mysql索引性能优化之ICPMRRBKA理论加实践
Posted 是馄饨呀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mysql索引性能优化之ICPMRRBKA理论加实践相关的知识,希望对你有一定的参考价值。
(查询优化)Index Condition Pushdown (指数条件下推)(ICP)
ICP是mysql使用索引从表中检索行数据的一种优化方式。
目标
减少从基表中读取操作的数量,从而降低I/O操作。
禁用ICP
存储引擎会通过遍历索引定位基表中的行,然后返回给Server 层,在去为这些数据进行WHERE 后的条件过滤。
开启ICP特性
如果部分where 条件能够使用索引中的字段,那么 MySQLServer就会把这部分下推导存储引擎层。存储引擎通过索引过滤,把满足的行从表中读取出。
效果决定于存储引擎通过ICP筛选掉的数据的比例。如果引擎层能够过滤掉大量的数据,就能减少I/O次数、提高查询语句性能。
对于InnoDB 表,ICP只适用于辅助索引,当时用ICP优化时,执行计划的Extra列显示 Using index condition提示。
mysql开启ICP
SET optimizer_switch="index_condition_pushdown=on"
mysql关闭ICP
SET optimizer_switch="index_condition_pushdown=off"
实验举例:
一张表默认只有一个主索引,因为ICP只能作用于二级索引,所以我们建立一个二级索引。
CREATE TABLE `employees` (
`emp_no` int NOT NULL AUTO_INCREMENT,
`birth_date` date NOT NULL,
`first_name` varchar(14) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`last_name` varchar(16) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL,
`gender` enum('M','F') CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`) USING BTREE,
INDEX `first_name_last_name`(`first_name`, `last_name`) USING BTREE
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
为了明确查询性能,启用profiling并关闭Query Cache
SET profiling = 1;
SET query_cache_type = 0;
SET GLOBAL query_cache_size = 0;
但是因为我用的是8.x版本的数据库,由于在8.x版本query cache已经被废弃了,所以这里会提示为
Unknown system variable 'query_cache_size'
在SELECT * FROM employees WHERE first_name = 'Mary' AND last_name like '%man';语句中,根据MySQL索引的前缀匹配原则,两者对索引的使用是一致的,即只有first_name采用索引,last_name由于采用模糊前缀,无法使用索引进行匹配。
查询三次select,并执行show profiles.
SELECT * FROM employees WHERE first_name = 'Mary' AND last_name like '%man';
show profiles;
查看执行计划,在select前加explain就可以了.
EXPLAIN SELECT * FROM employees WHERE first_name = 'Mary' AND last_name like '%man';
同理,关闭ICP,在查询三次测试
耗时
开启ICP

关闭ICP

比较执行计划
开启ICP

关闭ICP

执行计划参数含义:
type表的连接类型,如果是ALL (最差的一种类型,从头到尾全表扫描)
key表示查询实际使用到的索引。
possible_keys列指出MySQL能使用哪个索引在该表中找到行。如果该列是NULL,则没有相关的索引。
rows表示mysql在表中进行查询时必须检查的行数。
extra列显示mysql在处理查询时的详细信息,主要包括
using index这个说明MySQL使用了覆盖索引,避免访问了表的数据行;
using where这说明服务器在存储引擎收到行后将进行过滤;
using temporary说明mysql对查询结果进行排序的时候使用了临时表,
using filesort这个说明mysql会对数据使用一个外部的排序,MySQL 中无法利用索引完成的排序操作称为“文件排序”
(查询优化)Multi-Range Read Optimization(多量程读优化)(MRR)
MRR是优化器将随机I/O转化为顺序I/O,目的是减少磁盘的随机访问,以降低查询过程中I/O的开销,对I/O-bound类型的SQL语句性能带来极大的提升。
在不使用MRR时,优化器需要根据二级索引返回的记录来进行回表,这个过程一般会有较多的随机I/O。
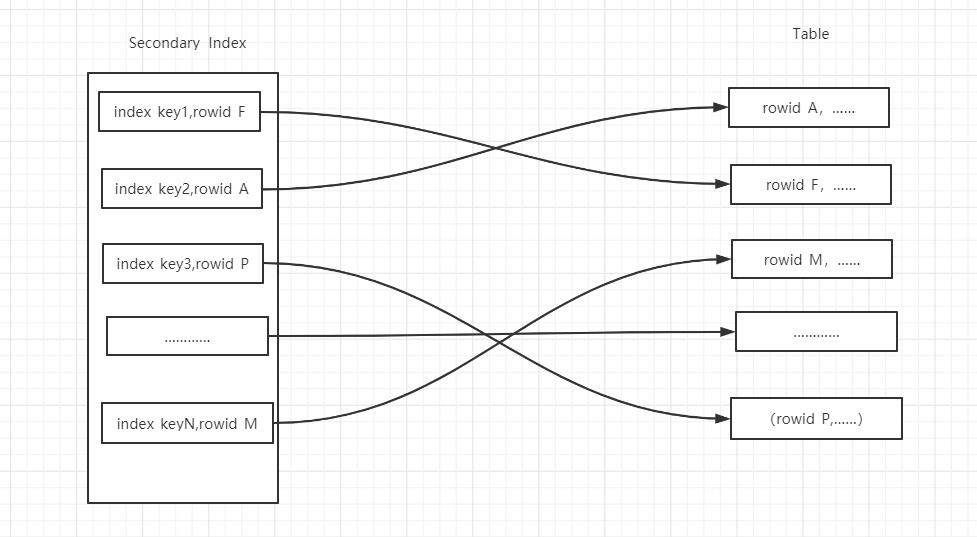
在使用MRR时,MRR的优化在于,并不是每次通过辅助索引回表取记录,而是将rowid缓存起来,然后对rowid进行排序后在去访问记录,优化器将二级索引随机的I/O进行排序,转化为主键的有序排列,从而实现随机I/O到顺序I/O的转化,大幅提升性能。
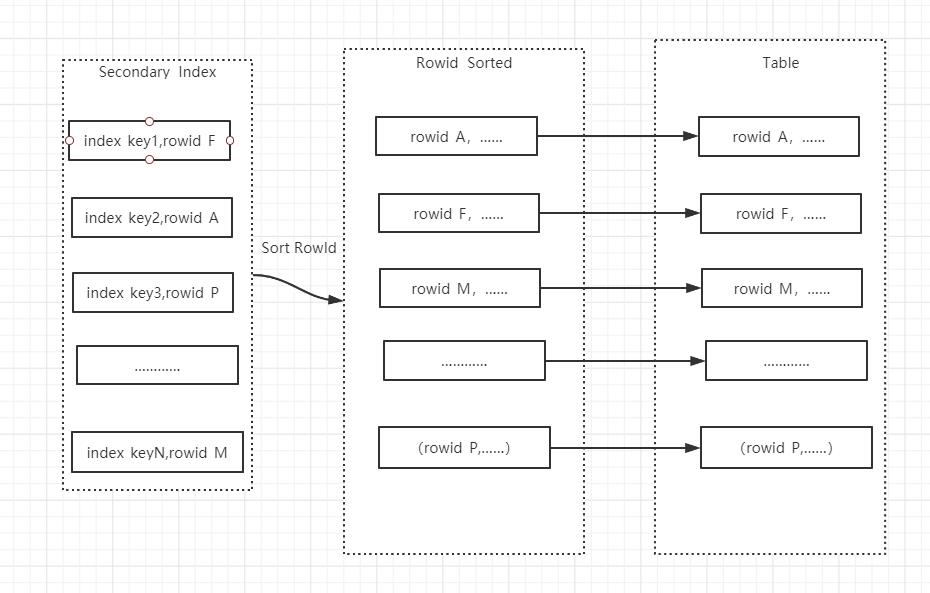
对比mrr=on 和mrr=off时的执行计划
CREATE TABLE t1
(
`id` int(11) NOT NULL AUTO_INCREMENT,
`a` int(11) DEFAULT NULL,
`b` int(11) DEFAULT NULL ,
`c` int(11) DEFAULT NULL ,
PRIMARY KEY (`id`),
KEY `mrrx` (`a`,`b`),
KEY `xx` (`c`)
);
在关掉MRR的情况下,当执行计划使用的是索引xx©,即从索引 xx 上读取一条数据后回表,取回该主键的完整数据,当数据较多且比较分散的情况下会有较多的随机I/O,导致性能低下。
SET optimizer_switch="mrr=off";
EXPLAIN SELECT * FROM t1 WHERE (a BETWEEN 1 AND 10) AND (c BETWEEN 9 AND 10);

基于成本的算法过于保守,导致大部分情况下优化器都不会选择MRR 特性。为了确保优化器使用MRR特性,需要执行 SQL 语句:
SET optimizer_switch="mrr=on,mrr_cost_based=off";

发现在Extra 的输出中多了Using MRR 信息,对MRR Optimization I/O层进行了优化,可以减少 I/O 方面的开销。
在不使用MRR之前,先根据where 条件中的辅助索引获取辅助索引与主键的集合,在通过主键来获取对应的值。利用辅助索引获取的主键来访问表中的数据会导致多次I/O 和随机读。
使用MRR 优化的好处是能使数据访问变得较有顺序。它将根据辅助索引获取的结果集根据主键进行排序,将无序化为有序,可以用主键顺序访问基表,将随机读转化为顺序读,多页数据记录可一次性读入或根据此次的主键范围分次读入,减少 I/O操作,提高查询效率。
相关参数:
mrr=on,mrr_cost_based=on: 表示cost base 的方式还选择启用MRR优化,当发现优化后的代价过高时就会不使用该项优化。
mrr=on,mrr_cost_based=off: 表示总是开启MRR优化。
(查询优化)Batched Key Access(批处理键访问)(BKA)
BKA是提高表join性能的算法,是在表连接的过程中为了提升join 性能而使用的一种 join buffer ,作用是在读取被连接表的记录时使用顺序I/O。
对于嵌套循环,如果关联的表数据量很大,那么join 关联的时间会很长,后来引入了BNL(Block Nested Loop)算法来优化嵌套循环。BNL算法通过使用在外部循环中读取行的缓冲来减少内部循环中的表必须被读取的次数。
BKA的原理是对于多表join语句,将外部表中相关的列放入join buffer 中。批量地将Key(索引键值)发送到Multi-Range Read (MRR)接口。Multi-Range Read(MRR)根据收到的Key 对应的ROWID进行排序,然后进行数据得到读取操作。
BKA join 算法将能极大地提高 SQL 的执行效率,特别是在内表上有索引并且该索引为非主键,联表需要访问内部表主键上的索引情况下。这时BKA算法会调用 Multi-Range Read (MRR)接口,批量地进行索引键的匹配和主键索引上获取数据的操作,以此来提高联接的执行效率,因为读取数据是以顺序磁盘I/O而不是随机磁盘I/O进行的。
BKA使用 join buffer size 来确定buffer的大小,buffer越大缓冲区越大,对联表操作的右侧表的顺序访问就越多,可以显著提高性能。
创建表employees.
CREATE TABLE employees (
emp_no INT NOT NULL,
birth_date DATE NOT NULL,
first_name VARCHAR(14) NOT NULL,
last_name VARCHAR(16) NOT NULL,
gender ENUM ('M','F') NOT NULL,
hire_date DATE NOT NULL,
PRIMARY KEY (emp_no)
);
创建表dept_emp
CREATE TABLE dept_emp (
emp_no INT NOT NULL,
dept_no CHAR(4) NOT NULL,
from_date DATE NOT NULL,
to_date DATE NOT NULL,
FOREIGN KEY (emp_no) REFERENCES employees (emp_no) ON DELETE CASCADE,
FOREIGN KEY (dept_no) REFERENCES departments (dept_no) ON DELETE CASCADE,
PRIMARY KEY (emp_no,dept_no)
);
启动BKA
SET optimizer_switch='mrr=on,mrr_cost_based=off,batched_key_access=on';
查询计划
EXPLAIN SELECT a.gender,b.dept_no FROM employees a,dept_emp b WHERE a.birth_date=b.from_date;
添加索引在查看查询计划
ALTER TABLE employees ADD INDEX (birth_date);
EXPLAIN SELECT a.gender,b.dept_no FROM employees a,dept_emp b WHERE a.birth_date=b.from_date;

以上是关于mysql索引性能优化之ICPMRRBKA理论加实践的主要内容,如果未能解决你的问题,请参考以下文章