Phoenix入门
Posted 杀智勇双全杀
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Phoenix入门相关的知识,希望对你有一定的参考价值。
Phoenix入门
Phoenix概述
虽然Hive on SQL对SQL的支持更加全面,但是其不支持二级索引,底层是通过MapReduce实现的。Phoenix是专门为HBASE设计的SQL on HBASE工具,使用Phoenix可以实现基于SQL操作HBASE,使用Phoenix也可以自动构建二级索引并维护二级索引。
Phoenix官网
官网这么介绍它:
Apache Phoenix enables OLTP and operational analytics in Hadoop for low latency applications by combining the best of both worlds:
the power of standard SQL and JDBC APIs with full ACID transaction capabilities and the flexibility of late-bound, schema-on-read capabilities from the NoSQL world by leveraging HBase as its backing store.
Apache Phoenix is fully integrated with other Hadoop products such as Spark, Hive, Pig, Flume, and Map Reduce.
翻译过来是:
Apache Phoenix通过结合两个方面的优点,在Hadoop中为低延迟应用程序提供OLTP和操作分析:
标准SQL和jdbcapis的强大功能,以及完整的ACID事务处理功能和通过利用HBase作为其后台存储,NoSQL世界中后期绑定的模式读取功能的灵活性。
Apache Phoenix与其他Hadoop产品(如Spark、Hive、Pig、Flume和Map Reduce)完全集成。
翻到最下边还有:
Phoenix官方15分钟快速入门
Phoenix官方语法介绍 这里可以查看Phoenix各种命令的语法。
简言之,Phoenix上层提供了SQL接口,底层通过HBASE的Java API实现,通过构建一系列Scan和Put实现对HBASE数据的读写。
由于底层封装了大量的内置协处理器,Phoenix可以实现各种复杂的处理需求,如:二级索引。Phoenix 对 SQL 相对支持不全面,但是性能比较好,直接使用HbaseAPI,支持索引实现。故Phoenix适用于任何需要使用SQL或者JDBC来快速的读写Hbase的场景,尤其是需要构建/维护二级索引的场景。
Phoenix部署
cd /export/software/
使用rz上传安装包(选用5.0.0版本)后解压及改名:
tar -zxvf apache-phoenix-5.0.0-HBase-2.0-bin.tar.gz -C /export/server/
cd /export/server/
mv apache-phoenix-5.0.0-HBase-2.0-bin phoenix-5.0.0-HBase-2.0-bin
Linux有文件句柄限制,默认是1024,可能不够用,先在3台node的尾部插入这些内容来修改Linux文件句柄数:
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
【*】这个标号必须有,代表所有用户。记得保存。
切换目录并查看:
cd /export/server/phoenix-5.0.0-HBase-2.0-bin/
ll -ah
东西还挺多:
[root@node1 phoenix-5.0.0-HBase-2.0-bin]# ll -ah
总用量 464M
drwxr-xr-x 5 502 games 4.0K 6月 27 2018 .
drwxr-xr-x. 9 root root 178 5月 27 17:37 ..
drwxr-xr-x 4 502 games 4.0K 5月 27 17:37 bin
drwxr-xr-x 3 502 games 133 5月 27 17:37 examples
-rw-r--r-- 1 502 games 141K 6月 27 2018 LICENSE
-rw-r--r-- 1 502 games 11K 6月 27 2018 NOTICE
-rw-r--r-- 1 502 games 129M 6月 27 2018 phoenix-5.0.0-HBase-2.0-client.jar
-rw-r--r-- 1 502 games 106M 6月 27 2018 phoenix-5.0.0-HBase-2.0-hive.jar
-rw-r--r-- 1 502 games 132M 6月 27 2018 phoenix-5.0.0-HBase-2.0-pig.jar
-rw-r--r-- 1 502 games 7.6M 6月 27 2018 phoenix-5.0.0-HBase-2.0-queryserver.jar
-rw-r--r-- 1 502 games 40M 6月 27 2018 phoenix-5.0.0-HBase-2.0-server.jar
-rw-r--r-- 1 502 games 33M 6月 27 2018 phoenix-5.0.0-HBase-2.0-thin-client.jar
-rw-r--r-- 1 502 games 4.2M 6月 27 2018 phoenix-core-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 2.5M 6月 27 2018 phoenix-core-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 2.4M 6月 27 2018 phoenix-core-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 47K 6月 27 2018 phoenix-flume-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 30K 6月 27 2018 phoenix-flume-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 37K 6月 27 2018 phoenix-flume-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 137K 6月 27 2018 phoenix-hive-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 84K 6月 27 2018 phoenix-hive-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 77K 6月 27 2018 phoenix-hive-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 27K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 686K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0-minimal.jar
-rw-r--r-- 1 502 games 17K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 24K 6月 27 2018 phoenix-kafka-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 23K 6月 27 2018 phoenix-load-balancer-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 13K 6月 27 2018 phoenix-load-balancer-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 164K 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 3.5M 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0-minimal.jar
-rw-r--r-- 1 502 games 116K 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 70K 6月 27 2018 phoenix-pherf-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 45K 6月 27 2018 phoenix-pig-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 30K 6月 27 2018 phoenix-pig-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 46K 6月 27 2018 phoenix-pig-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 31K 6月 27 2018 phoenix-queryserver-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 23K 6月 27 2018 phoenix-queryserver-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 59K 6月 27 2018 phoenix-queryserver-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 17K 6月 27 2018 phoenix-queryserver-client-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 14K 6月 27 2018 phoenix-queryserver-client-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 11K 6月 27 2018 phoenix-queryserver-client-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 87K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 3.5K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0-javadoc.jar
-rw-r--r-- 1 502 games 25K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 125K 6月 27 2018 phoenix-spark-5.0.0-HBase-2.0-tests.jar
-rw-r--r-- 1 502 games 16K 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0.jar
-rw-r--r-- 1 502 games 2.7M 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0-runnable.jar
-rw-r--r-- 1 502 games 12K 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0-sources.jar
-rw-r--r-- 1 502 games 7.9K 6月 27 2018 phoenix-tracing-webapp-5.0.0-HBase-2.0-tests.jar
drwxr-xr-x 6 502 games 236 5月 27 17:37 python
-rw-r--r-- 1 502 games 1.2K 6月 27 2018 README.md
这些jar包可以作为HBASE的依赖库,先:
cp phoenix-* /export/server/hbase-2.1.0/lib/
cd /export/server/hbase-2.1.0/lib/
再分发给node2和node3:
scp phoenix-* node2:$PWD
scp phoenix-* node3:$PWD
修改node1的hbase-site.xml:
cd /export/server/hbase-2.1.0/conf/
vim hbase-site.xml
在configuration之间插入:
<!-- 关闭流检查,从2.x开始使用async -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<!-- 支持HBase命名空间映射 -->
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
</property>
<!-- 支持索引预写日志编码 -->
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
</property>
保存后同步给node2和node3:
scp hbase-site.xml node2:$PWD
scp hbase-site.xml node3:$PWD
PWD是大写!!!
由于Phoenix也需要加载配置文件:
[root@node1 conf]# cp hbase-site.xml /export/server/phoenix-5.0.0-HBase-2.0-bin/bin/
cp:是否覆盖"/export/server/phoenix-5.0.0-HBase-2.0-bin/bin/hbase-site.xml"? yes
直接yes覆盖。安全起见再查看下:
cat /export/server/phoenix-5.0.0-HBase-2.0-bin/bin/hbase-site.xml
如果启动了HBASE需要重启HBASE才能刷新配置。。。笔者故意先不启动就是为了省去重启这一步。。。机智如我。。。按顺序启动HBASE即可(启动HDFS+YARN+Zookeeper→启动HBASE服务端→启动hbase shell)。
Phoenix启动
新建立node1会话:
cd /export/server/phoenix-5.0.0-HBase-2.0-bin/
[root@node1 phoenix-5.0.0-HBase-2.0-bin]# ll ./bin -ah
总用量 152K
drwxr-xr-x 4 502 games 4.0K 5月 27 17:37 .
drwxr-xr-x 5 502 games 4.0K 6月 27 2018 ..
drwxr-xr-x 2 502 games 25 5月 27 17:37 argparse-1.4.0
drwxr-xr-x 4 502 games 101 5月 27 17:37 config
-rw-r--r-- 1 502 games 33K 6月 27 2018 daemon.py
-rwxr-xr-x 1 502 games 1.9K 6月 27 2018 end2endTest.py
-rw-r--r-- 1 502 games 1.6K 6月 27 2018 hadoop-metrics2-hbase.properties
-rw-r--r-- 1 502 games 3.0K 6月 27 2018 hadoop-metrics2-phoenix.properties
-rw-r--r-- 1 502 games 1.9K 5月 27 19:39 hbase-site.xml
-rw-r--r-- 1 502 games 2.6K 6月 27 2018 log4j.properties
-rwxr-xr-x 1 502 games 5.1K 6月 27 2018 performance.py
-rwxr-xr-x 1 502 games 3.2K 6月 27 2018 pherf-cluster.py
-rwxr-xr-x 1 502 games 2.7K 6月 27 2018 pherf-standalone.py
-rwxr-xr-x 1 502 games 2.1K 6月 27 2018 phoenix_sandbox.py
-rwxr-xr-x 1 502 games 9.5K 6月 27 2018 phoenix_utils.py
-rwxr-xr-x 1 502 games 2.7K 6月 27 2018 psql.py
-rwxr-xr-x 1 502 games 7.6K 6月 27 2018 queryserver.py
-rw-r--r-- 1 502 games 1.8K 6月 27 2018 readme.txt
-rw-r--r-- 1 502 games 1.7K 6月 27 2018 sandbox-log4j.properties
-rwxr-xr-x 1 502 games 4.7K 6月 27 2018 sqlline.py
-rwxr-xr-x 1 502 games 6.6K 6月 27 2018 sqlline-thin.py
-rwxr-xr-x 1 502 games 6.8K 6月 27 2018 tephra
-rw-r--r-- 1 502 games 2.0K 6月 27 2018 tephra-env.sh
-rwxr-xr-x 1 502 games 6.8K 6月 27 2018 traceserver.py
在bin目录内有个sqlline.py,这货是个Python写的启动脚本,运行它就能启动Phoenix:
bin/sqlline.py node1:2181
在node1:16010查看HBASE的表:
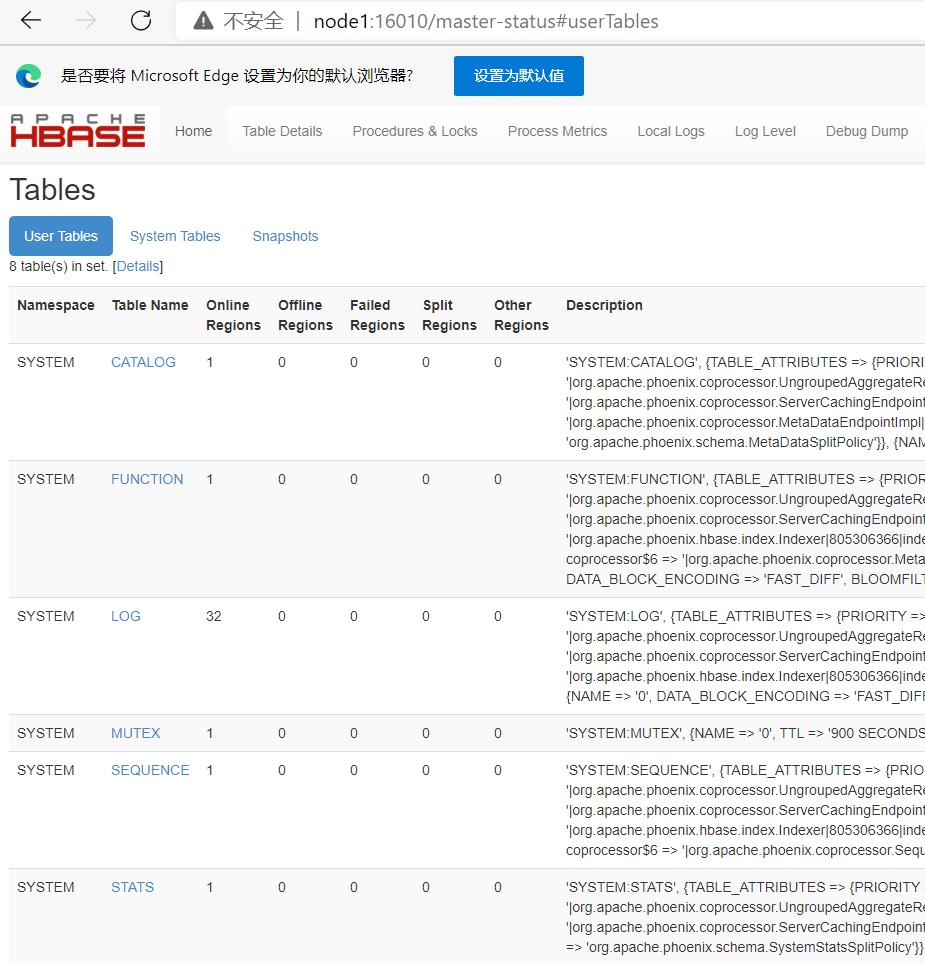
比之前多了几个表,肯定不是笔者自己建立的。。。正好Phoenix也启动了,使用!tables看看:
0: jdbc:phoenix:node1:2181> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
0: jdbc:phoenix:node1:2181>
是它创建的。。。那么Phoenix也就部署完毕。使用!quit即可退出。
命令行使用
可以在上文中的官网指导手册查看帮助。使用!help也可查看一些帮助。

DDL
操作NameSpace
创建NameSpace
在Phoenix的命令行:
0: jdbc:phoenix:node1:2181> create schema if not exists student;
No rows affected (0.274 seconds)
在hbase shell:
hbase(main):001:0> list_namespace
NAMESPACE
STUDENT
SYSTEM
default
hbase
test210524
test210525
6 row(s)
Took 0.5744 seconds
好吧。。。全是大写字母!!!如果要使用小写字母需要+""双引号。
切换NameSpace
0: jdbc:phoenix:node1:2181> use student;
No rows affected (0.02 seconds)
删除NameSpace
0: jdbc:phoenix:node1:2181> drop schema if exists student;
No rows affected (0.274 seconds)
操作Table
列举
上方使用!table列举过了。
创建
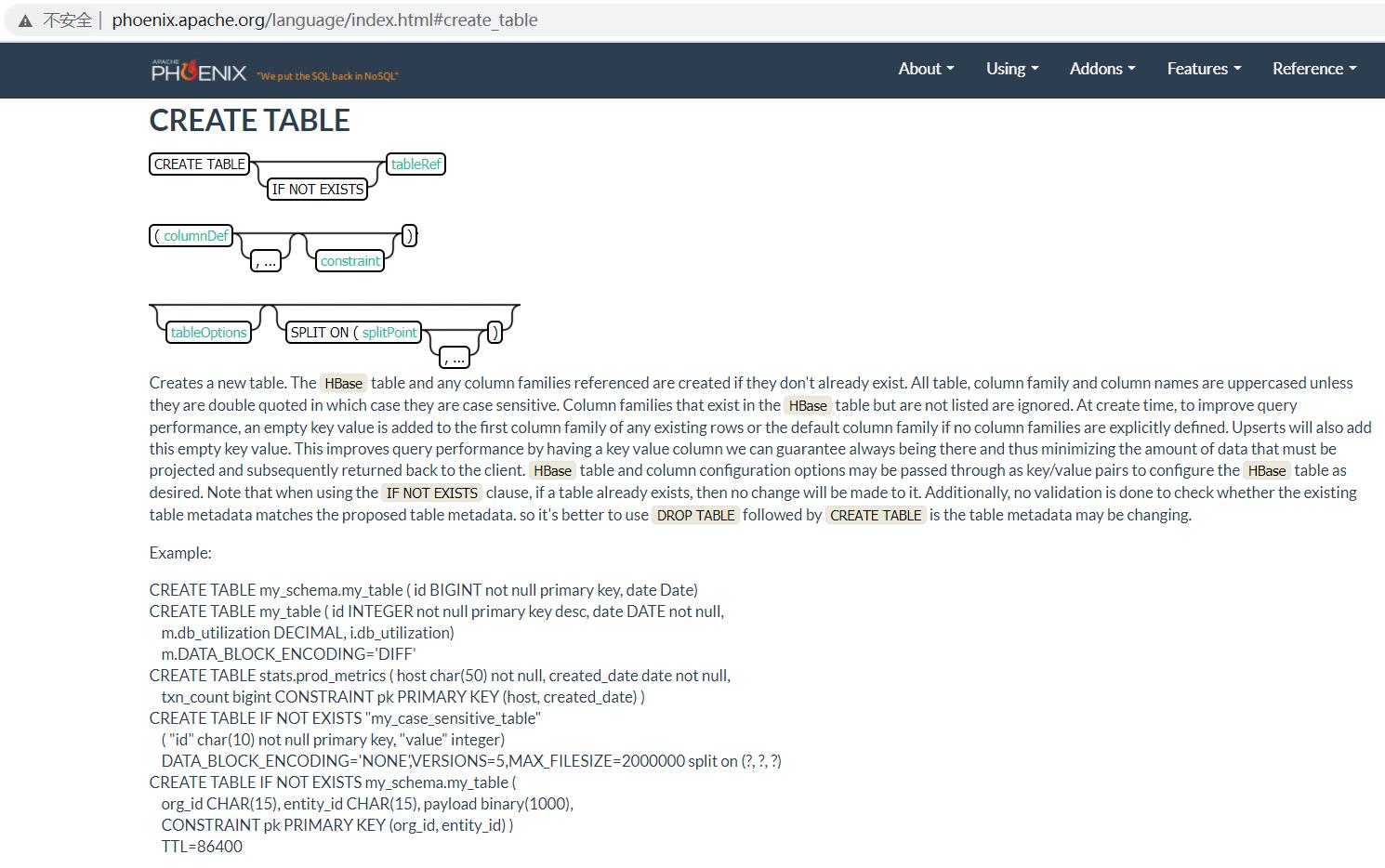
官网给的还比较全面。。。也可以自己试试:
CREATE TABLE my_schema.my_table (
id BIGINT not null primary key,
date Date
);
HBASE当然是没有主键的,这个主键就是HBASE的Rowkey。
CREATE TABLE my_table (
id INTEGER not null primary key desc,
m.date DATE not null,
m.db_utilization DECIMAL,
i.db_utilization
) m.VERSIONS='3';
这种写法就是指定了列族(此处m和i)的列。
CREATE TABLE stats.prod_metrics (
host char(50) not null,
created_date date not null,
txn_count bigint
CONSTRAINT pk PRIMARY KEY (host, created_date)
);
HBASE必须有Rowkey,∴无论如何也得指定一个(此处构建主键,其实就是用多个字段组合出Rowkey)。
CREATE TABLE IF NOT EXISTS "my_case_sensitive_table"(
"id" char(10) not null primary key,
"value" integer
) DATA_BLOCK_ENCODING='NONE',VERSIONS=5,MAX_FILESIZE=2000000
split on (?, ?, ?);
还可以使用split on来指定预分区。
CREATE TABLE IF NOT EXISTS my_schema.my_table (
org_id CHAR(15),
entity_id CHAR(15),
payload binary(1000),
CONSTRAINT pk PRIMARY KEY (org_id, entity_id)
) TTL=86400
这种写法是指定有效期为86400ms。
如果HBASE中没有同名表,就会自动创建一个,例如上文中看到的只有5个表,在Phoenix命令行中执行:
use default;
create table if not exists ORDER_DTL(
ID varchar primary key,
C1.STATUS varchar,
C1.PAY_MONEY float,
C1.PAYWAY integer,
C1.USER_ID varchar,
C1.OPERATION_DATE varchar,
C1.CATEGORY varchar
);
执行后:
0: jdbc:phoenix:node1:2181> !tables
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| TABLE_CAT | TABLE_SCHEM | TABLE_NAME | TABLE_TYPE | REMARKS | TYPE_NAME | SELF_REFERENCING_COL_NAME | REF_GENERATION | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
| | SYSTEM | CATALOG | SYSTEM TABLE | | | | | |
| | SYSTEM | FUNCTION | SYSTEM TABLE | | | | | |
| | SYSTEM | LOG | SYSTEM TABLE | | | | | |
| | SYSTEM | SEQUENCE | SYSTEM TABLE | | | | | |
| | SYSTEM | STATS | SYSTEM TABLE | | | | | |
| | | ORDER_DTL | TABLE | | | | | |
+------------+--------------+-------------+---------------+----------+------------+----------------------------+-----------------+-+
0: jdbc:phoenix:node1:2181>
一般不会有人这么做。。。Phoenix的主要用途是查询。。。想要查询就得事先有表和数据。。。那么,先准备一个表和数据再说。。。使用shell脚本来做这件事:
cd /export/data/
rz上传数据
vim /export/data/hbasedata20210527.sh
插入:
#!/bin/bash
hbase shell /export/data/ORDER_INFO.txt
保存后+运行权限:
chmod u+x hbasedata20210527.sh
执行:
hbasedata20210527.sh
Java API的DDL利用之前写的程序读取:
tableDescriptor.getTableName().getNameAsString() = ORDER_DTL
tableDescriptor.getTableName().getNameAsString() = ORDER_INFO
tableDescriptor.getTableName().getNameAsString() = SYSTEM:CATALOG
tableDescriptor.getTableName().getNameAsString() = SYSTEM:FUNCTION
tableDescriptor.getTableName().getNameAsString() = SYSTEM:LOG
tableDescriptor.getTableName().getNameAsString() = SYSTEM:MUTEX
tableDescriptor.getTableName().getNameAsString() = SYSTEM:SEQUENCE
tableDescriptor.getTableName().getNameAsString() = SYSTEM:STATS
tableDescriptor.getTableName().getNameAsString() = test210524:t1
tableDescriptor.getTableName().getNameAsString() = test210525:testTable1
居然没有命名空间!!!其实也无妨:
hbase(main):010:0> list
TABLE
ORDER_DTL
ORDER_INFO
SYSTEM:CATALOG
SYSTEM:FUNCTION
SYSTEM:LOG
SYSTEM:MUTEX
SYSTEM:SEQUENCE
SYSTEM:STATS
test210524:t1
test210525:testTable1
10 row(s)
Took 0.0524 seconds
=> ["ORDER_DTL", "ORDER_INFO", "SYSTEM:CATALOG", "SYSTEM:FUNCTION", "SYSTEM:LOG", "SYSTEM:MUTEX", "SYSTEM:SEQUENCE", "SYSTEM:STATS", "test210524:t1", "test210525:testTable1"]
hbase(main):011:0>
虽然这2张表并没有命名空间,但是看样子已经成功创建了表。更神奇的是:
0: jdbc:phoenix:node1:2181> create table if not exists ORDER_INFO(
. . . . . . . . . . . . . > "ROW" varchar primary key,
. . . . . . . . . . . . . > "C1"."USER_ID" varchar,
. . . . . . . . . . . . . > "C1"."OPERATION_DATE" varchar,
. . . . . . . . . . . . . > "C1"."PAYWAY" varchar,
. . . . . . . . . . . . . > "C1"."PAY_MONEY" varchar,
. . . . . . . . . . 以上是关于Phoenix入门的主要内容,如果未能解决你的问题,请参考以下文章
开源推荐 243分钟入门Apache Phoenix(HBase的开源SQL引擎)
2021年大数据HBase:Apache Phoenix的基本入门操作