超硬核!兔兔阿里p7学长给的面试知识库
Posted 兔老大RabbitMQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了超硬核!兔兔阿里p7学长给的面试知识库相关的知识,希望对你有一定的参考价值。
一个阿里p7学长给的nosql面试知识库,绝对真实,学会了去面呀。
最近整理了一下超硬核系列的文章和面经系列的文章,可以持续关注下:
超硬核系列历史文章:(我保证每篇文章都有值得学习的地方,并且对小白有特别大的提高,敢说敢负责。)
这个系列入门级别的有万字,有些文章十万字。真的建议每篇文章都收藏
《这是全网最硬核redis总结,谁赞成,谁反对?》六万字大合集
超硬核十万字!全网最全 数据结构 代码,随便秒杀老师/面试官,我说的
一个神奇的大学科目《软件工程》,知识点总结+测试题,包你不挂科
超硬核!我统计了BAT笔试面试出现频率最高的五道题,学会了总能碰到一道
当年,学姐把这份Java总结给我,让我在22k的校招王者局乱杀
面试经验系列历史文章:
这个系列离结束差的还特别多,会更新涵盖所有一线大厂的所有岗位,也可以关注一下。
- NoSQL概述
- NoSQL数据库的优势:①支持超大规模的数据存储②数据模型比较灵活
NoSQL数据库的劣势:①缺乏底层基础理论做支撑②很多nosql数据库都不支持事务的强一致性
-
- 关系数据库的优势:①具备非常完备的关系代数理论作为基础②有非常严格的标准③支持事务一致性④可以借助索引机制实现非常高效的查询
劣势:①可扩展性非常差②不具备水平可扩展性,无法较好支持海量数据存储③数据模型定义严格,无法较好的满足新型web2.0应用需求
-
- 传统的关系数据库性能上的缺陷:①无法满足海量数据的管理需求②无法满足高并发需求
- NoSQL的四大类型:键值数据库 列族数据库 文档数据库 图数据库
- NoSQL数据库的三大理论基石:①CAP ②BASE③最终一致性(会话一致性,单调写一致性)
- Nosql数据库具有的三个特点:①灵活的可扩展性②灵活的数据模型③和云计算的紧密结合
- Nosql兴趣起的原因:①关系数据库无法满足web2.0的需求②数据模型的局限性
- Acid四性:A:原子性 C:一致性 I:隔离性 D:持久性
- MongoBD简介
- 一个mongodb可以建立多个数据库;mongdb将数据存储为一个文档,数据结构是键值对;多个文档组成集合,多个集合组成数据库
-
- 数据库命名:
- 不能是空字符串("")②不能以$开头③不能含有.和空字符串。
- 数据库名字区分大小写(建议数据库名全部使用小写)
- 数据库名字长度最多64字节。⑥不要与系统保留的数据库名字相同,这些数据库包括:admin、local、 config等
- 文档是MongoDB最核心的概念,本质是一种类JSON的BSON格式的数据。
- BSON是由一组组键值对组成,它具有轻量性、可遍历性和高效性三个特征。可遍历性是MongoDB将BSON作为数据存储的主要原因。
- 适用场景:海量的数据存储,json格式的数据,高伸缩性场景,弱事务型业务
- 使用mongdb shell访问mongdb:1)连接数据库:mongo port 27017
2)连接远程的mongdb服务器:mongo “mongodb://mongodb0.example.com:27017” 3)查看所以数据库:show dbs 4)创建数据库:use DATABASE_NAME use database1 5)创建集合:插入数据时候自动创建集合 6)插入文档:db.cllection1.insert({name:”张三”,age:20})
7. 
- MongoBD数据模型
- MongoBD数据类型:
- 基本数据类型:
- Null 表示空值或者不存在的字段②布尔③数值类型④字符串⑤二进制数据可以保存由任意字节组成的字符串,例如:图片、视频等⑥正则表达式:{name:/foo/} name字段含有foo的文档⑦javascript 代码
- Date日期:new Date , 北京时间(CST) = UTC + 8个小时
- Timestamp(时间戳):只供mongdb数据库内部使用,用于记录操作的详细时间,new Timestamp()
- ObjectId:总共12字节;

- 基本数据类型:
- MongoBD数据类型:
ObjectId() 用于创建ObjectID;getTimestamp() 用于取得ObjectID的时间戳; valueOf() 用于取得ObjectID的字符串表示
-
-
- 内嵌文档
- 数组
- Mongdb客户端的一基本命令:
-
- 连接/切换数据库 – use test01;
- 数据插入 -- db.stu.insert(obj);
- 数据查询 -- db.stu.find(query);
- 数据更新 -- db.stu.update(query,obj);
- 数据删除 -- db.stu.remove(query);
- 实例(好好看看)
1、创建/切换数据库:use db1
2、查看数据库:show dbs
3、删除当前数据库:db.dropDatabase()
4、创建集合:db.createCollection("c1")
5、创建集合并添加数据
db.dept.insert({deptno:1,deptname:"技术部",location:"beijing"})
6、查看集合:show collections
7、删除集合:db.collection_name.drop()
8、查看所有文档数据:db.dept.find()
9、查看单独的一个文档:db.dept.findOne()
- 删除指定文档:db.dept.remove({deptno:1})
- 更新文档:db.dept.update({deptno:2},{$set:{location:"shenzhen"}})
- 数据更新
- 数据更新三种:插入:insert;删除:remove;修改:update
- Insert函数(只能作用于一个集合,集合不存在自动创建):db.集合名.insert(要插入的文档,可选参数(设置安全级别))返回值:WriteResult({“nInserted”:1}); db.collection.insertOne()
db.collection.insertMany()
-
- Remove函数:db.集合名.remove(查询条件,可选参数(Boolean类型,只会删除满足条件的一个文档)):db.student.remove({name:”tom”},true)
drop函数,不仅删除文档,还会删除集合中的索引,db.test.drop()
deleteOne()和deleteMany()
-
- Bluk函数:(一共有两种,顺序和并行)
-
- db.集合名.initializeUnorderedBulkOp() 并行Bulk(以随机的方式并行地执行添加到执行列表中的操作); ②db.集合名.initializeOrderedBulkOp() 顺序Bulk(按照预先定义的操作顺序);Bulk.insert()、Bulk.find.update()、Bulk.find.remove();Bulk.execute()
-
- Bluk函数:(一共有两种,顺序和并行)
var bulk=db.student.initializeOrderedBulkOp()
var bulk=db.student.initializeUnorderedBulkOp();
bulk.insert({name:"san",age:18})
bulk.insert({name:"si",age:18,})
bulk.find({name:"si"}).remove();
-
- Update函数:
db.集合名.update(查询条件(相当于where);更改的内容(相当于set);查询条件不存在时,选择{ upsert:true}插入,false:不插入;查询出多个文档,选择{multi:true}全部,false:第一条)
返回值:WriteResult({“nMatched”:1,“nUpserted”:0,”nModified”:1})
依次是:满足的文档个数 ;upsert:true时插入的个数;实际修改的文档个数
更改操作符:
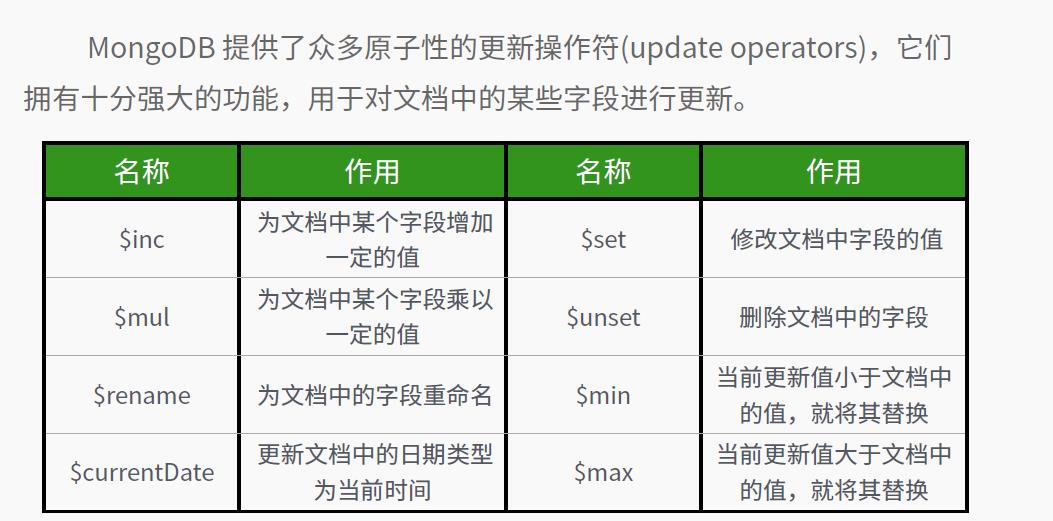
- db.update_test.update({_id:1},{$inc:{age:2}})
- db.update_test.update({_id:1},{$min:{age:3}})
③db.update_test.update(
{name:"xiaoli"},
{$set:{name:"xiaoli_update",age:28}},
{multi:true})
-
- db.update_test.update({_id:1},{$rename:{age:"年龄"}})
- db.update_test.update({_id:1},{$unset:{年龄:""}})
⑥db.update_test.update({_id:1},{$unset:{年龄:1}})
内嵌文档:①修改整个内嵌:{$set:{field1:新内嵌文档}} ②修改内嵌的某个字段:{$某个更改操作符:{“field1.field2”:value}}
数组元素:

①db.array_test.insert([
{name:"joe",scores:[60,60,61,62]},
{name:"jack",scores:[]}
])
②db.array_test.update({name:"joe"},{$pop:{scores:-1}})
③db.array_test.update({name:"joe"},{$pull:{scores:{$gt:61}}})
MongoDB为$push和$addToSet提供了一组修改器(modifiers)。通过将操作符和修改器结合使用,可以实现更多复杂的功能

①db.array_test.update(
{name:"joe"},
{$push:{scores:{$each:[90,92,85]}}})
②db.array_test.update(
{name:"joe"},
{$push:{scores:{$each:[90,92,85]}}})
③db.array_test.update(
{name:"jack"},
{$push:
{
scores:
{$each:[{course:"语文",成绩:80},
{course:"数学",成绩:95},
{course:"外语",成绩:70},
],
$sort:{成绩:-1},$slice:2} }})
-
- mongdb提供了四种写入级别:①非确认式写入②确认式写入③日志写入④复制集确认式写入
- 数据查询
- db.集合名.find(query,fields,limit,skip)
query:指明查询条件 db.student.find({name:”joe”,age:{$lt:22}})
fields; 用于字段映射,指定是否返回该字段,0代表不返回,1代表返回,语法格式:{field:0}或{field:1}
limit:限制查询结果集的文档数量,指定查询返回结果数量的上限
例如:db.student.find({name:”joe”},{“name”:1,”age”:1},2})
skip:跳过一定数据量的结果,设置第一条返回文档的偏移量
例如:db.student.find({name:”joe”},{“name”:1,”age”:1},2,1})
-
- ①find函数一次只能查询只能针对一个集合;②db.student.find()或db.student.find({})会返回所有文档;③排序就是sort函数:db.student.find().sort({name:1,age:-1});④db.collection.findOne()只会返回第一条数据
- 比较查询操作符

-
- 逻辑查询操作符

-
- 元素查询操作符
-
- 数据查询操作符
- 内嵌文档查询:①查询整个内嵌文档:当内嵌文档键值对的数量以及键值对的顺序都相同时,才会匹配②查询文档的某个字段 需要.
db.student.find({“address.city”:”Beijing”})
-
- 数组操作符
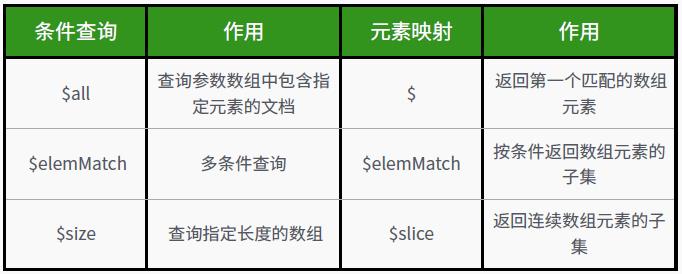
与位置无关:db.student.find({“score.成绩”: 80})
与位置有关:db.student.find({“scores.2.成绩”: 95})
-
- 游标
-
- 提供的函数

- 游标的生命周期:游标的创建,使用以及销毁三个阶段
- 创建:var cursor = db.student.find().sort({age:1}).limit(2).skip(10);
- db.serverStatus().metrics.cursor 查看当前系统的游标状态
- 提供的函数
-
- 模糊查询:使用$regex或者正则表达式
- 游标

{<field>:{$regex:/pattern/,$options:’<options>’}};
{<field>: /pattern/<options>}
在$In中只能用正则;在隐式的$and只能用$regex; option包含x或s时,只能用$regex
-
- FindAndModIfy函数:

- 索引
- mongdb索引的类型:
-
- mongdb索引的属性:唯一性,稀疏性,TTL属性
-
- 唯一索引(Unique Index):创建db.collection.createIndex( <key and index type specification>, { unique: true } )
-
- mongdb索引的属性:唯一性,稀疏性,TTL属性
为复合索引设置唯一属性时,只能保证组合索引字段的唯一性,不能确保单个或索引字段自己的唯一性;id唯一索引是自动创建的不能被删除
-
-
-
- 稀疏索引(spare index):db.student.createIndex({name:1}, {sparse:true})
-
-
指的是只为索引字段存在的文档建立索引,即使索引字段的值为null,但不会为索引字段不存在的文档建立索引。
-
-
-
- TTL索引(time-to-live index):为文档设置一个超时时间,当达到预设值的时间后,该文档会被数据库自动删除。对于缓存非常有用db.eventlog.createIndex( { "lastModifiedDate": 1 }, { expireAfterSeconds: 3600 } )
-
-
复合键索引不具备生存时间特性
-
- Mongdb索引的管理:
-
- 索引的创建(一旦创建就不能修改,除非删除重建,不能重复创建一个索引)db.collection.createIndex( <key and index type specification>, <options> )
-
- Mongdb索引的管理:
- Keys 用来指明创建索引的字段以及排序方向:
db.student.createIndex({name:1,age:-1})
- Options:用来设置索引的属性以及其它辅助选项
db.student.createIndex({name:1,age:1},{name:’name_age’})

-
-
-
- 索引的查看
-
-
查看集合拥有的索引db.collection.getIndexes()

查询建立索引的键名 db.collection.getIndexKeys()
-
-
-
- 索引的重建
-
-
重建当前集合的所有索引 db.collection.reIndex()先删除在重建
查询索引的大小 db.a1.totalIndexSize()
-
-
-
- 索引的删除
-
-
db.collection.dropIndex(index)
index:可以是索引的名字,也可以是创建索引时的keys文档参数 db.student.dropIndex(‘name_age’) //索引名
db.student.dropIndex({name:1,age-1}) //keys参数
删除集合中所有的索引 db.collection.dropIndexes()
-
-
-
- 索引的查询解释器
-
-
db.collection.find().explain()
db.stu.find({age:22}).explain() db.stu.find({age:22}).explain(false)
db.stu.find({age:22}).explain(“queryPlanner”) queryPlanner:查询计划的选择器,首先进行查询分析,最终选择一个winningPlan是explain返回的默认层面。
hint函数:db.集合.find().hint(index) index参数可以是索引的名字(字符串)或者创建索引时使用的keys参数。
Mongdb限制每个集合上最多只能创建64个索引
- 特殊索引
- 2dsphere 球面索引-创建

- 2dsphere 球面索引-创建

-
- 2d平面索引

-
- 全文索引

- 权限认证
- 创建管理员账号
db.createUser({ user: “zhangsan”,pwd: “zhangsan123”,roles:[{ role:
“userAdmin AnyDatabase ", db: "admin" }] })
-
- 密码认证:db.auth(“zhangsan”,”zhangsan123”)
- 授权:db.grantRolesToUser("accountUser01",[{role:"read", db:"stock" } ], { w: "majority" , wtimeout: 4000 } )
- 修改用户密码:
db.changeUserPassword("accountUser", "SOh3TbYhx8ypJPxmt1oOfL")
删除用户(只删除当前数据中的football用户)
-
- 删除账号:db.dropUser("football");
- 关闭mongdb服务:db.shutdownServer();
- 聚合
- 聚合管道的概述
-
- 聚合管道由阶段组成,文档在一个阶段处理完毕后,聚合管道会将结果传递给下一个阶段
- 针对聚合功能提供三种方式:聚合管道,单目的聚合操作,MapReduce编程模式
- MongoDB Shell使用db.collection.aggregate([{<stage>},…])来构建和使用聚合管道。
- 聚合管道的作用:对文档进行过滤筛选符合条件的文档;对文档进行变换,改变文档输出格式
-
- 聚合管道操作符
-
- $project
-
- 聚合管道的概述
-
-
-
- $match
-
-

-
-
-
- $limit:{ $limit: <positive integer> }限制返回的文档数量
-
-
db.article.aggregate([ { $limit : 5 } ]);
-
-
-
- $skip:{ $skip: <positive integer> }跳过指定数量的文档
-
-
db.article.aggregate( { $skip : 5 } );
-
-
-
- $group:例如:db.books.aggregate( [ { $group : { _id : "$author", books: { $push: "$title" } } } ] )
- $sort:{ $sort: { <field1>: <sort order>, <field2>: <sort order> ... } }
-
-
排序db.users.aggregate( [ { $sort : { age : -1, posts: 1 } } ] )
-
-
-
- Out:{ $out: "<output-collection>" }
-
-
db.books.aggregate( [ { $group : { _id : "$author", books: { $push: "$title" } } }, { $out : "authors" } ] )
-
-
-
- $unwind:{ $unwind: <field path> },参数是数组类型将文档按照数组字段拆分成多条文档,每条文档包含数组中的一个元素
- $lookup:
-
-

-
-
-
- 聚合管道表达式
-
-

-
- 单目的聚合操作
常用的主要有两个:count和distinct
- 与Java
看雪梨TXT的第三题


- GridFS文件系统
- GridFS是mongdb提供的二进制数据的存储解决方案,是专门为大数据文件存储提供的存储方案
- GridFS用两个集合来存储一个文件:fs.files 与 fs.chunks
- Mongofiles的使用:
-
- 上传文件mongofiles -d gfs put d:/demo/baidu.jpg
- 显示文件列表:mongofiles -d gfs list
- 下载文件:mongofiles -d gfs get
- 删除 delete 搜索search
-
- 复制集
- MongoDB的复制至少需要两个节点。其中一个是主节点,负责处理客户端请求,其余的都是从节点,负责复制主节点上的数据。
- 各个节点的属性

-
- 复制集的搭建:①启动多个mongdb实例②连接任意一台mongdb实例(主节点)mongo –port27017 ③(主节点)初始化复制集 rs.initiate()④(主节点)查看复制集的状态 rs.status()⑤(主节点)另外两个从节点加入复制集rs.add(“127.0.0.1:27018”)
- 添加冲裁节点:①启动仲裁节点所需的mongdb实例②连接上主节点③添加仲裁节点到副本集中rs.addArb(“127.0.0.1:27020”)④查看复制集状态
- 将从节点变为仲裁者
1、确认该节点与所有客户端都断开连接2、关闭该从节点3、(主节点)将从节点从REPL的配置信息中删除rs.remove(“127.0.0.1:27019”)
4、(主节点)确认复制集已经没有该节点rs.conf()
5、将从节点的数据目录删除或者重命名6、创建新的目录供仲裁节点使用
7、启动仲裁节点所需的mongodb实例8、连接上主节点mongo --port 27018 9、添加仲裁节点到副本集中 10、查看复制集的状态
-
- 分片
- 分片的优势:使用分片来支持具有非常大的数据集和高吞吐量的操作的部署。
- 三种服务器:路由服务器,分片服务器,配置服务器
- 为了将一个集合的所有文档进行分片,mongdb通过shard key进行数据集的分割
- Mongdb将分片后的数据存在chunk中
- 两种分片策略:哈希分片,范围分片
- Redis简介
- redis的特性:①开源免费②支持持久化③存储类型丰富④支持数据备份
- redis的适用场合:①实时消息系统②排行榜③精准设定过期时间④计数器⑤最新N的数据操作
- redis相比memcached有哪些优势:①memcached所有的值均是简答的字符串,redis作为替代者,支持更为丰富的数据类型②redis的速度比memcached快很多③redis可以持久化其数据
- redis简介:本质上是一个key-value类型的内存数据库,很像memcached,整个数据库统统加载在内存当中进行操作,定期通过异步操作把数据库数据flush到硬盘上进行保存

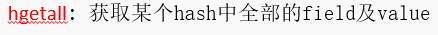
- Redis的数据类型及操作
- String




-
- List


-
- Hash


![]()
-
- Set





-
- Zset


-
- HyperLogLog

- Redis常用命令
- 键值相关命令:

-
- 服务器相关命令:

- Redis高级特性
- 持久化
-
- 快照是默认的持久化方式。这种方式是将内存中的数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
- Redis 是一个持久化的内存数据库
- Redis 提供了不同级别的持久化方式(内存的数据保存到磁盘上):
- RDB(Redis DataBase)持久化方式能够在指定的时间间隔能对你的数据进行快照(SnapShot )存储。
- AOF(Append Only File)持久化方式记录每次对服务器写的操作,当服务器重启的时候会重新执行这些命令来恢复原始的数据,AOF命令以redis协议追加保存每次写的操作到文件末尾,Redis还能对AOF文件进行后台重写,使得AOF文件的体积不至于过大。
-
- 持久化
-
- Rdb的优点与缺点
优点:①RDB是一个非常紧凑的文件②RDB在保存RDB文件时父进程唯一需要做的就是fork出一个子进程,接下来的工作全部由子进程来做,父进程不需要再做其他IO操作,所以RDB持久化方式可以最大化redis的性能.③与AOF相比,在恢复大的数据集的时候,RDB方式会更快一些
缺点:①数据丢失风险大 ②RDB需要经常fork子进程来保存数据集到硬盘上,当数据集比较大的时候,fork的过程是非常耗时的,可能会导致Redis在一些毫秒级内不能响应客户端的请求
-
- Aof的优点与缺点
优点:①AOF文件是一个只进行追加的日志文件 ②使用AOF 会让你的Redis更加灵活: 你可以使用不同的fsync策略 ③redis可以在 AOF 文件体积变得过大时,自动地在后台对 AOF 进行重写 ④AOF文件有序地保存了对数据库执行的所有写入操作, 这些写入操作以 Redis 协议的格式保存, 因此 AOF 文件的内容非常容易被人读懂, 对文件进行分析也很轻松
缺点:①对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积 ②根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB
-
- Redis事务的相关命令有哪几个 ①MULTI②EXEC③DISCARD④WATCH
- 主从复制
- 主从复制原理
通过主从复制可以允许多个slave server拥有和master server相同的数据库副本。 主从复制特点:
-
-
-
- master可以拥有多个slave
- 多个slave可以连接同一个master外,还可以互相连接
- 主从复制不会阻塞master,在同步数据时,master可以继续处理client请求 ④提高系统的伸缩性
- 主从复制过程
- slave与master建立连接,发送sync同步命令 ②master会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存。③后台完成保存后,就将此文件发送给slave ④slave将此文件保存到硬盘上
-
- Redis发布/订阅(RUB/SUB)
-

-
- 安全性:设置客户端连接后进行任何命令前需要使用的密码
- Redis-Sentinel机制 故障切换的原理:
以上是关于超硬核!兔兔阿里p7学长给的面试知识库的主要内容,如果未能解决你的问题,请参考以下文章
超硬核!16000 字 Redis 面试知识点总结,这还不赶紧收藏?
Github 上超硬核 Java 面试 “备战” 仓库,真香~