MySQL表结构设计
Posted gonghaiyu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL表结构设计相关的知识,希望对你有一定的参考价值。
mysql表结构设计包括:字段类型选择 + 物理存储设计 + 表的访问设计。
数字类型
整型类型
在整型类型中,有 signed 和 unsigned 属性,其表示的是整型的取值范围,默认为 signed。在设计时,我不建议你刻意去用 unsigned 属性,因为在做一些数据分析时,SQL 可能返回的结果并不是想要得到的结果。
来看一个“销售表 sale”的例子,其表结构和数据如下。这里要特别注意,列 sale_count 用到的是 unsigned 属性(即设计时希望列存储的数值大于等于 0):
mysql> SHOW CREATE TABLE sale\\G
*************************** 1. row ***************************
Table: sale
Create Table: CREATE TABLE `sale` (
`sale_date` date NOT NULL,
`sale_count` int unsigned DEFAULT NULL,
PRIMARY KEY (`sale_date`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.00 sec)
mysql> SELECT * FROM sale;
+------------+------------+
| sale_date | sale_count |
+------------+------------+
| 2020-01-01 | 10000 |
| 2020-02-01 | 8000 |
| 2020-03-01 | 12000 |
| 2020-04-01 | 9000 |
| 2020-05-01 | 10000 |
| 2020-06-01 | 18000 |
+------------+------------+
6 rows in set (0.00 sec)
其中,sale_date 表示销售的日期,sale_count 表示每月的销售数量。现在有一个需求,老板想要统计每个月销售数量的变化,以此做商业决策。这条 SQL 语句需要应用到非等值连接,但也并不是太难写:
SELECT
s1.sale_date, s2.sale_count - s1.sale_count AS diff
FROM
sale s1
LEFT JOIN
sale s2 ON DATE_ADD(s2.sale_date, INTERVAL 1 MONTH) = s1.sale_date
ORDER BY sale_date;
然而,在执行的过程中,由于列 sale_count 用到了 unsigned 属性,会抛出这样的结果:
ERROR 1690 (22003): BIGINT UNSIGNED value is out of range in '(`test`.`s2`.`sale_count` - `test`.`s1`.`sale_count`)'
可以看到,MySQL 提示用户计算的结果超出了范围。其实,这里 MySQL 要求 unsigned 数值相减之后依然为 unsigned,否则就会报错。
为了避免这个错误,需要对数据库参数 sql_mode 设置为 NO_UNSIGNED_SUBTRACTION,允许相减的结果为 signed,这样才能得到最终想要的结果:
mysql> SET sql_mode='NO_UNSIGNED_SUBTRACTION';
Query OK, 0 rows affected (0.00 sec)
SELECT
s1.sale_date,
IFNULL(s2.sale_count - s1.sale_count,'') AS diff
FROM
sale s1
LEFT JOIN sale s2
ON DATE_ADD(s2.sale_date, INTERVAL 1 MONTH) = s1.sale_date
ORDER BY sale_date;
+------------+-------+
| sale_date | diff |
+------------+-------+
| 2020-01-01 | |
| 2020-02-01 | 2000 |
| 2020-03-01 | -4000 |
| 2020-04-01 | 3000 |
| 2020-05-01 | -1000 |
| 2020-06-01 | -8000 |
+------------+-------+
6 rows in set (0.00 sec)
浮点类型和高精度型
在真实的生产环境中不推荐使用float和double。从 MySQL 8.0.17 版本开始,当创建表用到类型 Float 或 Double 时,会抛出下面的警告:MySQL 提醒用户不该用上述浮点类型,甚至提醒将在之后版本中废弃浮点类型。而数字类型中的高精度 DECIMAL 类型可以使用,当声明该类型列时,可以(并且通常必须要)指定精度和标度,例如:
salary DECIMAL(8,2)
其中,8 是精度(精度表示保存值的主要位数),2 是标度(标度表示小数点后面保存的位数)。通常在表结构设计中,类型 DECIMAL 可以用来表示用户的工资、账户的余额等精确到小数点后 2 位的业务。
然而,在海量并发的互联网业务中使用,金额字段的设计并不推荐使用 DECIMAL 类型,而更推荐使用 INT 整型类型(下文就会分析原因)。
数字类型案例:业务表结构设计实战
整型类型与自增设计
整型结合属性 auto_increment,可以实现自增功能,但在表结构设计时用自增做主键,希望你特别要注意以下两点,若不注意,可能会对业务造成灾难性的打击:
- 用 BIGINT 做主键,而不是 INT;
- 自增值并不持久化,可能会有回溯现象(MySQL 8.0 版本前)。
从表 1 可以发现,INT 的范围最大在 42 亿的级别,在真实的互联网业务场景的应用中,很容易达到最大值。例如一些流水表、日志表,每天 1000W 数据量,420 天后,INT 类型的上限即可达到。
因此,(敲黑板 1)用自增整型做主键,一律使用 BIGINT,而不是 INT。不要为了节省 4 个字节使用 INT,当达到上限时,再进行表结构的变更,将是巨大的负担与痛苦。
那这里又引申出一个有意思的问题:如果达到了 INT 类型的上限,数据库的表现又将如何呢?是会重新变为 1?我们可以通过下面的 SQL 语句验证一下:
mysql> CREATE TABLE t (
-> a INT AUTO_INCREMENT PRIMARY KEY
-> );
mysql> INSERT INTO t VALUES (2147483647);
Query OK, 1 row affected (0.01 sec)
mysql> INSERT INTO t VALUES (NULL);
ERROR 1062 (23000): Duplicate entry '2147483647' for key 't.PRIMARY'
可以看到,当达到 INT 上限后,再次进行自增插入时,会报重复错误,MySQL 数据库并不会自动将其重置为 1。
第二个特别要注意的问题是,(敲黑板 2)MySQL 8.0 版本前,自增不持久化,自增值可能会存在回溯问题!
mysql> SELECT * FROM t;
+---+
| a |
+---+
| 1 |
| 2 |
| 3 |
+---+
3 rows in set (0.01 sec)
mysql> DELETE FROM t WHERE a = 3;
Query OK, 1 row affected (0.02 sec)
mysql> SHOW CREATE TABLE t\\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`a` int NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`a`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.00 sec
可以看到,在删除自增为 3 的这条记录后,下一个自增值依然为 4(AUTO_INCREMENT=4),这里并没有错误,自增并不会进行回溯。但若这时数据库发生重启,那数据库启动后,表 t 的自增起始值将再次变为 3,即自增值发生回溯。具体如下所示:
mysql> SHOW CREATE TABLE t\\G
*************************** 1. row ***************************
Table: t
Create Table: CREATE TABLE `t` (
`a` int NOT NULL AUTO_INCREMENT,
PRIMARY KEY (`a`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
1 row in set (0.00 s
若要彻底解决这个问题,有以下 2 种方法:
- 升级 MySQL 版本到 8.0 版本,每张表的自增值会持久化;
- 若无法升级数据库版本,则强烈不推荐在核心业务表中使用自增数据类型做主键。
其实,在海量互联网架构设计过程中,为了之后更好的分布式架构扩展性,不建议使用整型类型做主键,更为推荐的是字符串类型(这部分内容将在 05 节中详细介绍)。
资金字段设计
在用户余额、基金账户余额、数字钱包、零钱等的业务设计中,由于字段都是资金字段,通常程序员习惯使用 DECIMAL 类型作为字段的选型,因为这样可以精确到分,如:DECIMAL(8,2)。
CREATE TABLE User (
userId BIGINT AUTO_INCREMENT,
money DECIMAL(8,2) NOT NULL,
......
)
(敲黑板3)在海量互联网业务的设计标准中,并不推荐用 DECIMAL 类型,而是更推荐将 DECIMAL 转化为 整型类型。也就是说,资金类型更推荐使用用分单位存储,而不是用元单位存储。如1元在数据库中用整型类型 100 存储。
金额字段的取值范围如果用 DECIMAL 表示的,如何定义长度呢?因为类型 DECIMAL 是个变长字段,若要定义金额字段,则定义为 DECIMAL(8,2) 是远远不够的。这样只能表示存储最大值为 999999.99,百万级的资金存储。
用户的金额至少要存储百亿的字段,而统计局的 GDP 金额字段则可能达到数十万亿级别。用类型 DECIMAL 定义,不好统一。
另外重要的是,类型 DECIMAL 是通过二进制实现的一种编码方式,计算效率远不如整型来的高效。因此,推荐使用 BIG INT 来存储金额相关的字段。
字段存储时采用分存储,即便这样 BIG INT 也能存储千兆级别的金额。这里,1兆 = 1万亿。
这样的好处是,所有金额相关字段都是定长字段,占用 8 个字节,存储高效。另一点,直接通过整型计算,效率更高。
注意,在数据库设计中,我们非常强调定长存储,因为定长存储的性能更好。
那么,当使用 BIG INT 存储金额字段的时候,如何表示小数点中的数据呢?其实,这部分完全可以交由前端进行处理并展示。作为数据库本身,只要按分进行存储即可。
字符串类型:不能忽略的 COLLATION
CHAR 和 VARCHAR 的定义
CHAR(N) 用来保存固定长度的字符,N 的范围是 0 ~ 255,请牢记,N 表示的是字符,而不是字节。VARCHAR(N) 用来保存变长字符,N 的范围为 0 ~ 65536, N 同样表示字符。
在超出 65536 个字节的情况下,可以考虑使用更大的字符类型 TEXT 或 BLOB,两者最大存储长度为 4G,其区别是 BLOB 没有字符集属性,纯属二进制存储。
和 Oracle、Microsoft SQL Server 等传统关系型数据库不同的是,MySQL 数据库的 VARCHAR 字符类型,最大能够存储 65536 个字节,所以在 MySQL 数据库下,绝大部分场景使用类型 VARCHAR 就足够了。
CHAR 和 VARCHAR存储与所选字符集有关,当为变长字符集(如:GBK、UTF8MB4),其本质是一样的,都是变长,设计时完全可以用 VARCHAR 替代 CHAR;
字符集
在表结构设计中,除了将列定义为 CHAR 和 VARCHAR 用以存储字符以外,还需要额外定义字符对应的字符集,因为每种字符在不同字符集编码下,对应着不同的二进制值。常见的字符集有 GBK、UTF8,通常推荐把默认字符集设置为 UTF8。
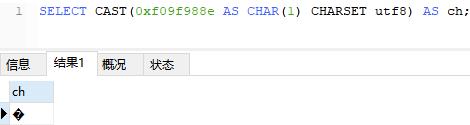
而且随着移动互联网的飞速发展,推荐把 MySQL 的默认字符集设置为 UTF8MB4,否则,某些 emoji 表情字符无法在 UTF8 字符集下存储,比如 emoji 笑脸表情,对应的字符编码为 0xF09F988E:
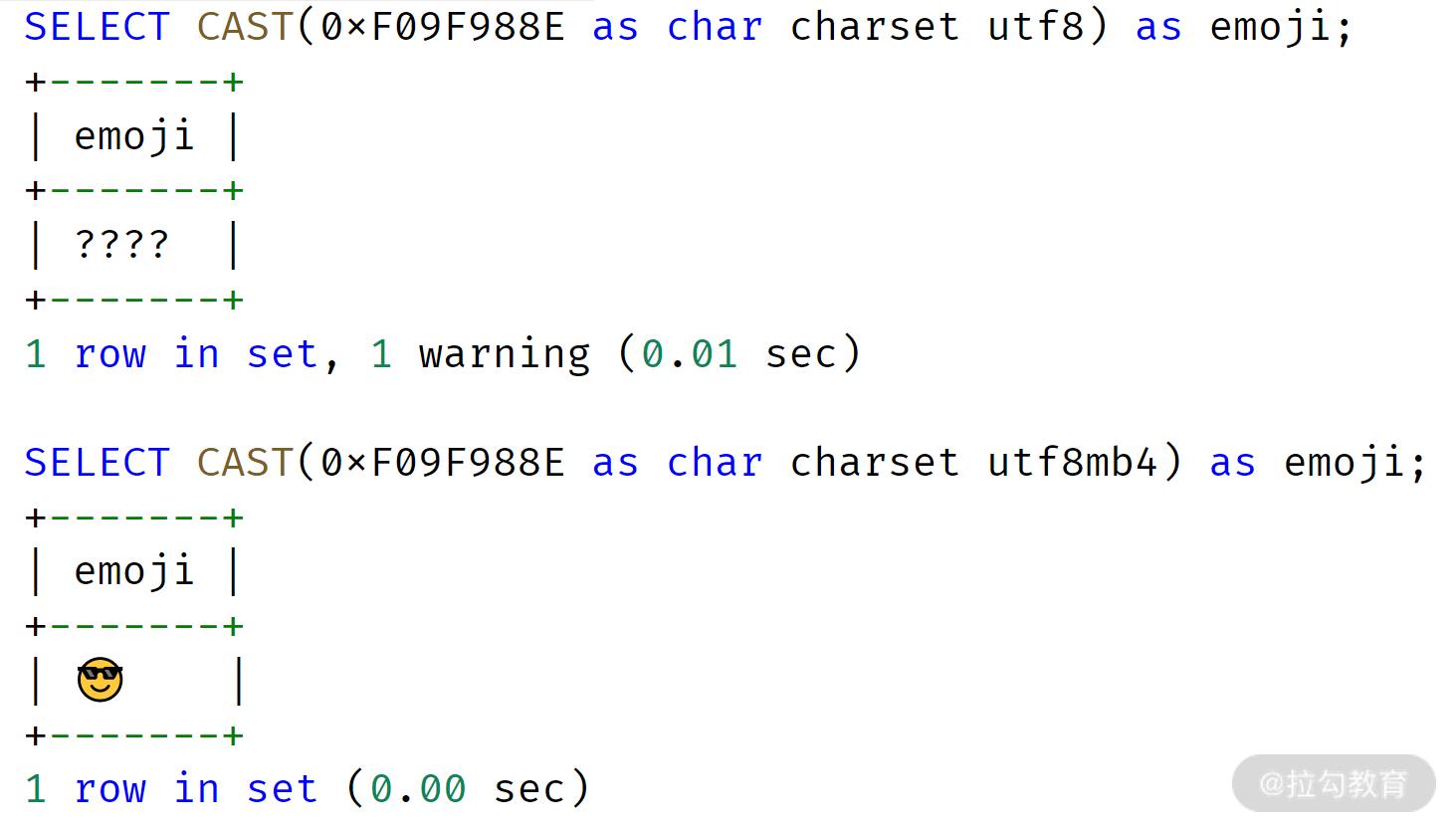
包括 MySQL 8.0 版本在内,字符集默认设置成 UTF8MB4,8.0 版本之前默认的字符集为 Latin1。因为不同版本默认字符集的不同,你要显式地在配置文件中进行相关参数的配置:
[mysqld]
character-set-server = utf8mb4
...
另外,不同的字符集,CHAR(N)、VARCHAR(N) 对应最长的字节也不相同。比如 GBK 字符集,1 个字符最大存储 2 个字节,UTF8MB4 字符集 1 个字符最大存储 4 个字节。所以从底层存储内核看,在多字节字符集下,CHAR 和 VARCHAR 底层的实现完全相同,都是变长存储!
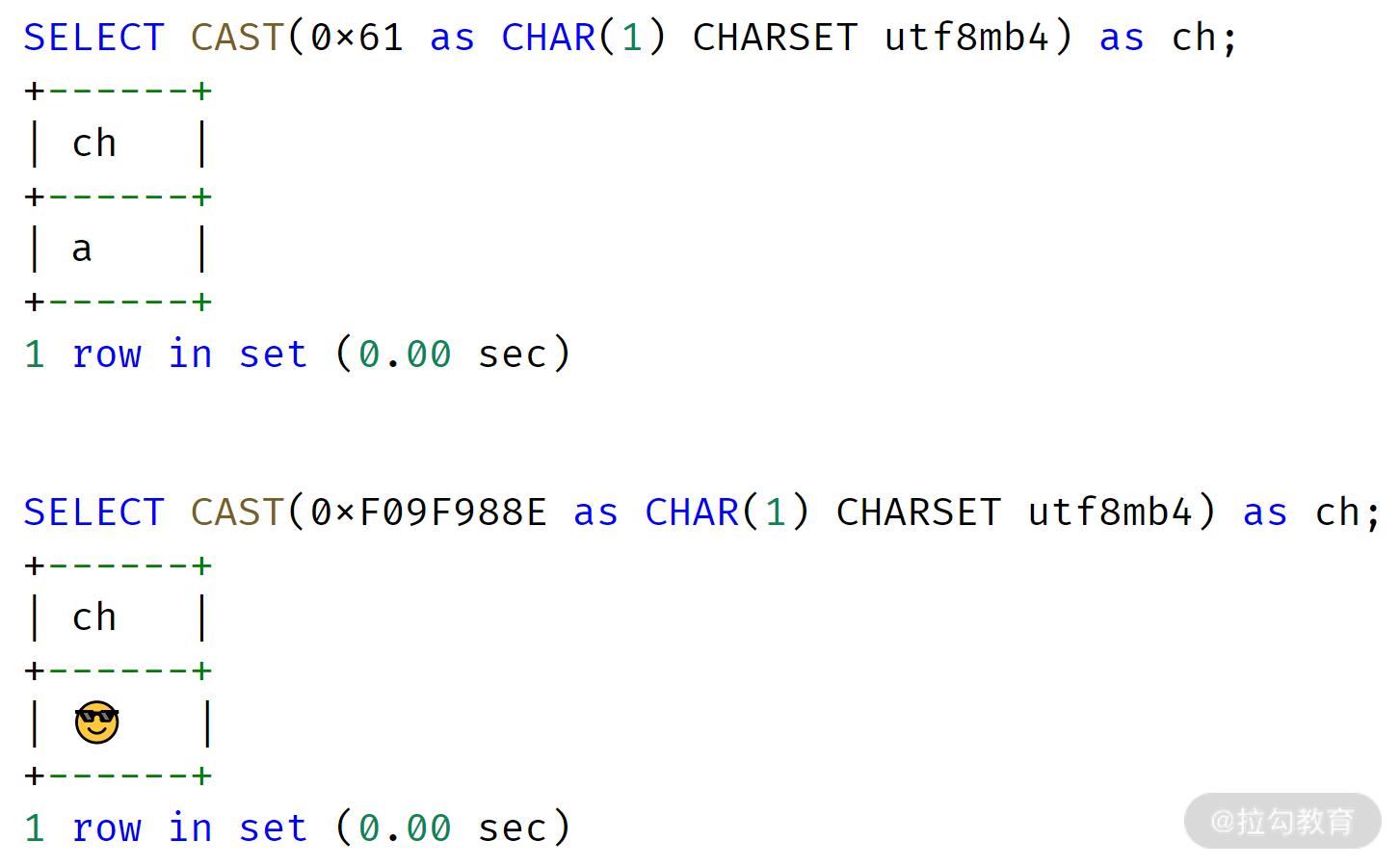
从上面的例子可以看到,CHAR(1) 既可以存储 1 个 ‘a’ 字节,也可以存储 4 个字节的 emoji 笑脸表情,因此 CHAR 本质也是变长的。
鉴于目前默认字符集推荐设置为 UTF8MB4,所以在表结构设计时,可以把 CHAR 全部用 VARCHAR 替换,底层存储的本质实现一模一样。
下面是mysql5.7版本下,char并非变长字符。
正确修改字符集
当然,相信不少业务在设计时没有考虑到字符集对于业务数据存储的影响,所以后期需要进行字符集转换,但很多同学会发现执行如下操作后,依然无法插入 emoji 这类 UTF8MB4 字符:
ALTER TABLE emoji_test CHARSET utf8mb4;
上述对于已经存在的列,其默认字符集并不做修改。
正确修改列字符集的命令应该使用 ALTER TABLE … CONVERT TO…这样才能将之前的列 a 字符集从 UTF8 修改为 UTF8MB4:
mysql> ALTER TABLE emoji_test CONVERT TO CHARSET utf8mb4;
Query OK, 0 rows affected (0.94 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> SHOW CREATE TABLE emoji_test\\G
*************************** 1. row ***************************
Table: emoji_test
Create Table: CREATE TABLE `emoji_test` (
`a` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci
1 row in set (0.00 sec)
排序规则
排序规则(Collation)是比较和排序字符串的一种规则,每个字符集都会有默认的排序规则,你可以用命令 SHOW CHARSET 来查看:
mysql> SHOW CHARSET LIKE 'utf8%';
+---------+---------------+--------------------+--------+
| Charset | Description | Default collation | Maxlen |
+---------+---------------+--------------------+--------+
| utf8 | UTF-8 Unicode | utf8_general_ci | 3 |
| utf8mb4 | UTF-8 Unicode | utf8mb4_0900_ai_ci | 4 |
+---------+---------------+--------------------+--------+
2 rows in set (0.01 sec)
mysql> SHOW COLLATION LIKE 'utf8mb4%';
+----------------------------+---------+-----+---------+----------+---------+---------------+
| Collation | Charset | Id | Default | Compiled | Sortlen | Pad_attribute |
+----------------------------+---------+-----+---------+----------+---------+---------------+
| utf8mb4_0900_ai_ci | utf8mb4 | 255 | Yes | Yes | 0 | NO PAD |
| utf8mb4_0900_as_ci | utf8mb4 | 305 | | Yes | 0 | NO PAD |
| utf8mb4_0900_as_cs | utf8mb4 | 278 | | Yes | 0 | NO PAD |
| utf8mb4_0900_bin | utf8mb4 | 309 | | Yes | 1 | NO PAD |
| utf8mb4_bin | utf8mb4 | 46 | | Yes | 1 | PAD SPACE |
......
排序规则以 _ci 结尾,表示不区分大小写(Case Insentive),_cs 表示大小写敏感,_bin 表示通过存储字符的二进制进行比较。需要注意的是,比较 MySQL 字符串,默认采用不区分大小的排序规则:
牢记,绝大部分业务的表结构设计无须设置排序规则为大小写敏感!
字符串类型案例:业务表结构设计实战
用户性别设计
我观察后发现,大多数开发人员喜欢用 INT 的数字类型去存储性别字段,其中,tinyint 列 sex 表示用户性别,但这样设计问题比较明显。
- 表达不清:在具体存储时,0 表示女,还是 1 表示女呢?每个业务可能有不同的潜规则;
- 脏数据:因为是 tinyint,因此除了 0 和 1,用户完全可以插入 2、3、4 这样的数值,最终表中存在无效数据的可能,后期再进行清理,代价就非常大了。
在 MySQL 8.0 版本之前,可以使用 ENUM 字符串枚举类型,只允许有限的定义值插入。如果将参数 SQL_MODE 设置为严格模式,插入非定义数据就会报错:
mysql> SHOW CREATE TABLE User\\G
*************************** 1. row ***************************
Table: User
Create Table: CREATE TABLE `User` (
`id` bigint NOT NULL AUTO_INCREMENT,
`sex` enum('M','F') COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB
1 row in set (0.00 sec)
mysql> SET sql_mode = 'STRICT_TRANS_TABLES';
Query OK, 0 rows affected, 1 warning (0.00 sec)
mysql> INSERT INTO User VALUES (NULL,'F');
Query OK, 1 row affected (0.08 sec)
mysql> INSERT INTO User VALUES (NULL,'A');
ERROR 1265 (01000): Data truncated for column 'sex' at row 1
自 MySQL 8.0.16 版本开始,数据库原生提供 CHECK 约束功能,可以方便地进行有限状态列类型的设计:
mysql> SHOW CREATE TABLE User\\G
*************************** 1. row ***************************
Table: User
Create Table: CREATE TABLE `User` (
`id` bigint NOT NULL AUTO_INCREMENT,
`sex` char(1) COLLATE utf8mb4_general_ci DEFAULT NULL,
PRIMARY KEY (`id`),
CONSTRAINT `user_chk_1` CHECK (((`sex` = _utf8mb4'M') or (`sex` = _utf8mb4'F')))
) ENGINE=InnoDB
1 row in set (0.00 sec)
mysql> INSERT INTO User VALUES (NULL,'M');
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO User VALUES (NULL,'Z');
ERROR 3819 (HY000): Check constraint 'user_chk_1' is violated.
账户密码存储设计
相信不少开发开发同学会通过函数 MD5 加密存储隐私数据,这没有错,因为 MD5 算法并不可逆。然而,MD5 加密后的值是固定的,如密码 12345678,它对应的 MD5 固定值即为 25d55ad283aa400af464c76d713c07ad。
因此,可以对 MD5 进行暴力破解,计算出所有可能的字符串对应的 MD5 值。若无法枚举所有的字符串组合,那可以计算一些常见的密码,如111111、12345678 等。我放在文稿中的这个网站,可用于在线解密 MD5 加密后的字符串。
所以,在设计密码存储使用,还需要加盐(salt),每个公司的盐值都是不同的,因此计算出的值也是不同的。若盐值为 psalt,则密码 12345678 在数据库中的值为:
password = MD5(‘psalt12345678’)
<以上是关于MySQL表结构设计的主要内容,如果未能解决你的问题,请参考以下文章