妹子图爬取,即能养颜又能学技术,我真的是冲着技术来的!
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了妹子图爬取,即能养颜又能学技术,我真的是冲着技术来的!相关的知识,希望对你有一定的参考价值。
前言
爬虫是python应用的方向之一,简单易学好上手,找工作对学历要求不高,昨天有粉丝私信我想爬取一个网站,这个项目还是挺简单的,基本的爬虫流程,由于采集的数据比较多,使用多线程的方式并发下载图片。
效果展示
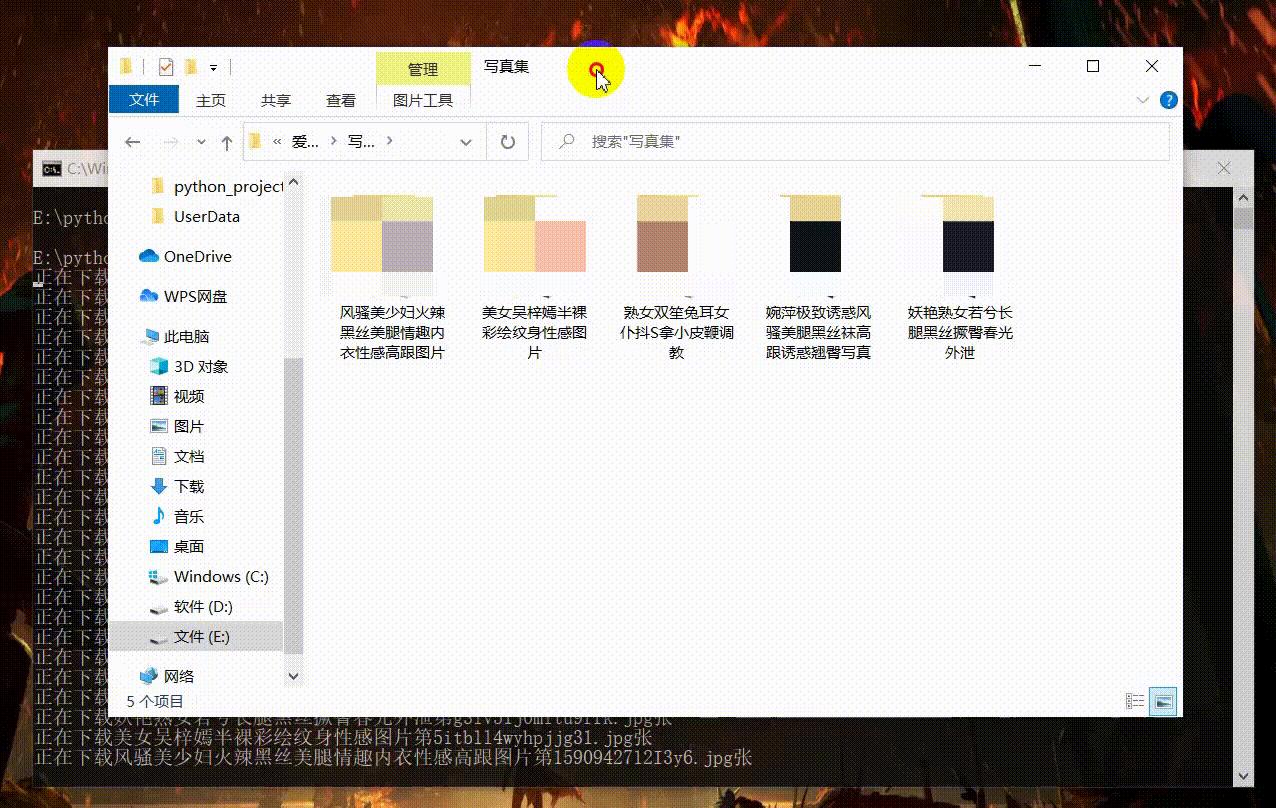
项目解析
获取到网页数据的动态链接:【图片尺度稍大 全程打码】
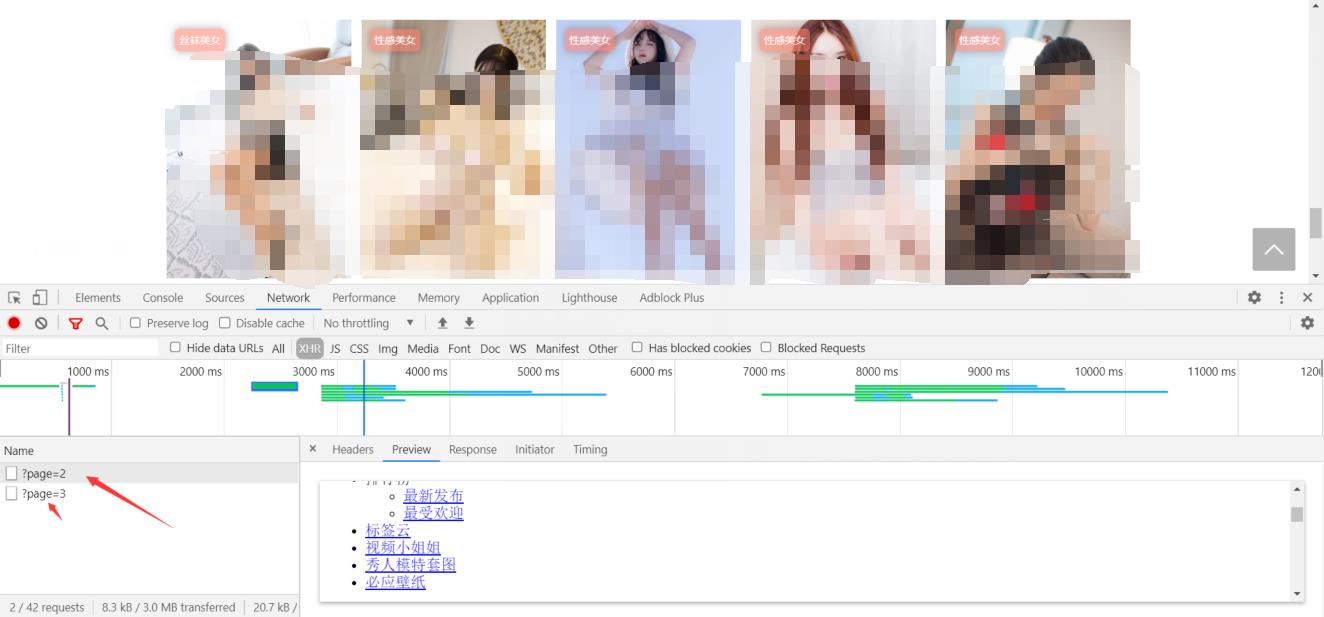
提取到主页的跳转链接和写真主题的名字
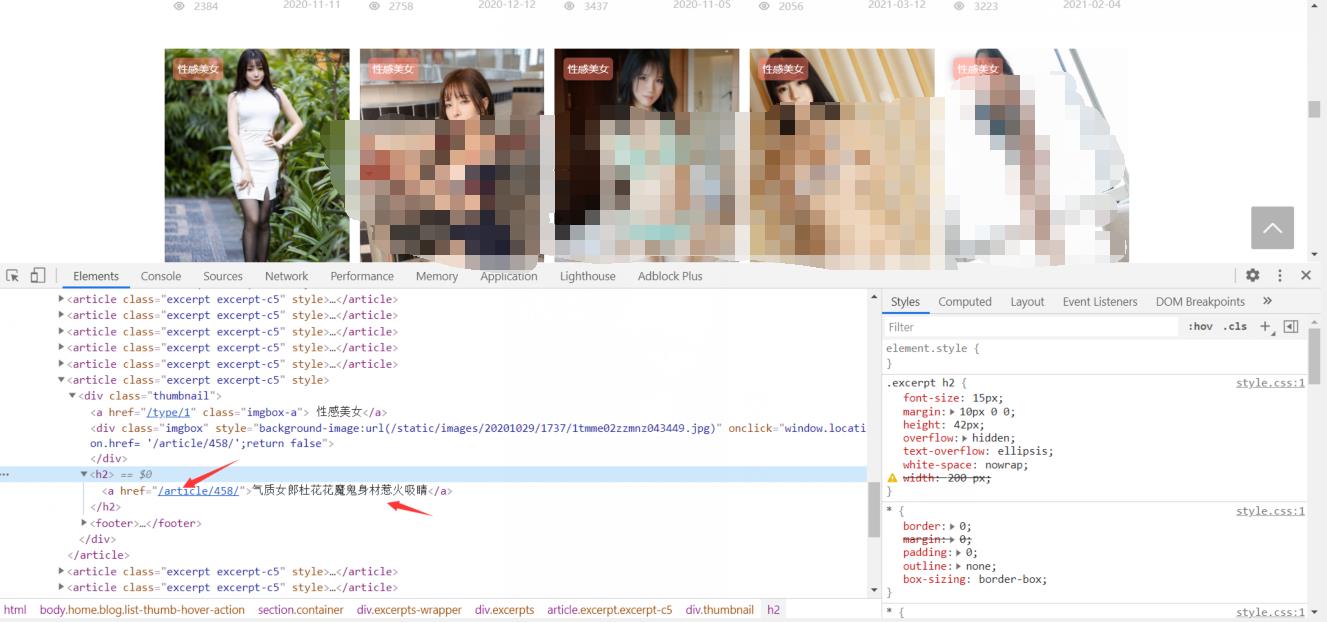
根据跳转链接进入详情页面获取详情页面的图片url
完整代码
```python
import os
import requests
from lxml import etree
import threading
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/90.0.4430.212 Safari/537.36'
}
def request_data(url):
response = requests.get(url, headers=headers)
return response
def save_data(result, path):
f = open(path, "wb")
f.write(result)
def get_data(url):
response = request_data(url)
html_data = etree.HTML(response.text)
title_list = html_data.xpath('//h2/a/text()')
detail_url_list = html_data.xpath('//h2/a/@href')
for title, detail_url in zip(title_list, detail_url_list):
path = "写真集/" + title
if not os.path.exists(path):
os.mkdir(path)
# print(title)
res = request_data('https://hwenhai-vpn01.eastasia.cloudapp.azure.com' + detail_url)
# print(res.text)
html = etree.HTML(res.text)
img_url_list = html.xpath('//article/p/img/@data-src')
for img_url in img_url_list:
name = img_url.split('/')[-1]
result = request_data('https://hwenhai-vpn01.eastasia.cloudapp.azure.com/' + img_url).content
save_data(result, path + "//" + name)
print("正在下载{}第{}张".format(title, name))
if __name__ == '__main__':
for i in range(1, 10):
url = "https://hwenhai-vpn01.eastasia.cloudapp.azure.com/?page={}".format(i)
t1 = threading.Thread(target=get_data, args=(url, ))
t1.start()
小结
这个项目没什么技术难点,属于最简单的爬虫项目了,后面会出一些难度更高的比如JS反爬之类的。希望大家多多关注,不对的地方欢迎指出评论中交流,此文章仅供学习交流。
以上是关于妹子图爬取,即能养颜又能学技术,我真的是冲着技术来的!的主要内容,如果未能解决你的问题,请参考以下文章