Java经典面试题汇总容器
Posted javanbme
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java经典面试题汇总容器相关的知识,希望对你有一定的参考价值。
本篇总结的是Java容器相关的面试题,后续会持续更新,希望我的分享可以帮助到正在备战面试的实习生或者已经工作的同行,如果发现错误还望大家多多包涵,不吝赐教,谢谢~

目录
2. ArrayList 和 LinkedList 的区别是什么
4. 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
8. Collection 和 Collections 有什么区别?
12. Comparable和Comparator接口有何区别?
13. HashMap、Hashtabl、ConcurrentHashMap的区别?
15. 为什么更改 equals() 一定要改 hashCode()?
24. 在 Queue 中 poll()和 remove()有什么区别?
26. ArrayList 和 Vector 的区别是什么?
29. Iterator 和 ListIterator 有什么区别?
32. 为什么集合没有继承Cloneable和Serializable接口?
1. Java 容器都有哪些?
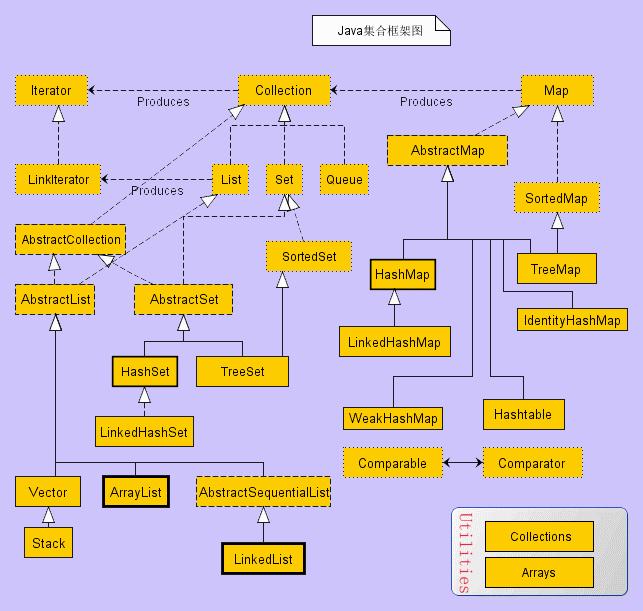
Java 容器分为 Collection 和 Map 两大类,其下又有很多子类,如下所示:
- Collection
- List
- ArrayList
- LinkedList
- Vector
- Stack
- Set
- HashSet
- LinkedHashSet
- TreeSet
- Map
- HashMap
- LinkedHashMap
- TreeMap
- ConcurrentHashMap
- Hashtable
2. ArrayList 和 LinkedList 的区别是什么
主要体现以下三个维度(数据结构,执行效率,控件开销)
- ArrayList 是动态数组的数据结构实现,而 LinkedList 是双向链表的数据结构实现。
- 在随机访问的时候,ArrayList 比 LinkedList 效率要高,因为 LinkedList 是线性的数据存储方式,所以需要移动指针从前往后依次查找。
- 在非首尾的增加和删除操作,LinkedList 要比 ArrayList 效率要高,因为 ArrayList 增删操作要影响数组内的其他数据的下标。
- LinkedList比ArrayList控件开销大,因为LinkedList的节点除了存储数据,还需要存储结点的指针信息。
综合来说,在需要频繁读取集合中的元素时,更推荐使用 ArrayList,而在插入和删除操作较多时,更推荐使用 LinkedList。
3. 说一下HashMap的工作原理?
HashMap是基于hashing的原理,我们使用put(key, value)存储对象到HashMap中,使用get(key)从HashMap中获取对象。
当我们给put()方法传递键和值时,我们先对键调用hashCode()方法,计算并返回的hashCode是用于找到Map数组的bucket位置来储存Node对象。
当我们调用get()方法,HashMap会使用键对象的hashcode找到bucket位置,找到bucket位置之后,会调用keys.equals()方法去找到链表中正确的节点,最终找到要找的值对象
以下是Jdk 1.8具体put()的过程
1、对Key求Hash值,然后再计算下标
2、如果没有碰撞,直接放入桶中(碰撞的意思是计算得到的Hash值相同,需要放到同一个bucket中)
3、如果碰撞了,以链表的方式链接到后面
4、如果链表长度超过阀值( TREEIFY THRESHOLD==8),就把链表转成红黑树,链表长度低于6,就把红黑树转回链表
5、如果节点已经存在就替换旧值
6、如果桶满了(容量16*加载因子0.75),就需要 resize(扩容2倍后重排)
扩展:
4. 如果HashMap的大小超过了负载因子(load factor)定义的容量,怎么办?
默认的负载因子大小为0.75,也就是说,当一个map填满了75%的bucket时候,和其它集合类(如ArrayList等)一样,将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。这个值只可能在两个地方,一个是原下标的位置,另一种是在下标为<原下标+原容量>的位置
5. 为什么HashMap不是线程安全的?
线程T1和T2同时对一个HashMap进行put操作,如产生hash碰撞,正常情况下,会形成链表,并发情况下,有可能T2线程会覆盖T1线程put的元素。
线程T1和T2同时对一个HashMap进行resize操作,因jdk1.7中,扩容时,移动元素生成新链表是按头插法进行的,可能出现循环链表,使得get一个不存在的元素,且该元素索引位置在循环链表位置时,造成对环形链表的死循环遍历,在jdk1.8中不会。
所以,HashMap的线程不安全主要体现如下:
- 在JDK1.7中,当并发执行put操作时,会造成数据丢失,并发扩容操作时会造成死循环的情况。
- 在JDK1.8中,当并发执行put操作时,也会造成数据丢失,但不会形成环形链表,所以不会出现死循环情况。
6. 有什么方法可以减少Hash碰撞?
扰动函数可以减少碰撞,原理是如果两个不相等的对象返回不同的hashcode的话,那么碰撞的几率就会小些,这就意味着存链表结构减小,这样取值的话就不会频繁调用equal方法,这样就能提高HashMap的性能。(扰动即Hash方法内部的算法实现,目的是让不同对象返回不同hashcode。)
使用不可变的、声明作final的对象,并且采用合适的equals()和hashCode()方法的话,将会减少碰撞的发生。不可变性使得能够缓存不同键的hashcode,这将提高整个获取对象的速度,使用String,Interger这样的wrapper类作为键是非常好的选择。为什么String, Interger这样的wrapper类适合作为键?因为String是final的,而且已经重写了equals()和hashCode()方法了。不可变性是必要的,因为为了要计算hashCode(),就要防止键值改变,如果键值在放入时和获取时返回不同的hashcode的话,那么就不能从HashMap中找到你想要的对象。
7. 哪些集合是线程安全的?
Vector:比Arraylist多了个同步化机制(线程安全)
Hashtable:比Hashmap多了个线程安全
ConcurrentHashMap: 是一种高效但是线程安全的集合
Stack:栈,也是线程安全的,继承于Vector
8. Collection 和 Collections 有什么区别?
Collection 是一个集合接口,它提供了对集合对象进行基本操作的通用接口方法,所有集合都是它的子类,比如 List、Set 等。
Collections 是一个包装类,包含了很多静态方法,不能被实例化,就像一个工具类,比如提供的排序方法: Collections. sort(list)。
9. List、Set、Map 之间的区别是什么?

10. 数组和集合有什么区别?
- 数组声明了它容纳的元素的类型,而集合不声明。
- 数组是静态的,一个数组实例具有固定的大小,一旦创建了就无法改变容量了。而集合是可以动态扩展容量,可以根据需要动态改变大小,集合提供更多的成员方法,能满足更多的需求。
- 数组的存放的类型只能是一种(基本类型/引用类型),集合存放的类型可以不是一种(不加泛型时添加的类型是Object)。
- 数组是java语言中内置的数据类型,是线性排列的,执行效率或者类型检查都是最快的。
11. 如何对Obiect的list排序?
对于object数组进行排序,可以使用Arrays.sort()方法,如果我们要对object的集合进行排序,我们需要的是使用collections.sort()方法。
12. Comparable和Comparator接口有何区别?
Comparable和Comparator接口被用来对对象集合或者数组进行排序。Comparable接口被用来提供对象的自然排序,我们可以使用它来提供基于单个逻辑的排序。
Comparator接口被用来提供不同的排序算法,我们可以选择需要使用的Comparator来对给定的对象集合进行排序。
13. HashMap、Hashtabl、ConcurrentHashMap的区别?
HashMap
- jdk1.7底层使用数组+单链表的形式存储数据,而jdk1.8是用数组+单链表+红黑树存储数据。
- 读写方法都没加锁,所以是非线程安全的。
- 可以存储key和value为null的元素。
- 初始容量DEFAULT_INITIAL_CAPACITY=16。
- 默认负载因子 loadFactor=DEFAULT_LOAD_FACTOR = 0.75f
- 扩容条件为:(size >= threshold) && (null != table[bucketIndex]),其中threshold是临界值threshold=Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
- 扩容函数resize(),阔容大小:newCapacity = 2 * table.length,即两倍阔容,且容量一定为2的n次幂。
- 扩容针对整个Map,每次扩容时,通过transfer()将原来数组中的元素依次重新计算存放位置,并重新插入。
- 计算index的方法indexFor():index = hash & (tab.length – 1).
Hashtable
- 是由数组+单链表方式实现。
- 在对外的函数上加了synchronized重入锁,而且锁的是Entry<?,?>[] table的全部数据,所以是线程安全的。
- 键和值都不能null
- 默认的初始容量为11,负载因子为0.75f.
- 扩容条件:count >= threshold,count记录容器中实际存储的数量,等价于HashMap中size。
- 每次使用rehash() 方法扩容,扩容大小:newCapacity = (oldCapacity << 1) + 1,每次进行两倍+1扩容。
- 扩容针对整个Map,每次扩容时,直接在rehash()将原来数组中的元素依次重新计算存放位置,并重新插入。
- 计算index的方法:index = (hash & 0x7FFFFFFF) % tab.length。
ConcurrentHashMap
- 存储方式和HashMap一样。
- 通过把整个Map分为N个Segment,通过用ReentrantLock重入锁对写操作的segmet加锁,来保证线程安全,但是效率提升N倍,默认提升16倍。(读操作不加锁,由于HashEntry的value变量是 volatile的,也能保证读取到最新的值。)
- 键和值都不能null。
- Hashtable的synchronized是针对整张Hash表的,即每次锁住整张表让线程独占,ConcurrentHashMap允许多个修改操作并发进行,其关键在于使用了锁分离技术。
- 有些方法需要跨段,比如size()和containsValue(),它们可能需要锁定整个表而而不仅仅是某个段,这需要按顺序锁定所有段,操作完毕后,又按顺序释放所有段的锁。
14. 如何实现一个线程安全的HashMap?
Map<String, String> synchronizedHashMap = Collections.synchronizedMap(new HashMap<String, String>());
调用synchronizedMap()方法后会返回一个SynchronizedMap类的对象,而在SynchronizedMap类中使用了synchronized同步关键字来保证对Map的操作是安全的。
15. 为什么更改 equals() 一定要改 hashCode()?
首先基于一个假设:任何两个 object 的 hashCode 都是不同的。也就是 hash function 是有效的。
那么在这个条件下,有两个 object 是相等的,那如果不重写 hashCode(),算出来的哈希值都不一样,就会去到不同的 buckets 了,就迷失在茫茫人海中了,再也无法相认,就和 equals() 条件矛盾了,证毕。
hashCode()决定了key放在这个桶里的编号,也就是在数组里的index;equals()是用来比较两个object是否相同的
jdk注释规范也有说到:
1、equals相等,则hashCode必须相等,所以,重写了equals,一般来说都需要重写hashCode方法来满足同等性。
扩展: 两个对象的hashCode()相同时,equals()相等吗?
16. 如何决定使用 HashMap 还是 TreeMap
对于在 Map 中插入、删除、定位一个元素这类操作,HashMap 是最好的选择,因为相对而言 HashMap 的插入会更快, 但如果你要对一个 key 集合进行有序的遍历,那 TreeMap 是更好的选择。
17. HashMap 多线程操作导致死循环问题
主要原因在于并发下的Rehash 会造成元素之间会形成一个循环链表。不过,jdk 1.8 后解决了这个问题,但是还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题比如数据丢失。并发环境下推荐使用 ConcurrentHashMap 。
18. ConcurrentHashMap原理分析
ConcurrentHashMap使用分段锁技术,将数据分成一段一段的存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他段的数据也能被其他线程访问,能够实现真正的并发访问,ConcurrentHashMap内部分为很多个Segment,每一个Segment拥有一把锁,然后每个Segment(继承ReentrantLock)Segment继承了ReentrantLock,表明每个segment都可以当做一个锁。(ReentrantLock前文已经提到,不了解的话就把当做synchronized的替代者吧)这样对每个segment中的数据需要同步操作的话都是使用每个segment容器对象自身的锁来实现。
19. 说一下 HashSet 的实现原理?
HashSet 是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单, 相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,HashSet 不允许重复的值。
20.TreeSet和HashSet的区别
- TreeSet是基于 TreeMap 实现的,也就是红黑树,能够实现自动排序。通过equals和compareTo方法进行内容的比较,默认不可以接受null值,会直接抛出空指针异常。
- HashSet是基于 HashMap 实现的,key是无序的,只能做外部排序。既然是Hash,那么就要重写其对象的hashCode和equals方法,可以接受null值,有且只有一个。
21. HashSet如何检查重复?
当你把对象加入HashSet时,HashSet会先计算对象的hashcode值来判断对象加入的位置,同时也会与其他加入的对象的hashcode值作比较,如果没有相符的hashcode,HashSet会假设对象没有重复出现。但是如果发现有相同hashcode值的对象,这时会调用equals()方法来检查hashcode相等的对象是否真的相同。如果两者相同,HashSet就不会让加入操作成功。
22. EnumSet是什么?
java.util.EnumSet是使用枚举类型的集合实现。当集合创建时,枚举集合中的所有元素必须来自单个指定的枚举类型,可以是显示的或隐示的。EnumSet是不同步的,不允许值为null的元素。它也提供了一些有用的方法,比如copyOf(Collection c)、of(E first,E…rest)和complementOf(EnumSet s)。
23. 说一下LinkedHashSet
LinkedHashSet是一个非线程安全的集合,底层使用LinkedHashMap存储元素,具有set集合不重复的特点,同时具有可预测的迭代顺序,也就是我们插入的顺序。
24. 在 Queue 中 poll()和 remove()有什么区别?
相同点:都是返回第一个元素,并在队列中删除返回的对象。
不同点:如果没有元素 poll()会返回 null,而 remove()会直接抛出 NoSuchElementException 异常。
25. 队列和栈是什么,列出它们的区别?
栈和队列两者都被用来预存储数据。java.util.Queue是一个接口,它的实现类在Java并发包中。队列允许先进先出(FIFO)检索元素,但并非总是这样。Deque接口允许从两端检索元素。
栈与队列很相似,但它允许对元素进行后进先出(LIFO)进行检索。
Stack是一个扩展自Vector的类,而Queue是一个接口。
26. ArrayList 和 Vector 的区别是什么?
- 线程安全:Vector 使用了 Synchronized 来实现线程同步,是线程安全的,而 ArrayList 是非线程安全的。
- 性能:ArrayList 在性能方面要优于 Vector。
- 扩容:ArrayList 和 Vector 都会根据实际的需要动态的调整容量,只不过在 Vector 扩容每次会增加 1 倍,而 ArrayList 只会增加 50%。
27. Array 和 ArrayList 有何区别?
- Array 可以存储基本数据类型和对象,ArrayList 只能存储对象。
- Array 是指定固定大小的,而 ArrayList 大小是自动扩展的。
- Array 内置方法没有 ArrayList 多,比如 addAll、removeAll、iteration 等方法只有 ArrayList 有。
28. 迭代器 Iterator 是什么?
Iterator 接口提供遍历任何 Collection 的接口。我们可以从一个 Collection 中使用迭代器方法来获取迭代器实例。 迭代器取代了 Java 集合框架中的 Enumeration,迭代器允许调用者在迭代过程中移除元素。 Iterator 的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。
29. Iterator 和 ListIterator 有什么区别?
- Iterator 可以遍历 Set 和 List 集合,而 ListIterator 只能遍历 List。
- Iterator 只能单向遍历,而 ListIterator 可以双向遍历(向前/后遍历)。
- ListIterator 从 Iterator 接口继承,然后添加了一些额外的功能,比如添加一个元素、替换一个元素、获取前面或后面元素的索引位置。
30. 泛型集合框架的好处是什么呢?
Java 1.5中附带泛型和所有收集接口和接口实现的大量使用。泛型允许我们提供一个集合可以包含Object类型,所以如果你尝试添加任何其他类型的元素,它会引发编译时错误。这就避免了在运行时抛出,因为你会得到编译错误。泛型使代码更干净,因为我们并不需要使用溯型casting和instanceof检查。它也增加了运行时的好处,因为不生成的做类型检查字节码指令。
31. 怎么确保一个集合不能被修改?
可以使用 Collections. unmodifiableCollection(Collection c) 方法来创建一个只读集合, 这样改变集合的任何操作都会抛出 Java. lang. UnsupportedOperationException 异常。
32. 为什么集合没有继承Cloneable和Serializable接口?
Collection接口指定一组称为元素的对象。元素如何被组织取决于具体实现。例如,一些LIST实现允许重复的元素,而SET不允许。Collection是一种抽象表示,而克隆和序列化重在执行,应该是在Collection具体实现子类中根据具体元素组织情况来实现。因此,强制在所有实现都要有克隆和序列化是不够灵活的,具有限制性。
以上是关于Java经典面试题汇总容器的主要内容,如果未能解决你的问题,请参考以下文章