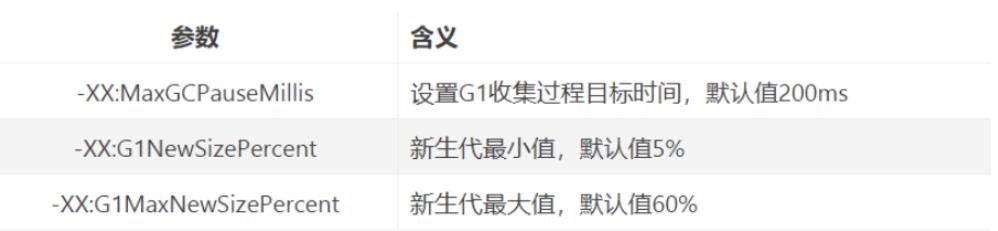
mixed gc的执行过程有点类似cms,主要分为以下几个步骤:
- 初始标记(Initial Marking):仅仅只是标记一下GC Roots能直接关联到的对象,并且修改TAMS指针的值,让下一阶段用户线程并发运行时,能正确地在可用的Region中分配新对象。这个阶段需要停顿线程,但耗时很短,而且是借用进行Minor GC的时候同步完成的,所以G1收集器在这个阶段实际并没有额外的停顿。
- 并发标记( Concurrent Marking):从GC Root开始对堆中对象进行可达性分析,递归扫描整个堆里的对象图,找出要回收的对象,这阶段耗时较长,但可与用户程序并发执行。当对象图扫描完成以后,并发时有引用变动的对象会产生漏标问题,G1中会使用SATB(snapshot-at-the-beginning)算法来解决。
- 最终标记(Final Marking):对用户线程做一个短暂的暂停,用于处理并发标记阶段仍遗留下来的最后那少量的SATB记录(漏标对象)。
- 筛选回收(Live Data Counting and Evacuation):负责更新Region的统计数据,对各个Region的回收价值和成本进行排序,根据用户所期望的停顿时间来制定回收计划,可以自由选择任意多个Region构成回收集,然后把决定回收的那一部分Region的存活对象复制到空的Region中,再清理掉整个旧Region的全部空间。这里的操作涉及存活对象的移动,是必须暂停用户线程,由多个收集器线程并行完成的。
TAMS是什么?要达到GC与用户线程并发运行,必须要解决回收过程中新对象的分配,所以G1为每一个Region区域设计了两个名为TAMS(Top at Mark Start)的指针,从Region区域划出一部分空间用于记录并发回收过程中的新对象。这样的对象认为它们是存活的,不纳入垃圾回收范围。
3.3full gc
如果对象内存分配速度过快,mixed gc来不及回收,导致老年代被填满,就会触发一次full gc,G1的full gc算法就是单线程执行的serial old gc,会导致异常长时间的暂停时间,需要进行不断的调优,尽可能的避免full gc.
四、G1中的年轻代
整个堆被分成大约2000个小区域块。最大的块32Mb,最小的1Mb。蓝色的块用来存储老年代对象,黄色的用来存储年轻代对象。
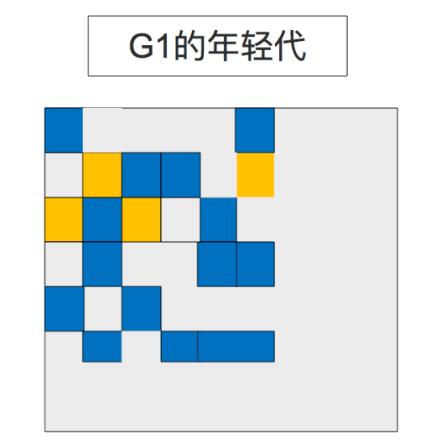
4.1 G1的年轻代回收
存活的对象被转移到一个/或多个survivor 块上去。 如果存活时间达到阀值,这部分对象就会被晋升到老年代。
此时会有一次 stop the world暂停,会计算出 Eden大小和 survivor 大小,用于下次young GC。统计信息会被保存下来,用于辅助计算size。比如暂停时间之类的指标也会纳入考虑。
这种做法使得调整各代区域的大小变得很容易,根据需求可以让他们变大一些或变小一些。
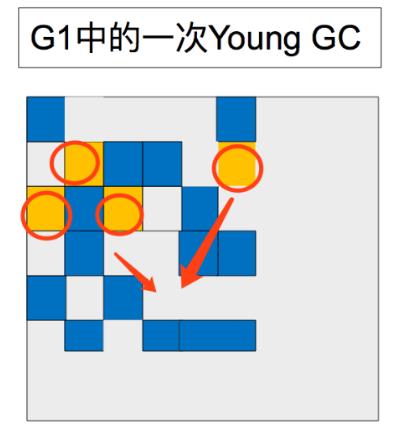
4.2 年轻代GC之后
现在存活的对象已经被转移或晋升到了survivor或old区了。
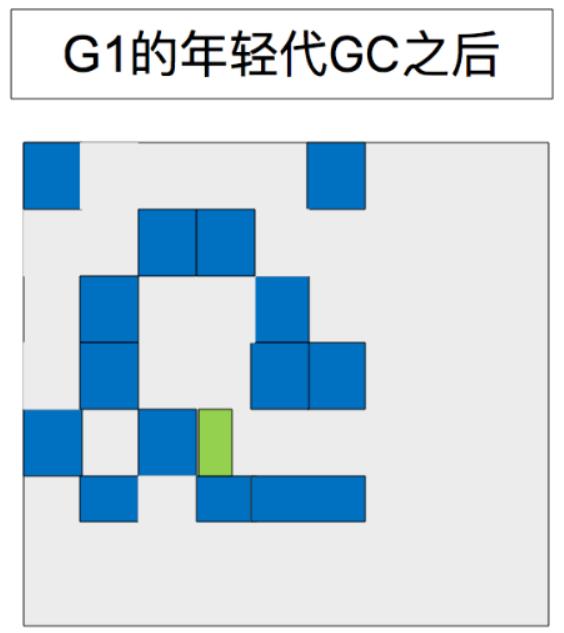
刚刚被晋升的对象用深蓝色表示。Survivor 用绿色表示。
总结起来,G1的年轻代收集归纳如下:
- 堆就是一整块内存空间,被分为多个heap区(regions)。
- 年轻代内存由一组不连续的heap块也就是region组成. 这使得在需要时很容易进行容量调整。
- 年轻代的垃圾收集,或者叫 young GCs, 会发生stop the world。 在回收时所有的应用程序线程都会被暂停。
- 年轻代 GC 通过多线程并行进行。
- 存活的对象被拷贝到新的 survivor 块或者老年代。
五、G1的老年代垃圾收集
就像CMS收集器一样,G1也是一个暂停少的收集器。下面这个流程图就描述了G1在老年代的各个收集阶段。
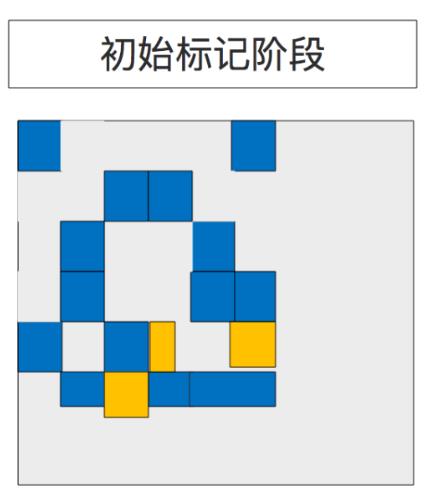
5.1、初始标记(Initial Marking)
存活对象的初始标记被固定放在年轻代垃圾收集阶段进行的,之所以把他列为第一个阶段,是因为只有进行初始标记了才有后续的阶段, 在日志中被记为 GC pause (young)(inital-mark)。
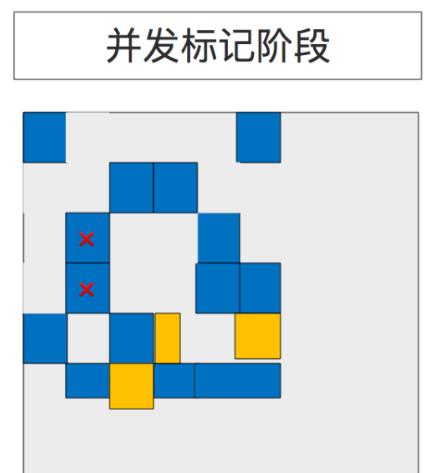
5.2 并发标记阶段(Concurrent Marking Phase)
如果发现有空的块(这里用红叉“X”标示的区域), 则会在 Remark 阶段立即移除。当然,”清单(accounting)”信息决定了活跃度的计算。
5.2.1 并发标记算法(三色标记法)
CMS和G1在并发标记时使用的是同一个算法:三色标记法,使用白灰黑三种颜色标记对象。白色是未标记;灰色自身被标记,引用的对象未标记;黑色自身与引用对象都已标记。
5.2.2 漏标问题
在remark过程中,黑色指向了白色,如果不对黑色重新扫描,则会漏标。会把白色D对象当作没有新引用指向从而回收掉。
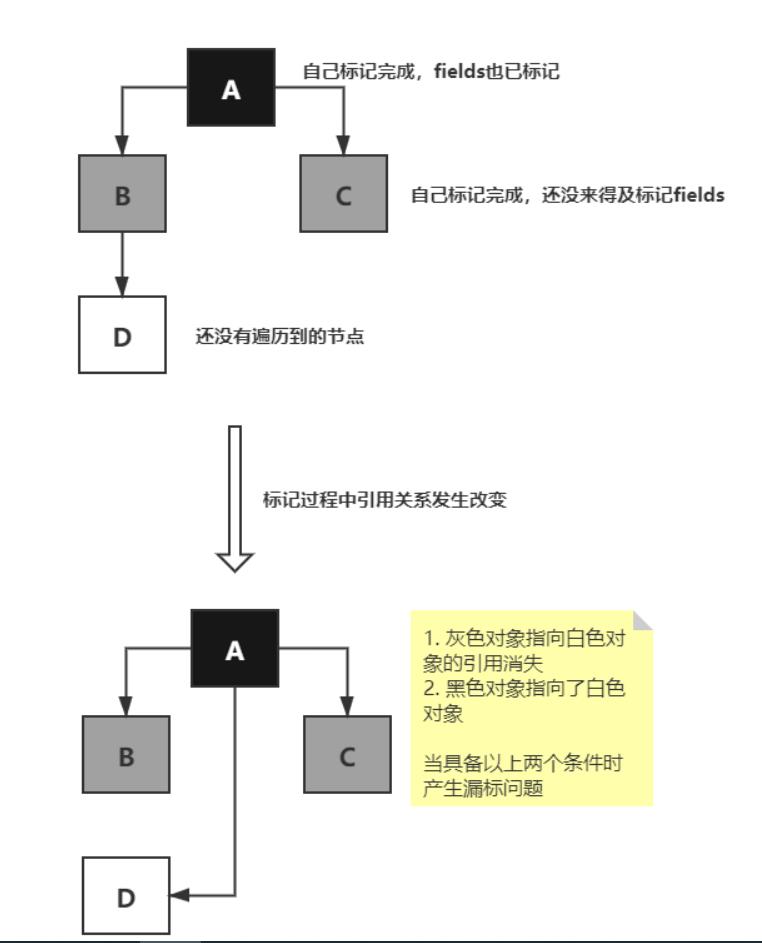
并发标记过程中,Mutator删除了所有从灰色到白色的引用,会产生漏标。此时白色对象应该被回收
产生漏标问题的条件有两个:
1.黑色对象指向了白色对象
2.灰色对象指向白色对象的引用消失
所以要解决漏标问题,打破两个条件之一即可:
- 跟踪黑指向白的增加
incremental update:增量更新,关注引用的增加,把黑色重新标记为灰色,下次重新扫描属性。CMS采用该方法。 - 记录灰指向白的消失
SATB snapshot at the beginning:关注引用的删除,当灰–>白消失时,要把这个 引用 推到GC的堆栈,保证白还能被GC扫描到。G1采用该方法。
为什么G1采用SATB而不用incremental update?
因为采用incremental update把黑色重新标记为灰色后,之前扫描过的还要再扫描一遍,效率太低。
G1有RSet与SATB相配合。Card Table里记录了RSet,RSet里记录了其他对象指向自己的引用,这样就不需要再扫描其他区域,只要扫描RSet就可以了。
也就是说 灰色–>白色 引用消失时,如果没有 黑色–>白色,引用会被push到堆栈,下次扫描时拿到这个引用,由于有RSet的存在,不需要扫描整个堆去查找指向白色的引用,效率比较高。SATB配合RSet浑然天成。
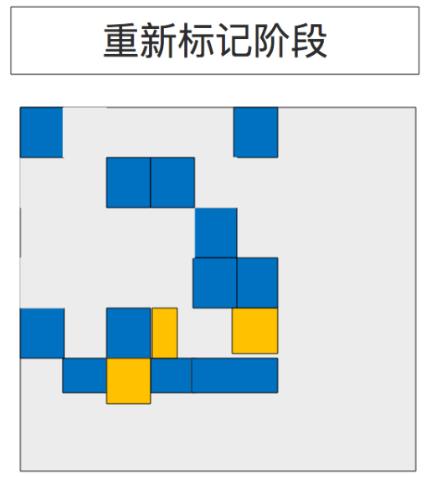
5.3 重新标记阶段(Remark Phase)
空的区域块被移除并回收。现在计算所有区域块的活跃度(Region liveness)。
5.4 复制清除阶段(Copying/Cleanup Phase)
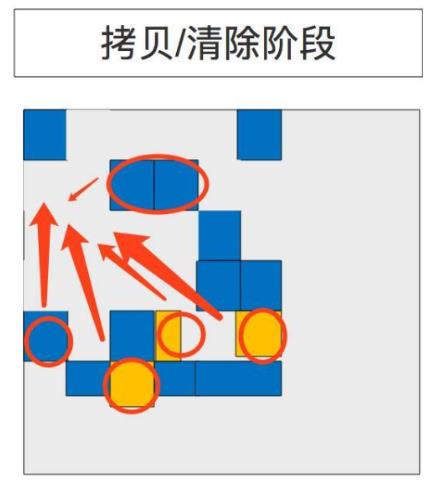
G1选择“活跃度(liveness)”最低的区域块,这些区域可以最快的完成回收。然后这些区域和年轻代GC在同时被垃圾收集 。 日志上是被标识为 [GC pause (mixed)]。所以年轻代和老年代都在同一时间被垃圾收集。
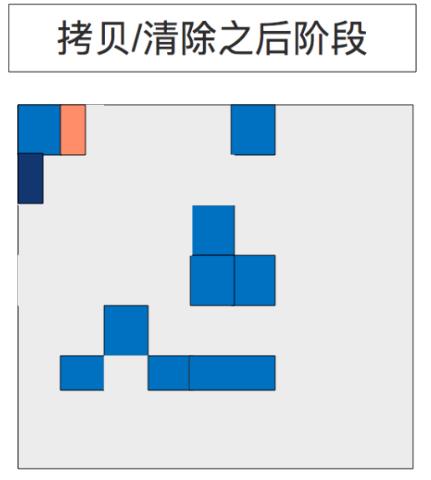
5.5 复制/清除之后阶段(After Copying/Cleanup Phase)
老年代GC总结
老生代的G1垃圾回收有以下几个关键点:
1、并发标记阶段(Concurrent Marking Phase)
- 活跃度信息在程序运行的时候就被并行的计算了出来。
- 活跃度(liveness)信息标记出哪些区域块最适合回收,在转移暂停期间最适合回收掉。
- 没有sweep阶段。但CMS是有这个阶段的。
2、重新标记阶段(Remark Phase)
- 使用了Snapshot-at-the-Beginning (SATB)算法,这个要比CMS的算法快很多。
- 完全空的区域块会被直接回收掉。
3、复制/清除阶段(Copying/Cleanup Phase)
- 年轻代和老年代会被同时回收。
- 老年代的区域块会不会被选择,取决于它的活跃度。
六、垃圾收集器之RSet和Card Table
思考
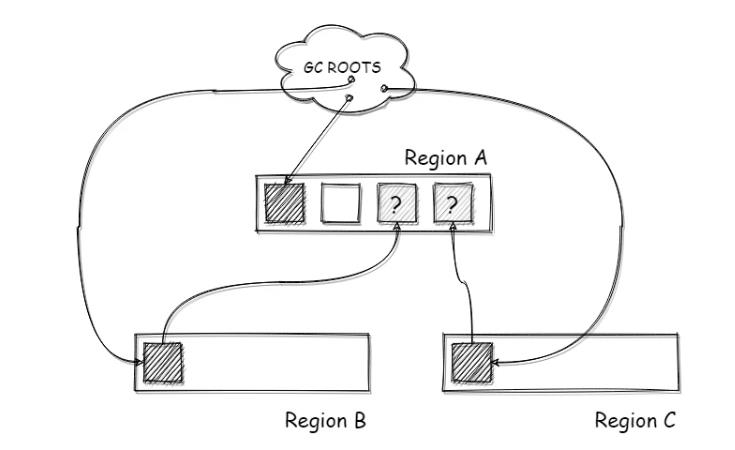
比如在对某个区域进行回收时,首先从GC ROOT开始遍历可直达这些区域中的对象,可由于晋升或者移动的原因,这些区域中的某些对象移动到了其他区域,可是移动之后仍然保持着对原区域对象的引用;那么此时原区域中被引用的对象对GC ROOT来说并不能“直达”,他们被其他对象的区域引用,这个发起引用的其他对象对于GC ROOT可达。这种情况下,如果想正确的标记这种GC ROOT不可直达但被其他区域引用的对象时就需要遍历所有区域了,代价太高。
如下图所示,如果此时对区域A进行回收,那么需要标记区域A中所有存活的对象,可是A中有两个对象被其他区域引用,这两个灰色的问号对象在区域A中对GC ROOTS来说是不可达的,但是实际上这两个对象的引用对象被GC ROOTS引用,所以这两个对象还是存活状态。此时如果不将这两个对象标记,那么就会导致标记的遗漏,可能造成误回收的问题
6.2 RememberedSet(记忆卡集合)
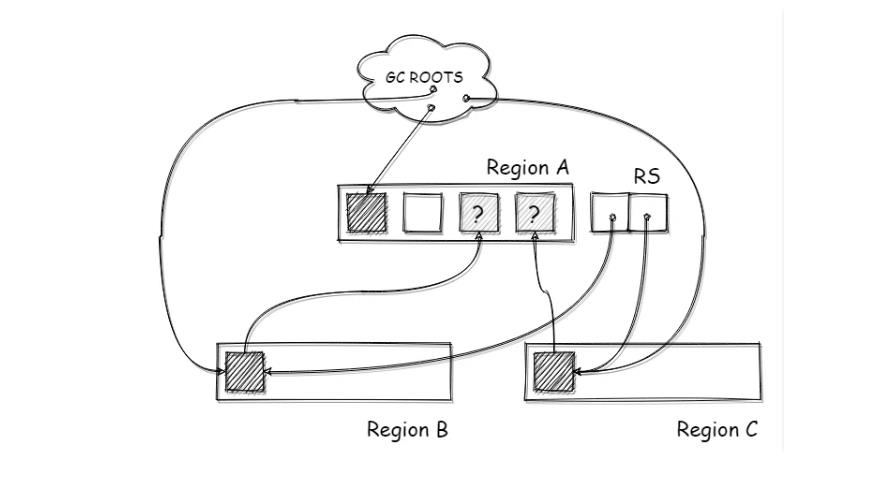
RememberedSet(简称RS或RSet)就是用来解决这个问题的,RSet会记录这种跨代引用的关系。在进行标记时,除了从GC ROOTS开始遍历,还会从RSet遍历,确保标记该区域所有存活的对象(其实不光是G1,其他的分代回收器里也有,比如CMS)
如下图所示,G1中利用一个RSet来记录这个跨区域引用的关系,每个区域都有一个RSet,用来记录这个跨区引用,这样在进行标记的时候,将RSet也作为ROOTS进行遍历即可
6.3 Card Table
6.3.1 Card Table是什么
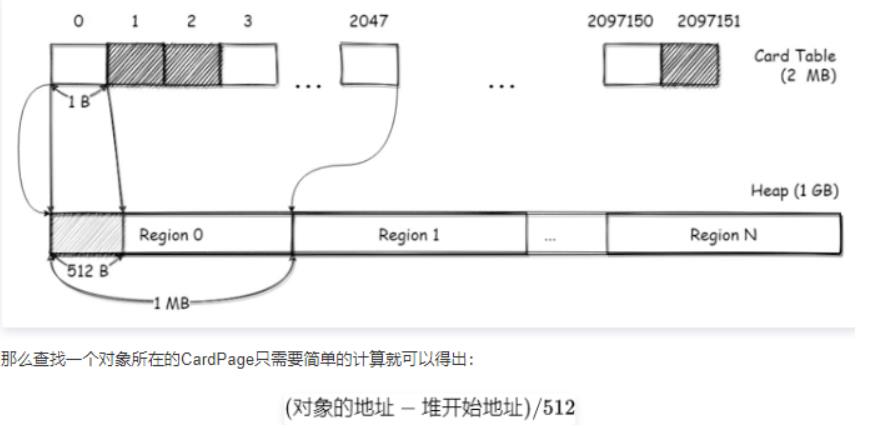
在G1 堆中,存在一个CardTable的数据,CardTable 是由元素为1B的数组来实现的,数组里的元素称之为卡片/卡页(Page)。这个CardTable会映射到整个堆的空间,每个卡片会对应堆中的512B空间。
如下图所示,在一个大小为1 GB的堆下,那么CardTable的长度为2097151 (1GB / 512B);每个Region 大小为1 MB,每个Region都会对应2048个Card Page。
6.4 Card Table & RSet协作
介绍完了CardTable,下面说说G1中RSet和CardTable如何配合工作。
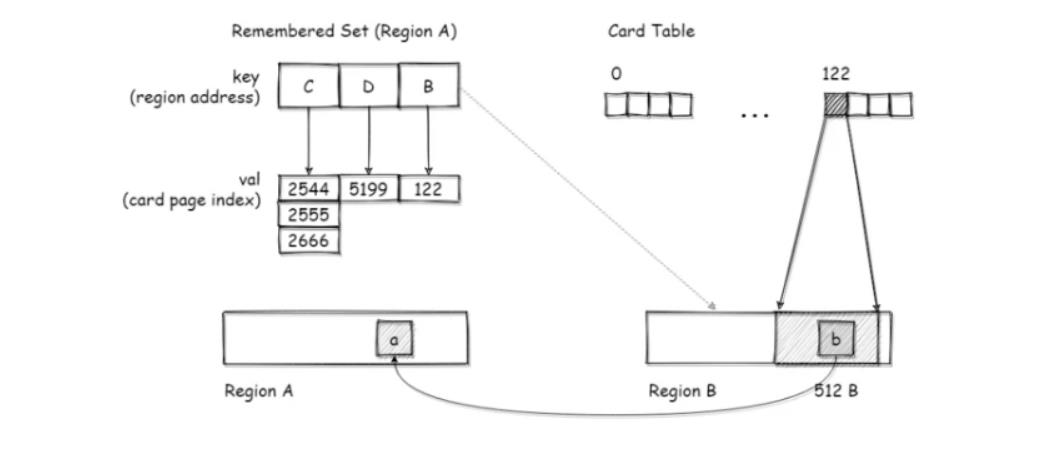
每个区域中都有一个RSet,通过hash表实现,这个hash表的key是引用本区域的其他区域的地址,value是一个数组,数组的元素是引用方的对象所对应的Card Page在Card Table中的下标。
如下图所示,区域B中的对象b引用了区域A中的对象a,这个引用关系跨了两个区域。b对象所在的CardPage为122,在区域A的RSet中,以区域B的地址作为key,b对象所在CardPage下标为value记录了这个引用关系,这样就完成了这个跨区域引用的记录。
以上是关于G1垃圾收集器深度剖析的主要内容,如果未能解决你的问题,请参考以下文章
直通BAT必考题系列:深入剖析JVM之G1收集器及回收流程与推荐用例
直通BAT必考题系列:深入剖析JVM之G1收集器及回收流程与推荐用例