性能场景之异常场景设计及分析
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能场景之异常场景设计及分析相关的知识,希望对你有一定的参考价值。
一、前言
今天来说下异常场景设计,和什么情况下异常场景执行算是通过。
从性能实施的角度来说,异常场景基本上几个古老的手段:
-
宕主机( reboot 和断电(一般人不这么干,是怕断了电,再也起不来));
-
宕应用( Kill 和正常 shutdown)
-
宕网络(ifconfig down 和拨网线);
其实不止这些手段来做异常,像:
- 模拟网络抖动
- 模拟 IO、CPU 满负荷(有人问为啥不模拟内存满负荷,说实话,个人除了因为不喜欢之外,还觉得没这个必要)
- 模拟各业务层超时(这个和宕应用不一样,这是处理不过来)
- 模拟全链路流控
- …
其实我还能写出一堆做异常的 case 来。
二、一个实例
那异常应该怎么着才算是 case 通过呢?今天聊一个实际的case。
先来看一个结果。
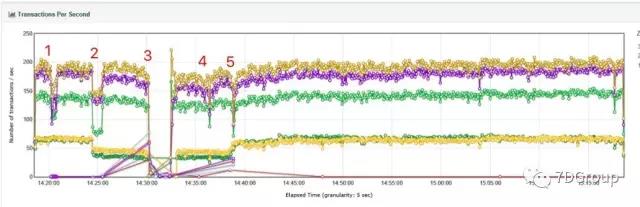
这个结果,我刚看的时候,直接认为的是:没毛病
但是在我写分析部分的时候,仔细看了下这个图,觉得不对,还是有毛病的。
为啥呢?
先说下拓扑图:
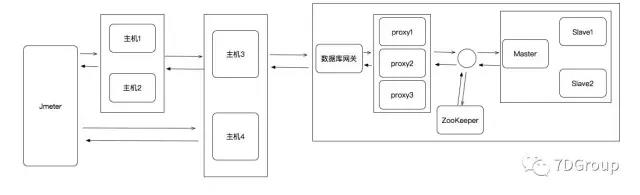
就是说,4台应用服务器,主机1、2做 LB,主机3、4做 LB;DB那边是一主两从。
Jmeter 有两种类型的脚本:http 协议连主机1、2和 Java socket 直连主机3、4。
这个异常的场景步骤是啥呢?
- kill 主机 1 上的应用
- kill 主机 3 上的应用
- reboot DB master 主机
- 启动主机 1 上的应用
- 启动主机 3 上的应用
上面那个结果中共有五个红色的数字,一一对应上面的五个步骤
看到这里,基本上有经验的人对着拓扑和结果图就能看出来问题了
先说第一个问题
为什么下面黄色和深绿色的两条线在 kill 主机 3 上的应用之后 TPS 不上去,直到第5步启动了主机3上的应用之后,才上去了呢?
与此同时,走 http 协议的三个脚本,在步骤 1、2 上和预期差不多,在正常的时间里恢复了
是呀,那是不是就可以说明主机3、4 其实切换不了呢?为了验证这一段,我让同事做了个实验,就是只验证下面两个脚本。步骤也只有一个就是 kill 主机 3 上的应用。看能不能恢复。结果如下:
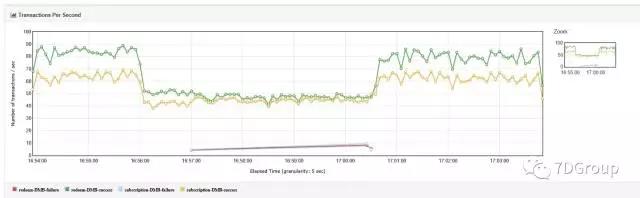
自从 kill 了主机 3 上的应用,就没恢复过,直到启动主机 3 上的应用。
再一次证明了确实没有恢复得过来。证据确凿确凿的,我就让执行这个场景的姑娘跟开发沟通一下结果,让他们查查原因。
是不是真的这样呢?后面开发过来找我说,一台主机能支持的最大 TPS 就是低谷的这么多,所以宕了一个主机后,看似流量没有被主机 4 接管。但实际上是接管了,只是 TPS 看不出来
一听,好像很有道理呀。我让这个开发和测试人员回去再做一个场景,要是能证明开发所说,这个异常切换就算成功。
怎么验证呢?就是把 TPS 降到 20,并且只用一个脚本。再来一遍:
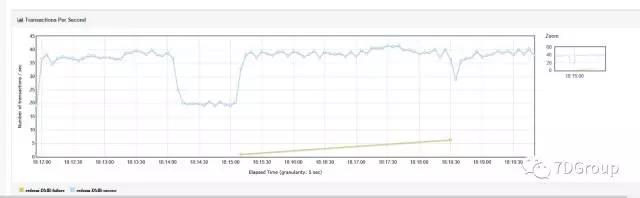
果然,真的恢复了。他们发这个结果给我看,我看确实是恢复了
这个结果告诉我们什么呢?异常场景是为了验证异常,那就要先知道异常可能的预期结果。如果和预期不符,那就是有问题
所以异常的结果一定要可解释。不管是几分钟恢复,只要是明确知道为什么,就可以想办法让它更快
就像这个结果,为什么是一分钟多才恢复呢?我让他们查了每个环节的超时。因为这里主要是 jmeter 和主机3、4之间的超时,这个超时是在 Jmeter 的脚本中设定的
之前是设置了 60 秒,所以这个恢复时间是一分钟多一点(还要加上采样频繁嘛)
我让同事回去把时间改为 30s,再来一遍验证下结果。如下所示:
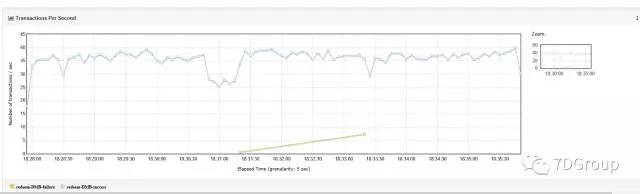
看,真的变短了是不是?
到这里,基本上可以解释了最开始图中的最下面两条线为什么没恢复的问题
那么这时候,我跟开发说:来、来,我们聊聊为什么这个TPS这么低呢?(这两个业务 TPS 低的问题,因为资源也没用上去,所以提了一个 defect 跟踪了)
三、小结
其实最开始的图里面还有个问题。不过我今天写累了,有经验的人自己分析吧。
一个图中真能看出那么多东西来呀?是的,真的可以。
以上是关于性能场景之异常场景设计及分析的主要内容,如果未能解决你的问题,请参考以下文章