MNIST读取出错RuntimeError Dataset not found.You can download解决方案
Posted herosunly
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MNIST读取出错RuntimeError Dataset not found.You can download解决方案相关的知识,希望对你有一定的参考价值。
1. 前言
Pytorch官网教程中,第一个程序是使用简单神经网络对Fashion MNIST数据进行学习和预测,而机器学习/深度学习的处理流程的第一步是:读取数据。代码如下所示:
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt
# Download training data from open datasets.
training_data = datasets.FashionMNIST(
root="data",
train=True,
download=True,
transform=ToTensor(),
)
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data",
train=False,
download=True,
transform=ToTensor(),
)
然而不幸的是,由于国情导致的网络问题,往往会导致在下载过程中出错,所以出现如下问题:RuntimeError: Dataset not found. You can use download=True to download it,很多平台和博客提供的解决方案并不完美而且对新手并不友好(不说明逻辑和原因)。
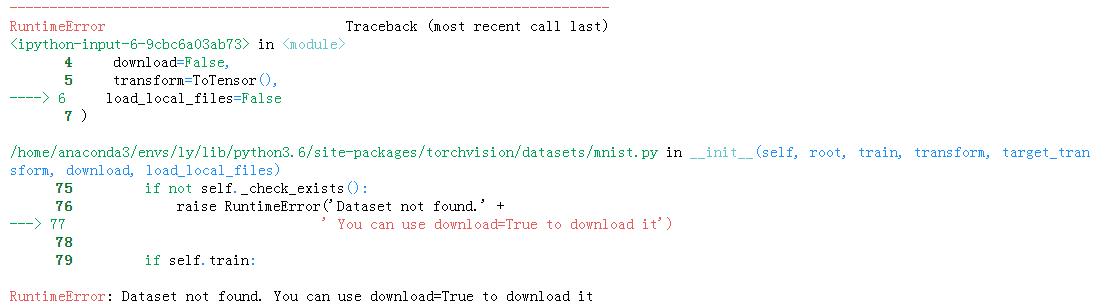
那该如何解决呢?
2. 下载数据
可通过迅雷或者其他下载工具对下列4个数据文件进行下载:
- 训练集图像:http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz
- 训练集标签:http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz
- 测试集图像:http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
- 测试集标签:http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz
3. 修改代码
3.1 修改逻辑
首先,我们需要得到修改的代码所处的位置,根据Python系列课程之模块的内容,包具有一个特殊的属性: __path__ ,简单来说也就是包所处的具体路径。
import torchvision
print(torchvision.__path__)
['/home/anaconda3/lib/python3.6/site-packages/torchvision']

可以得到mnist.py的具体路径为上述路径下的子路径/datasets/mnist.py。阅读其关键代码可知,download=True不仅会下载.gz文件(图像+标签),而且会将其保存成torch格式的.pt文件。而我们下载的文件只是.gz文件,所以需要通过代码将.gz转换成.pt。
为了不影响之前的参数和处理逻辑,所以在对象初始化增加了一个参数:load_gz_files和对应的处理函数load_gz_files()。load_gz_files()会借用utils.py中的extract_archive()函数和check_integrity()。
def load_gz_files(self):
"""Load the .gz format MNIST data if it exist ."""
if self._check_exists():
return
if not os.path.exists(self.processed_folder):
makedir_exist_ok(self.processed_folder)
for url, md5 in self.resources:
filename = url.rpartition('/')[2]
fpath = os.path.join(self.raw_folder, filename)
if check_integrity(fpath, md5):
extract_archive(from_path=fpath, to_path=self.processed_folder, remove_finished=False)
training_set = (
read_image_file(os.path.join(self.processed_folder, 'train-images-idx3-ubyte')),
read_label_file(os.path.join(self.processed_folder, 'train-labels-idx1-ubyte'))
)
test_set = (
read_image_file(os.path.join(self.processed_folder, 't10k-images-idx3-ubyte')),
read_label_file(os.path.join(self.processed_folder, 't10k-labels-idx1-ubyte'))
)
with open(os.path.join(self.processed_folder, self.training_file), 'wb') as f:
torch.save(training_set, f)
with open(os.path.join(self.processed_folder, self.test_file), 'wb') as f:
torch.save(test_set, f)
print('Done!')
为了避免load_gz_files()函数和原有的download()函数互相影响,所以简单修改了下代码(完整代码在文章最后,使用的时候将其复制并覆盖mnist.py文件内容即可):
if load_gz_files:
self.load_gz_files()
else:
if download:
self.download()
3.2 代码使用
修改后代码如何使用呢?
- 新建文件夹,如/home/data/FashionMNIST/raw,并把下载的四个.gz文件放入其中。
- 读取文件代码如下(需要注意的是root路径是新建文件夹的根路径):
import torch
from torch import nn
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision.transforms import ToTensor, Lambda, Compose
import matplotlib.pyplot as plt
training_data = datasets.FashionMNIST(
root="/home/data/",
train=True,
download=False,
transform=ToTensor(),
load_gz_files=True
)
test_data = datasets.FashionMNIST(
root="/home/data/",
train=False,
download=False,
transform=ToTensor(),
load_gz_files=True
)
如果在from .utils import语句中报错:ImportError: cannot import name ‘makedir_exist_ok’,如下所示:
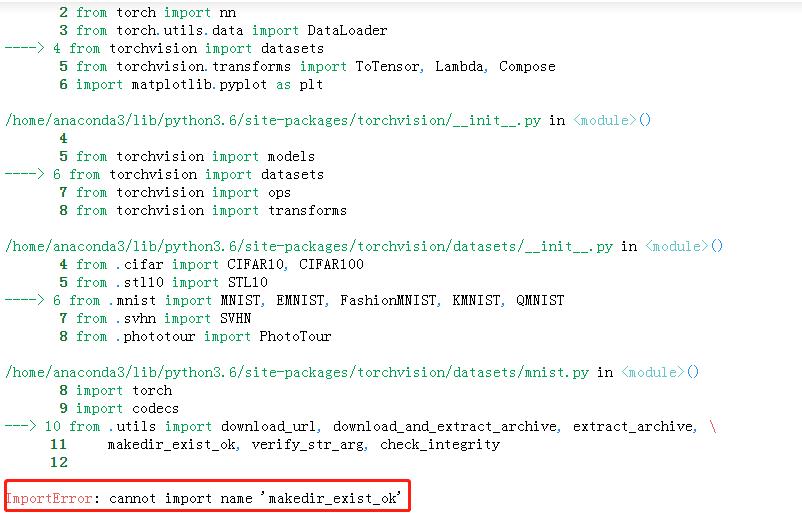
只须在utils.py中添加小段函数代码:
def makedir_exist_ok(dirpath):
"""
Python2 support for os.makedirs(.., exist_ok=True)
"""
try:
os.makedirs(dirpath)
except OSError as e:
if e.errno == errno.EEXIST:
pass
else:
raise
3.3 附录:mnist.py完整代码
为了方便大家修改,所以提供源码如下:
from __future__ import print_function
from .vision import VisionDataset
import warnings
from PIL import Image
import os
import os.path
import numpy as np
import torch
import codecs
from .utils import download_url, download_and_extract_archive, extract_archive, \\
makedir_exist_ok, verify_str_arg, check_integrity
class MNIST(VisionDataset):
"""`MNIST <http://yann.lecun.com/exdb/mnist/>`_ Dataset.
Args:
root (string): Root directory of dataset where ``MNIST/processed/training.pt``
and ``MNIST/processed/test.pt`` exist.
train (bool, optional): If True, creates dataset from ``training.pt``,
otherwise from ``test.pt``.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
"""
resources = [
("http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz", "f68b3c2dcbeaaa9fbdd348bbdeb94873"),
("http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz", "d53e105ee54ea40749a09fcbcd1e9432"),
("http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz", "9fb629c4189551a2d022fa330f9573f3"),
("http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz", "ec29112dd5afa0611ce80d1b7f02629c")
]
training_file = 'training.pt'
test_file = 'test.pt'
classes = ['0 - zero', '1 - one', '2 - two', '3 - three', '4 - four',
'5 - five', '6 - six', '7 - seven', '8 - eight', '9 - nine']
@property
def train_labels(self):
warnings.warn("train_labels has been renamed targets")
return self.targets
@property
def test_labels(self):
warnings.warn("test_labels has been renamed targets")
return self.targets
@property
def train_data(self):
warnings.warn("train_data has been renamed data")
return self.data
@property
def test_data(self):
warnings.warn("test_data has been renamed data")
return self.data
def __init__(self, root, train=True, transform=None, target_transform=None,
download=False, load_gz_files=False):
super(MNIST, self).__init__(root, transform=transform,
target_transform=target_transform)
self.train = train # training set or test set
if load_gz_files:
self.load_gz_files()
else:
if download:
self.download()
if not self._check_exists():
raise RuntimeError('Dataset not found.' +
' You can use download=True to download it')
if self.train:
data_file = self.training_file
else:
data_file = self.test_file
self.data, self.targets = torch.load(os.path.join(self.processed_folder, data_file))
def __getitem__(self, index):
"""
Args:
index (int): Index
Returns:
tuple: (image, target) where target is index of the target class.
"""
img, target = self.data[index], int(self.targets[index])
# doing this so that it is consistent with all other datasets
# to return a PIL Image
img = Image.fromarray(img.numpy(), mode='L')
if self.transform is not None:
img = self.transform(img)
if self.target_transform is not None:
target = self.target_transform(target)
return img, target
def __len__(self):
return len(self.data)
@property
def raw_folder(self):
return os.path.join(self.root, self.__class__.__name__, 'raw')
@property
def processed_folder(self):
return os.path.join(self.root, self.__class__.__name__, 'processed')
@property
def class_to_idx(self):
return {_class: i for i, _class in enumerate(self.classes)}
def _check_exists(self):
return (os.path.exists(os.path.join(self.processed_folder,
self.training_file)) and
os.path.exists(os.path.join(self.processed_folder,
self.test_file)))
def load_gz_files(self):
"""Load the .gz format MNIST data if it exist ."""
if self._check_exists():
return
if not os.path.exists(self.processed_folder):
makedir_exist_ok(self.processed_folder)
for url, md5 in self.resources:
filename = url.rpartition('/')[2]
fpath = os.path.join(self.raw_folder, filename)
if check_integrity(fpath, md5):
extract_archive(from_path=fpath, to_path=self.processed_folder, remove_finished=False)
training_set = (
read_image_file(os.path.join(self.processed_folder, 'train-images-idx3-ubyte')),
read_label_file(os.path.join(self.processed_folder, 'train-labels-idx1-ubyte'))
)
test_set = (
read_image_file(os.path.join(self.processed_folder, 't10k-images-idx3-ubyte')),
read_label_file(os.path.join(self.processed_folder, 't10k-labels-idx1-ubyte'))
)
with open(os.path.join(self.processed_folder, self.training_file), 'wb') as f:
torch.save(training_set, f)
with open(os.path.join(self.processed_folder, self.test_file), 'wb') as f:
torch.save(test_set, f)
print('Done!')
def download(self):
"""Download the MNIST data if it doesn't exist in processed_folder already."""
if self._check_exists():
return
makedir_exist_ok(self.raw_folder)
makedir_exist_ok(self.processed_folder)
# download files
for url, md5 in self.resources:
filename = url.rpartition('/')[2]
download_and_extract_archive(url, download_root=self.raw_folder, filename=filename, md5=md5)
# process and save as torch files
print('Processing...')
training_set = (
read_image_file(os.path.join(self.raw_folder, 'train-images-idx3-ubyte')),
read_label_file(os.path.join(self.raw_folder, 'train-labels-idx1-ubyte'))
)
test_set = (
read_image_file(os.path.join(self.raw_folder, 't10k-images-idx3-ubyte')),
read_label_file(os.path.join(self.raw_folder, 't10k-labels-idx1-ubyte'))
)
with open(os.path.join(self.processed_folder, self.training_file), 'wb') as f:
torch.save(training_set, f)
with open(os.path.join(self.processed_folder, self.test_file), 'wb') as f:
torch.save(test_set, f)
print('Done!')
def extra_repr(self):
return "Split: {}".format("Train" if self.train is True else "Test")
class FashionMNIST(MNIST):
"""`Fashion-MNIST <https://github.com/zalandoresearch/fashion-mnist>`_ Dataset.
Args:
root (string): Root directory of dataset where ``Fashion-MNIST/processed/training.pt``
and ``Fashion-MNIST/processed/test.pt`` exist.
train (bool, optional): If True, creates dataset from ``training.pt``,
otherwise from ``test.pt``.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
"""
resources = [
("http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-images-idx3-ubyte.gz",
"8d4fb7e6c68d591d4c3dfef9ec88bf0d"),
("http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/train-labels-idx1-ubyte.gz",
"25c81989df183df01b3e8a0aad5dffbe"),
("http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-images-idx3-ubyte.gz",
"bef4ecab320f06d8554ea6380940ec79"),
("http://fashion-mnist.s3-website.eu-central-1.amazonaws.com/t10k-labels-idx1-ubyte.gz",
"bb300cfdad3c16e7a12a480ee83cd310")
]
classes = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat', 'Sandal',
'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
class KMNIST(MNIST):
"""`Kuzushiji-MNIST <https://github.com/rois-codh/kmnist>`_ Dataset.
Args:
root (string): Root directory of dataset where ``KMNIST/processed/training.pt``
and ``KMNIST/processed/test.pt`` exist.
train (bool, optional): If True, creates dataset from ``training.pt``,
otherwise from ``test.pt``.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
"""
resources = [
("http://codh.rois.ac.jp/kmnist/dataset/kmnist/train-images-idx3-ubyte.gz", "bdb82020997e1d708af4cf47b453dcf7"),
("http://codh.rois.ac.jp/kmnist/dataset/kmnist/train-labels-idx1-ubyte.gz", "e144d726b3acfaa3e44228e80efcd344"),
("http://codh.rois.ac.jp/kmnist/dataset/kmnist/t10k-images-idx3-ubyte.gz", "5c965bf0a639b31b8f53240b1b52f4d7"),
("http://codh.rois.ac.jp/kmnist/dataset/kmnist/t10k-labels-idx1-ubyte.gz", "7320c461ea6c1c855c0b718fb2a4b134")
]
classes = ['o', 'ki', 'su', 'tsu', 'na', 'ha', 'ma', 'ya', 're', 'wo']
class EMNIST(MNIST):
"""`EMNIST <https://www.westernsydney.edu.au/bens/home/reproducible_research/emnist>`_ Dataset.
Args:
root (string): Root directory of dataset where ``EMNIST/processed/training.pt``
and ``EMNIST/processed/test.pt`` exist.
split (string): The dataset has 6 different splits: ``byclass``, ``bymerge``,
``balanced``, ``letters``, ``digits`` and ``mnist``. This argument specifies
which one to use.
train (bool, optional): If True, creates dataset from ``training.pt``,
otherwise from ``test.pt``.
download (bool, optional): If true, downloads the dataset from the internet and
puts it in root directory. If dataset is already downloaded, it is not
downloaded again.
transform (callable, optional): A function/transform that takes in an PIL image
and returns a transformed version. E.g, ``transforms.RandomCrop``
target_transform (callable, optional): A function/transform that takes in the
target and transforms it.
"""
# Updated URL from https://www.nist.gov/node/1298471/emnist-dataset since the
# _official_ download link
# https://cloudstor.aarnet.edu.au/plus/s/ZNmuFiuQTqZlu9W/download
# is (currently) unavailable
url = 'http://www.itl.nist.gov/iaui/vip/cs_links/EMNIST/gzip.zip'
md5 = "58c8d27c78d21e728a6bc7b3cc06412e"
splits = ('byclass', 'bymerge', 'balanced', 'letters', 'digits', 'mnist')
def __init__(self, root, split, **kwargs):
self.split = verify_str_arg(split, "split", self.splits)
self.training_file = self._training_file(split)
self.test_file = self._test_file(split)
super(EMNIST, self).__init__(root, **kwargs)
@staticmethod
def _training_file(split):
return 'training_{}.pt'.format(split)
@staticmethod
def _test_file(split):
return 'test_{}.pt'.format(split)
def download(self):