KMP模式匹配算法简单概述(c语言实现)
Posted 田啊田
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KMP模式匹配算法简单概述(c语言实现)相关的知识,希望对你有一定的参考价值。
KMP模式匹配算法
朴素的字符串模式匹配算法一般来说比较低效,所以在很多年前的科学家们为了改变这种糟糕的遍历算法,于是有是三位大牛前辈(D.E.Knuth,J.H.Morris,V.R.PRAT T)发表了一个模式匹配算法,可以尽可能的避免重复遍历的情况,这就是克努特-莫里斯-普拉特算法,简称KMP算法。
一.朴素模式匹配算法
假设我们要查找的是在S字符串中T字符串的位置,则我们把S称为主串,T称为子串。如果在主串S=“zhijingkmp”,子串T=“jing”中要查找子串“jing”的位置,按照一般的方法很简单,就是一个字符一个字符的对比,直到找到“jing”的位置,我们很容易的找的它的结果为主串中的第四个,但是在计算机中可就没这么容易的找的这个结果。
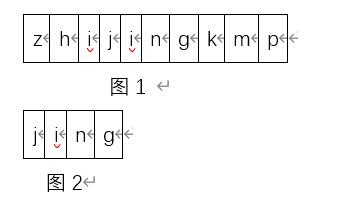
在图1 和图2 首先比较主串S和子串T中的第0 位,也就是“z”和“j“然后计算机发现它们并不相等,接着T与S比较它们的第二位,直到它们的第四位,计算机发现他们相同后进行向后移位并比较的操作,直到发现子串T与主串S的四到七的字符全部相同然后返回结果4,这种方法也称暴力求解法。是不是感觉它很慢,要不断的比较,甚至还没我们用眼睛找的快,要是没有也没关系,我们来看第二个例子。
找到主串S=“haehadkhaed“中子串T=”haed“的位置
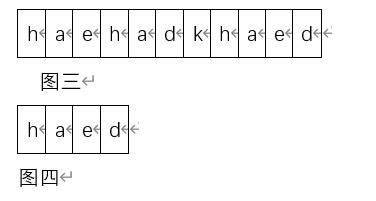
这个对我们来说也很容易,结果为八,即子串T在主串S的第八个位置开始,但是对于计算机来说就不是上面那个例子那么简单了。
计算机先比较S和T的第一位第二位第三位判断它们相同后比较第四位判断后发现它们并不相同,这时计算机该怎么做呢?
计算机通过判断后发现两者并不相同,于是子串T会回到它的首位并与主串的第二位开始比较,可以看到这时的字串T从第四位回到了第一位,主串S从第四位回到了第二位,并重复执行上述的操作。
这时我们会感觉这步骤是多余的,是不是可以简化这些步骤,是的,这种暴力破解的方法确实麻烦,可以看出这种的算法时间复杂度为O(n+m)在文本编辑等场合效率较高时(n,m分别为主串和子串的长度),而最难的情况下是O(n*m)这发生在算法的效率最低的情况下。而它的空间复杂度为O(1)即它是一个不消耗空间而消耗时间的算法。我们可能会想到这样的优化算法,既然我们人找的这么快,那能不能把我们的思维转化为算法,这样在字符串数较大的情况下我们也不必采用复杂的暴力破解法,也不用我们亲自的找。(相信很多人都有这样的经历,在上课期间,不小心走神时候,老师突然说“把这段话划下来,这是我们的期末考试重点“这时我们会非常着急的找这段话在课本的哪里,当然,这种情况我一般都是直接看同桌的。)
二.优化的查找字符串方法(KMP算法)
现在我们把人类的思维转化为算法,让大家不必在上课时着急的找考试内容的位置。
我们先来看这个例子,主串S=“aaaab“中找子串T=”aab“的位置。
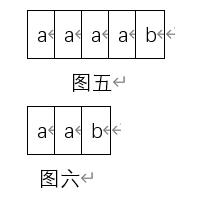
首先计算机比较到第三位后发现两者不相同,但是我们发现主串的第二三位(位置可以用i来标识)和子串的第一二位(位置可以用j来标识)是相同的,于是我们下意识就是用子串的第二位去与主串的第三位相比,然后发现第三位也不匹配可知结果也不相同,最后与第四五位相比的判断结果是正确的,于是返回结果为三。
也就是说我们在比较是否相同时,当字符不等时子串该向右移动多远,这就是我们人的优势,大脑下意识的做出了判断,而在计算机中却没有这种优势。
假如现在应该是子串中的第k(k<j)位和主串中的第i位做比较,由子串中不可能存在(k<k)可知:
子串的前k-1位和主串的第i位的前i-k+1位相同,即:
“T1T2……T(k-1)”=“S(i-k+1)S(i-k+2)……S(i-1)” (1)
而在匹配的过程中已经得到了“部分匹配”结果的是
“T1T2……T(j-k+1)T(j-k+2)……T(j-1)”=“S(i-j+1)S(i-j+2)……S(i-k+1)S(i-k+2)……S(i-1)” (2)
通过(1)和(2)可得到:
“T1T2……T(k-1)”=“T(j-k+1)T(j-k+2)……T(j-1)” (3)
若子串中存在满足(3)的两个子串,则当匹配过程中,主串的第i个元素与子串中的第j个元素不相同时,那么就把子串向右移动到第k个位置的字符和主串中的第i个位置的字符对齐,即k是j的下一步比较的位置,而此时子串中前k-1个字符一定与主串中的i的前k-1个字符相等。
那么可以知道匹配就仅从子串的第k位置和主串的第i个位置相比,子串回溯而主串不回溯。
那么我们怎么知道子串的下一次的k值是多少呢?
如果我们把子串各个位置的j值变化定义为数组next,那么next的长度就是子串的长度。即next[j]=k,第i个数值不相等时在子串中需要重新与主串中第i的值比较的字符的位置。于是我们可以得到以下的函数定义:
**
0 当j=1时
Next[j]max{k|1<k<j,且T1T2……T(k-1)=“T(j-k+1)……T(j-1)”}当此集合不为空时
1 其他情况
**
这时我们称子串的前k-1的字符为前缀,而(j-k+1)到(j-1)的字符为后缀。可以看出就是简单的比较子串中前几个字符与靠近j的多少个字符是相等的。
在形式上KMP算法与朴素的匹配算法相似,不同之处仅在于:当比较不相同的字符的时候,主串中的i不变,而子串中的j退回到next[j]所指示的位置,并且当j退回到0(当上一次比较j=1)的时候,i和j都加1,即子串中的第1个字符与主串中的第i+1个字符进行比较。
整个算法的时间复杂度为O(n+m),但是要注意的是KMP算法仅当子串与主串之间存在许多“部分匹配”的情况下才体现出它的优势,否则两者差异并不明显。
现在我们来看看代码该如何实现。
/*返回子串T的next数组*/
void get_next(String T,int *next)
{ int i ,j;
i=1;
j=0;
next[1]=0;
while(i<T[0])/*T[0]表示子串T的长度*/
{
If (j==0||T[i]==T[j])/*T[i]表示后缀的单个字符T[j]表示前缀的单个字符*/
{
++i;
++j;
next[i]=j;
}
else
j=next[j];
}
}
/*返回子串T在主串S中第pos个字符之后的位置。若不存在,则函数返回值为0 T非空,1<=pos<=StrLength(s)*/
int Index_KMP(String S,String T,int pos)
{
int i=pos;
int j=1;
int next[255];
get_next(T,next);
while(i<=S[0]&&j<=T[0])
{
if (j==0||S[i]=S[j])
{
++i;
++j;
}
Else
{
j=next[j];/*j退回合适的合适的位置,i值不变*/
}
}
if (j>T[0])
return i-T[0];
else
return o;
}
好了,KMP算法就到此结束了,但是这也许还不是最好最完善的算法,我们可以考虑这样几个问题。
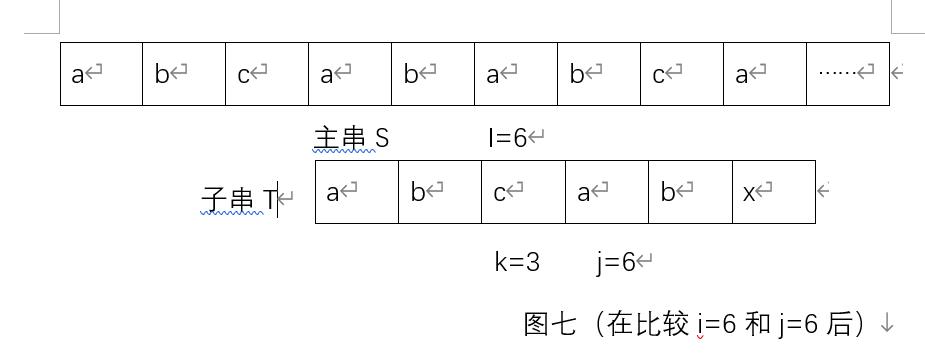
不知道我们是否发现图五,图六中比较也比较麻烦,是不是还能再优化优化?或者说我们是不是有更简单更好理解的匹配算法思想?
以上是关于KMP模式匹配算法简单概述(c语言实现)的主要内容,如果未能解决你的问题,请参考以下文章