收藏 | GPU分析工具随笔
Posted 人工智能博士
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了收藏 | GPU分析工具随笔相关的知识,希望对你有一定的参考价值。
点上方人工智能算法与Python大数据获取更多干货
在右上方 ··· 设为星标 ★,第一时间获取资源
仅做学术分享,如有侵权,联系删除
转载于 :作者 | 汤姆猫X
地址 | https://zhuanlan.zhihu.com/p/367122807
文章目录
前言
一、GPU分析工具
二、GPU分析工具相关参数解析
总结
参考
前言
分析性能是少不了工具辅助的,尤其是GPU,不同于CPU,GPU测试性能难度会比较大些,笔者总结了工具的一些使用,方便进行测试。除了性能测试,还有非常实用的,可以通过这些工具分析渲染相关的问题,如果是进行渲染相关开发者,笔者建议是需要非常熟悉这些工具的使用的。目前常用的移动端GPU分析工具有:对于高通的是Snapdragon Profiler, ARM Mali GPU的Arm Mobile Studio, Renderdoc,或者专门用于华为手机的huawei-graphics-profiler,Metal的XCode。对于PC上或者模拟器的是Inter-GPA, Nsight。本文主要介绍一些工具参数的解析,方便大家理解如何使用这些工具(文章还需要继续完善)
一、GPU分析工具
本文不对工具的使用做更多的介绍,读者可以自行阅读文档,亲自操作。注意下载这些软件的时候,外网的软件最好是用google的gmail登陆下载,比较方便。
以下移动GPU分析工具:
1)Snapdragon Profiler
https://link.zhihu.com/?target=https%3A//developer.qualcomm.com/software/snapdragon-profiler
安装完,直接打开,接上usb就会自动连:
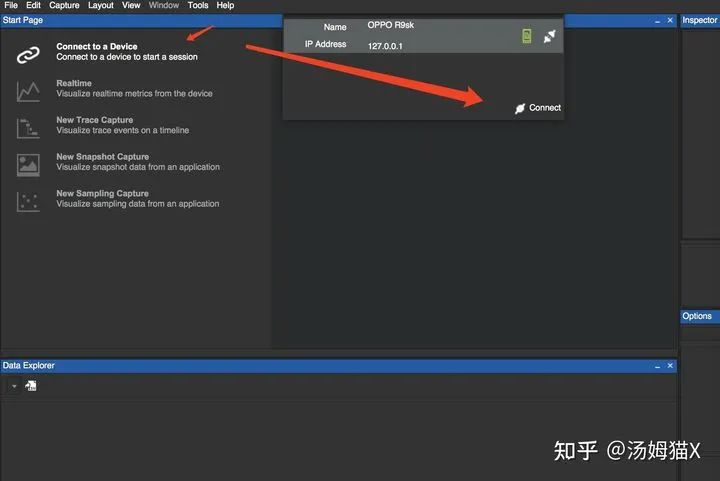
2)Arm Mobile Studio
https://link.zhihu.com/?target=https%3A//developer.arm.com/tools-and-software/graphics-and-gaming/arm-mobile-studio/downloads
文档:
https://link.zhihu.com/?target=https%3A//developer.arm.com/documentation/102469/0100/Configure-your-device
https://link.zhihu.com/?target=https%3A//developer.huawei.com/consumer/cn/forum/topic/0202336807101250292
Streamline性能分析器:
https://link.zhihu.com/?target=https%3A//community.arm.com/cn/b/blog/posts/arm-mobile-studio-mali-gpu
如果出现类似下图错误,获取其他的错误,可以尝试重启手机试试。
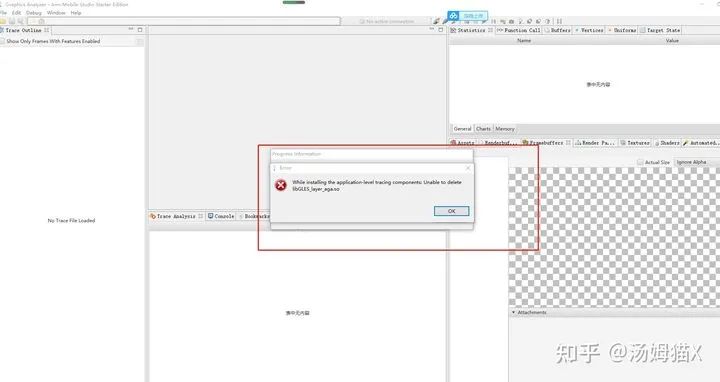
3)Renderdoc
https://link.zhihu.com/?target=https%3A//renderdoc.org/
这个工具可用PC和Mail的GPU比较稳定,但对于高通的GPU相对来说不稳定。
3)huawei-graphics-profiler
https://link.zhihu.com/?target=https%3A//developer.huawei.com/consumer/cn/huawei-graphics-profiler
下载完有个FrameDebug和System Profiler,可以通过Frame Debug实现类似RenderDoc的截屏分析,但对华为手机更友好,数据相对会准确些(这个要根据实际情况来判断准确,尤其是GPU During)。System Profiler可以测内存,fps,GPU Counter等,还有带宽。
注意,这个工具需要android版本的要求的:
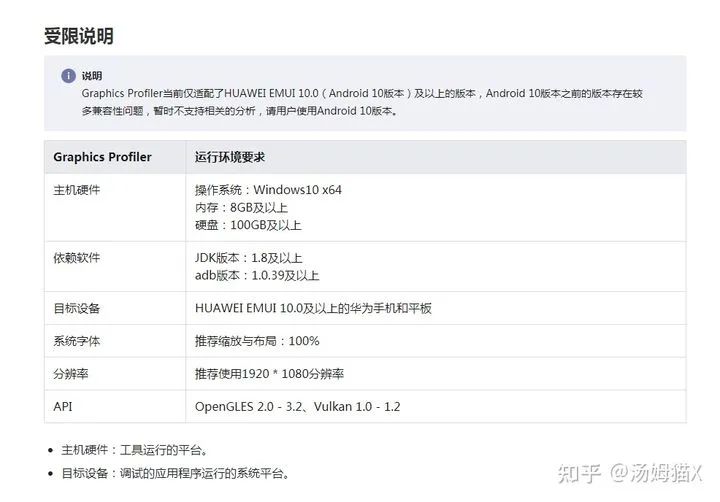
如果发现版本不兼容,推荐使用Arm Mobile Studio。
4)Metal的XCode
https://link.zhihu.com/?target=https%3A//developer.apple.com/documentation/metal/frame_capture_debugging_tools
https://www.jianshu.com/p/d6347f8aedd8
PC上的GPU分析工具:
https://zhuanlan.zhihu.com/p/76715274
1)Intel GPA
https://software.intel.com/content/www/us/en/develop/tools/graphics-performance-analyzers.html
2)Nvidia Nsight
https://link.zhihu.com/?target=https%3A//docs.nvidia.com/nsight-graphics/index.html
二、GPU分析工具相关参数解析
1)理论知识
首先我们先了解一些相关的理论知识,这个更好的理解分析工具的相关参数。
1.GPU内存架构
部分架构的GPU与CPU类似,也有多级缓存结构:128kb寄存器、L1缓存、L2缓存、GPU显存、系统显存。
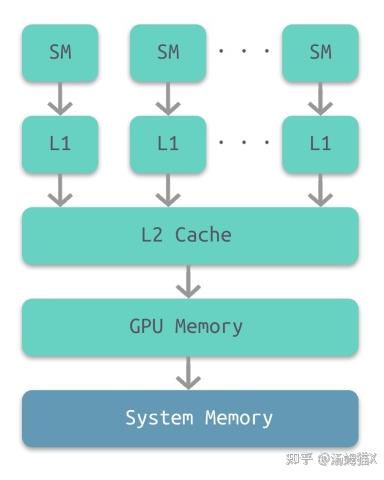
根据图上GPU中的内存:
每个线程都有自己的私有本地内存(Local Memory)和寄存器(Resigter)
每个线程块都包含共享内存(Shared Memory),可以被线程中所有的线程共享,其生命周期与线程块一致
所有的线程都可以访问全局内存(Global Memory)
只读内存块:常量内存(Constant Memory)和纹理内存(Texture Memory)
每个SM有自己的L1 cache,SM通过L2 cache连接到Global Memory
存取速度从寄存器到系统内存依次变慢:

结论:Registers->Caches->Shared Memory->Gloabl Memory(Local Memory)。
下面我们对重要参数再做一些了解:
Registers
寄存器是访问速度最快的空间,寄存器变量在程序中宏如何使用?
当我们在核函数中不加修饰的声明一个变量,那该变量就是寄存器变量,如果在核函数中定义了常数长度的数组,那也会被分配到Registers中;寄存器变量是每个线程私有的,当这个线程的核函数执行完成后,寄存器变量也就不能访问了。
寄存器是比较稀缺的资源,空间很小,Fermi架构中每个线程最多63个寄存器,Kepler架构每个线程最多255个寄存器;一个线程中如果使用了比较少的寄存器,那么SM中就会有更多的线程块,GPU并行计算速度也就越快。
如果一个线程中变量太多,超出了Registers的空间,这时寄存器就会发生溢出,就需要其他内存(Local Memory)来存储,当然程序的运行速度也会降低。
因此,在程序中,对于那种循环操作的变量,我们可以放到寄存器中;同时要尽量减少寄存器的使用数量,这样线程块的数量才能增多,整个程序的运行速度才能更快。
Local Memory
Local Memory也是每个线程私有的,在核函数中符合存储在寄存器中但不能进入核函数分配的寄存器空间中的变量将被存储在Local Memory中,Local Memory中可能存放的变量有以下几种:
使用未知索引的本地数组
较大的本地数组或结构体
任何不满足核函数寄存器限定条件的变量
Shared Memory
每个SM中都有共享内存,使用__shared__关键字(CUDA关键字的下划线一般都是两个)定义,共享内存在核函数中声明,生命周期和线程块一致。
同样需要注意的是,SM中共享内存使用太多,会导致SM上活跃的线程数量减少,也会影响程序的运行效率。
数据的共享肯定会导致线程间的竞争,可以通过同步语句来避免内存竞争,同步语句为:
void __syncthreads();当所有线程都执行到这一步时,才能继续向下执行;频繁调用__syncthreads()也会影响核函数的执行效率。
共享内存被分成了不同个Bank,我们知道一个Warp中有32个SM,在比较老的GPU中,16个Bank可以同时访问,即一条指令就可以让半个Warp同时访问16个Bank,这种并行访问的效率可以极大的提高GPU的效率。比较新的GPU中,一个Warp即32个SM可以同时访问32个Bank,效率又提升了一倍。
Constant Memroy
常量内存驻留在设备内存中,每个SM都有专用的常量内存空间,使用__constant__关键字来声明,可以用来声明一些滤波系数等常量。
常量内存存在于核函数之外,在kernel函数外声明,即常量内存存在于内存中,并不在片上,常量内容的访问速度也是很快的,这是因为每个SM都有专用的常量内存缓存,会把片外的常量读取到缓存中;对所有的核函数都可见,在Host端进行初始化后,核函数不能再修改。
Texture Memory
纹理内存的使用并不多,它是为了GPU的显示而设计的,纹理内存也是存在于片外。
Global Memory
全局内存,就是我们常说的显存,就是GDDR的空间,全局内存中的变量,只要不销毁,生命周期和应用程序是一样的。
在访问全局内存时,要求是对齐的,也就是一次要读取指定大小(32、64、128)整数倍字节的内存,数据对齐就意味着传输效率降低,比如我们想读33个字节,但实际操作中,需要读取64字节的空间。
2.GPU卡顿?
提及这个,主要是简单介绍下为啥为了达到60fpsGPU也是需要达到60fps,虽然说GPU和CPU是独立计算的。我们先看看Android的CPU与GPU的工作流程。
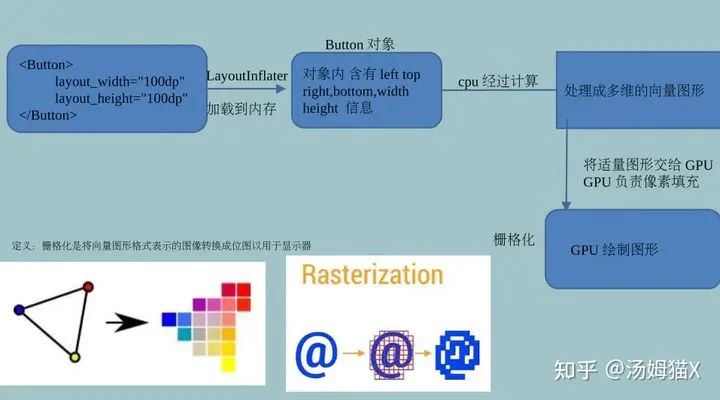
Android系统每隔16.666ms发出发出VSYNC信号(1000ms/60=16.6666ms), 对UI进行渲染,如果每次渲染都成功这样就能够达到流畅的画面所需要的60fps,为了能够实现60fps,这意味着计算渲染的大多数操作都必须16.666ms内完成。
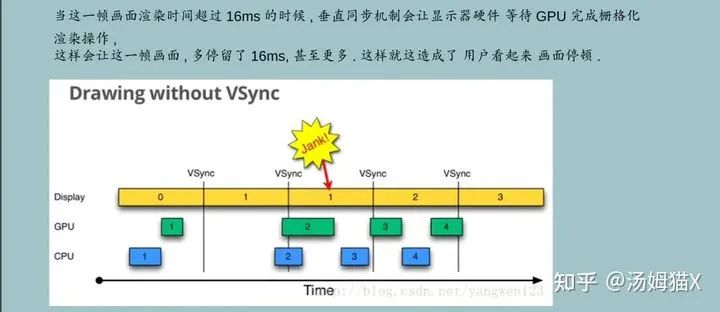
3.多线程渲染
这是CPU侧的,介绍可以帮助读者更好的理解渲染相关的内容,也可以更好的分析性能。
介绍这个也是为了方便大家在分析CPU还是GPU卡顿的时候一些原理性的知识。一般来说,图形渲染是在主线程中调用图形API来完成,而图形API的操作开销往往是CPU的瓶颈,渲染线程可以将主线程对图形API的操作压力分担出去,减少主线程的压力,提高帧率。尤其是GLES的图形API开销,是比较大,我们来看一组数据:
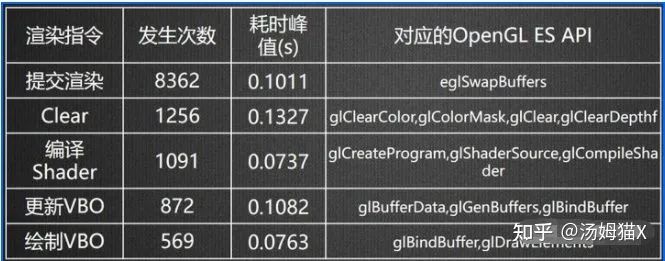
尤其是glClearColor,和glSwapBuffer,这两个图形API的消耗会比较高。想进一步验证的可以通过图形分析软件截屏分析,一般可以看到SetRenderTarget , glClearColor等数据,一般这块的消耗都不低。
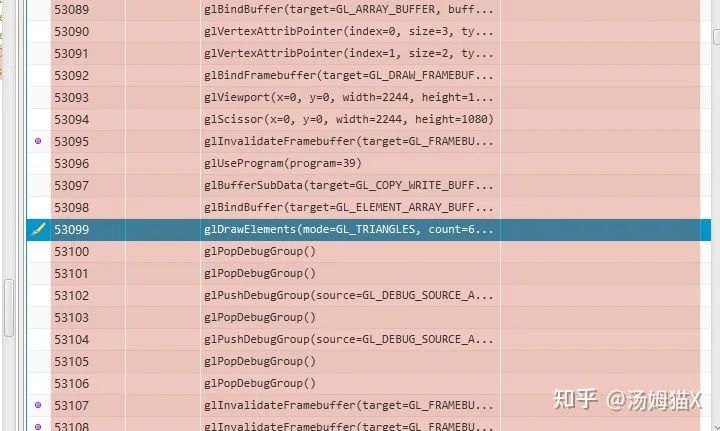
所以我们在写渲染管道相关的代码,需要注意尽量减少SetRenderTarget等图形API的调用。如果读者感兴趣,还可以进行Valkun和Metal图形API的测试,相对来说,比GLES的效率高30%不等(跟机型有关)。(这块可以读者可进一步验证)。
多线程渲染实现方式有很多种,大体的框架是:
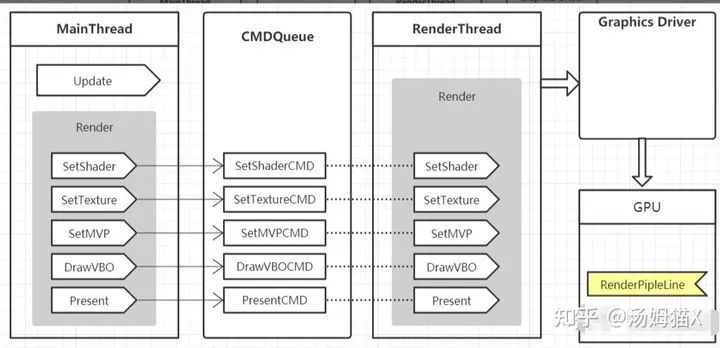
微软的DirectX11已经从架构上支持了真正的多线程渲,图下:
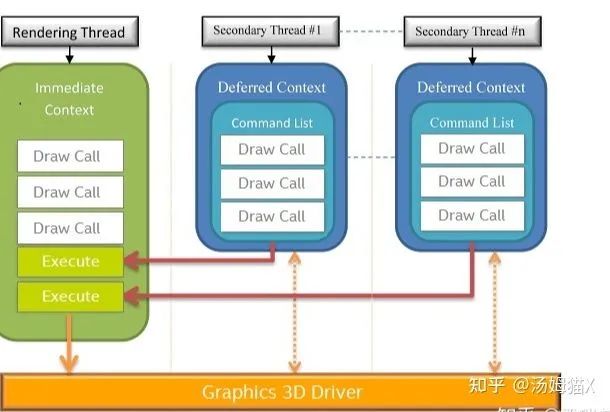
注意:多线程渲染是指将渲染单独放到一个线程,理论上可以开启不止一个线程来执行渲染指令,但是Opengl并不支持多个线程同时操作同一个Context。
以unity多线程为例,我们可以看看unity的多线程渲染流程:

管道可以采用环形buffer来实现,主线程将渲染指令系列化为二进制数据,不断的往buffer里写入,当buffer被填满时,主线程被阻塞;渲染线程不断的从buffer中读取数据,反系列化为渲染指令,当buffer中无数据时,渲染线程被阻塞。
采用环形buffer的优点是读写buffer只需要移动读写点的位置,在只有一个生产者和消费者前提下,环形buffer的读写可以做到无锁(读写点用int32表示,如果32位的int读写是原子操作,那么只需要采用内存屏障来保证在读写点变更时,相应的内存是可用的即可)。
采用管道的优点是,不用考虑资源分配与释放的线程安全,因为同一份资源在主线程和渲染线程分别有自己不同的实例,两个线程分别维护自己资源的生命周期。
采用管道的缺点是面向数据,它要求所有渲染指令必须能被系列化,因此不能采用抽象度过高的实现方式。比如一个抽象度比较高的渲染指令是传入一个相机、场景和renderTarget,这种级别的抽象使用管道来实现就会比较麻烦。因为它要求相机、场景和renderTarget必须是可系列化的。
采用管道的另一个缺点是为了能读写大容量的资源,需要预先分配一块比较大的内存,而且相对于直接传递资源的指针来说,读取耗时会相对高一些。
在看看主线程与渲染线程同步策略:
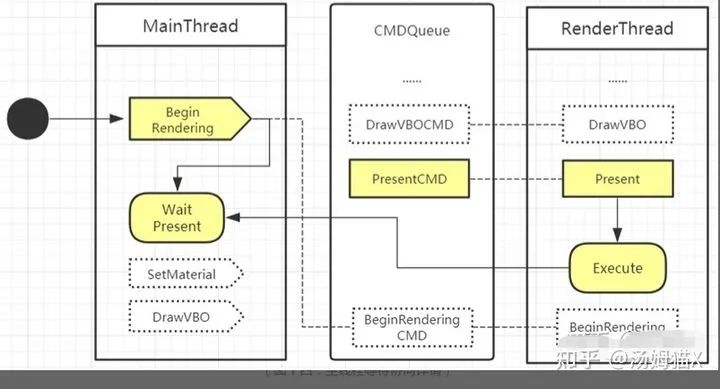
在开始每一帧的渲染时,主线程提交BeginRendering指令,在每一帧渲染结束时,主线程提交Present指令。
在提交BeginRendering指令时,如果渲染线程上一帧的渲染指令未结束,主线程会阻塞等待渲染线程直执行完成才会开始这一帧的渲染指令提交。
可以看出,当渲染线程耗时比较高的时间,主线程就一直在wait present,帧率下降。一般遇到这种问题,需要减轻CPU侧的渲染压力,比如减少drawcall,合并一些后处理等。
2)分析纹理数据
观察纹理从带宽入手,因为它表明了每帧画面中有多少纹理数据输入到了 GPU,进而可以快速定位潜在的性能问题。就纹理带宽来说,一个很好的经验法则就是确保纹理读取带宽 (Texture Read Bandwidth) 均值不高于 1GB/s,而峰值远低于 5GB/s。

比如我们的游戏,它就消耗了大量的纹理带宽,因为平均带宽达到了 4GB/s,而到了帧结尾的部分,峰值已超过 6GB/s。
后处理 对纹理带宽需求较高是可以理解的,也许您可以在渲染的后序阶段把部分带宽使用于一些特殊的效果处理上面,比如实现光晕和色调映射。但是如果您的游戏存在很高的纹理读取带宽峰值,那么就需要注意潜在的性能问题了。
对于纹理带宽的消耗非常高,需要进一步分析。要分析潜在的纹理带宽问题,首先我会检查纹理缓存情况。可以关注在纹理的停滞比例,L1 和 L2 缓存未命中的比例。当 L1 缓存未命中所需的纹理数据时,请求会转向 L2 缓存,然后会再转向系统内存。每一步都会增加延迟并且提高功耗。L1 的平均未命中比例不应该超过 10%,未命中的峰值比例不应该超过 50%。

这也解释了为啥我们需要开启Mipmap也是因为开启mipmap可以提高Texture cache的命中率,当 L1 缓存未命中所需的纹理数据时,请求会转向 L2 缓存,然后会再转向系统内存,越是越后性能越差。
当mipmap为 0 时,它意味着 GPU 常常访问最顶级的 mipmap 纹理数据,也就是纹理的 mipmap 链中最大的一片或者未进行 mipmap 处理的纹理或者当渲染 GUI 或PostProcessing 期间访问未经 mipmap 处理的纹理是可以的。但是在其它场景下,这样的操作会带来很大的性能损失,也是导致较差数据缓存效果的原因。获取纹理会消耗大量的系统带宽,同时可能会造成延迟、电池寿命缩短,甚至引起过热问题进而导致降频而进一步的性能下降。
3)GPU相关的基本知识
如果要更深入的理解GPU分析工具的使用,自然也少不了对基本的知识GPU相关的理论知识了解的。先贴几个网址,后续考虑会继续推出GPU基础相关的文章。
https://www.cnblogs.com/timlly/p/11471507.html
https://zhuanlan.zhihu.com/p/347001411
https://link.zhihu.com/?target=https%3A//developer.nvidia.com/content/life-triangle-nvidias-logical-pipeline
对于GPU,基本的都有这些相同的概念和部件,这些也是对使用GPU分析工具有帮助的:
TPC(纹理处理簇)
Thread
SM、SMX、SMM 流多处理器
Warp Schedulers:这个模块负责warp调度,一个warp由32个线程组成,warp调度器的指令通过Dispatch Units送到Core执行。
SP(Streaming Processor,流处理器)
Core(运算核心)
ALU (逻辑运算单元)
FPU(浮点数单元)
SFU(Special function units)执行特殊数学运算(sin、cos、log等)
ROP(render output unit,渲染输入单元),一个ROP内部有很多ROP单元,在ROP单元中处理深度测试,和framebuffer的混合,深度和颜色的设置必须是原子操作,否则两个不同的三角形在同一个像素点就会有冲突和错误。
Load/Store Unit 模块来加载和存储数据
L1 Cache
L2 Cache
Register File(寄存器,比如Uniform数据)
GPC(Graphics Processing Cluster),每个GPC拥有多个SM(SMX、SMM)和一个光栅化引擎(Raster Engine)
4)查看GPU FLLOPS or Clock or Fillrate 等
https://link.zhihu.com/?target=https%3A//gflops.surge.sh/
https://link.zhihu.com/?target=https%3A//en.wikipedia.org/wiki/Mali_%28GPU%29
https://link.zhihu.com/?target=https%3A//en.wikipedia.org/wiki/Adreno
参考
https://zhuanlan.zhihu.com/p/350390554
https://zhuanlan.zhihu.com/p/158548901
https://www.jianshu.com/p/914738d25a5b
https://zhuanlan.zhihu.com/p/44116722
https://www.cnblogs.com/timlly/p/11471507.html
---------♥---------
声明:本内容来源网络,版权属于原作者
图片来源网络,不代表本公众号立场。如有侵权,联系删除
AI博士私人微信,还有少量空位


点个在看支持一下吧

以上是关于收藏 | GPU分析工具随笔的主要内容,如果未能解决你的问题,请参考以下文章