垂直扩展+水平扩展
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了垂直扩展+水平扩展相关的知识,希望对你有一定的参考价值。
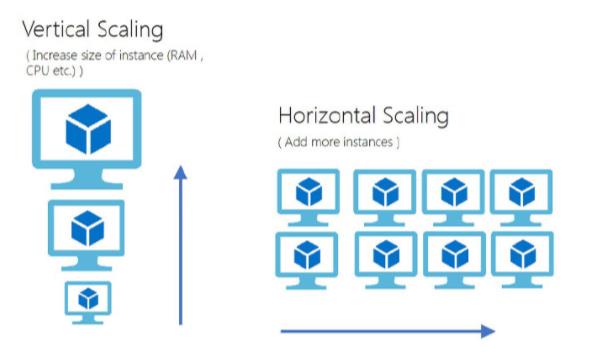
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
高并发相关常用的一些指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等。
响应时间:系统对请求做出响应的时间。例如系统处理一个HTTP请求需要200ms,这个200ms就是系统的响应时间。
QPS:每秒响应请求数。在互联网领域,这个指标和吞吐量区分的没有这么明显。
并发用户数:同时承载正常使用系统功能的用户数量。例如一个即时通讯系统,同时在线量一定程度上代表了系统的并发用户数。
互联网分布式架构设计,提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。
(1)增强单机硬件性能,例如:增加CPU核数如32核,升级更好的网卡如万兆,升级更好的硬盘如SSD,扩充硬盘容量如2T,扩充系统内存如128G;
(2)提升单机架构性能,例如:使用Cache来减少IO次数,使用异步来增加单服务吞吐量,使用无锁数据结构来减少响应时间;
在互联网业务发展非常迅猛的早期,如果预算不是问题,强烈建议使用“增强单机硬件性能”的方式提升系统并发能力,因为这个阶段,公司的战略往往是发展业务抢时间,而“增强单机硬件性能”往往是最快的方法。
不管是提升单机硬件性能,还是提升单机架构性能,都有一个致命的不足:单机性能总是有极限的。所以互联网分布式架构设计高并发终极解决方案还是水平扩展。
水平扩展:只要增加服务器数量,就能线性扩充系统性能。水平扩展对系统架构设计是有要求的,如何在架构各层进行可水平扩展的设计,以及互联网公司架构各层常见的水平扩展实践,是本文重点讨论的内容。
(1)客户端层:典型调用方是浏览器browser或者手机应用APP
(3)站点应用层:实现核心应用逻辑,返回html或者json
反向代理层的水平扩展,是通过“DNS轮询”实现的:dns-server对于一个域名配置了多个解析ip,每次DNS解析请求来访问dns-server,会轮询返回这些ip。
当nginx成为瓶颈的时候,只要增加服务器数量,新增nginx服务的部署,增加一个外网ip,就能扩展反向代理层的性能,做到理论上的无限高并发。
站点层的水平扩展,是通过“nginx”实现的。通过修改nginx.conf,可以设置多个web后端。
当web后端成为瓶颈的时候,只要增加服务器数量,新增web服务的部署,在nginx配置中配置上新的web后端,就能扩展站点层的性能,做到理论上的无限高并发。
站点层通过RPC-client调用下游的服务层RPC-server时,RPC-client中的连接池会建立与下游服务多个连接,当服务成为瓶颈的时候,只要增加服务器数量,新增服务部署,在RPC-client处建立新的下游服务连接,就能扩展服务层性能,做到理论上的无限高并发。如果需要优雅的进行服务层自动扩容,这里可能需要配置中心里服务自动发现功能的支持。
在数据量很大的情况下,数据层(缓存,数据库)涉及数据的水平扩展,将原本存储在一台服务器上的数据(缓存,数据库)水平拆分到不同服务器上去,以达到扩充系统性能的目的。
(1)规则简单,service只需判断一下uid范围就能路由到对应的存储服务;
(3)比较容易扩展,可以随时加一个uid[2kw,3kw]的数据服务;
(1)请求的负载不一定均衡,一般来说,新注册的用户会比老用户更活跃,大range的服务请求压力会更大;
每一个数据库,存储某个key值hash后的部分数据,上图为例:
(1)规则简单,service只需对uid进行hash能路由到对应的存储服务;
(1)不容易扩展,扩展一个数据服务,hash方法改变时候,可能需要进行数据迁移;
这里需要注意的是,通过水平拆分来扩充系统性能,与主从同步读写分离来扩充数据库性能的方式有本质的不同。
(1)每个服务器上存储的数据量是总量的1/n,所以单机的性能也会有提升;
(2)n个服务器上的数据没有交集,那个服务器上数据的并集是数据的全集;
(3)数据水平拆分到了n个服务器上,理论上读性能扩充了n倍,写性能也扩充了n倍(其实远不止n倍,因为单机的数据量变为了原来的1/n);
缓存层的水平拆分和数据库层的水平拆分类似,也是以范围拆分和哈希拆分的方式居多,就不再展开。
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。
提高系统并发能力的方式,方法论上主要有两种:垂直扩展(Scale Up)与水平扩展(Scale Out)。前者垂直扩展可以通过提升单机硬件性能,或者提升单机架构性能,来提高并发性,但单机性能总是有极限的,互联网分布式架构设计高并发终极解决方案还是后者:水平扩展。
(1)反向代理层可以通过“DNS轮询”的方式来进行水平扩展;
(4)数据库可以按照数据范围,或者数据哈希的方式来进行水平扩展;
各层实施水平扩展后,能够通过增加服务器数量的方式来提升系统的性能,做到理论上的性能无限。
当一个开发人员提升计算机系统负荷时,通常会考虑两种方式垂直扩展和水平扩展。选用哪种策略主要依赖于要解决的问题 以及系统资源的限制。在这篇文章中我们将讲述这两种策略并讨论每种策越的优缺点。如果你已经有一个软件系统需要不断成长,那么你将有意或者无意中选择这两 种策略中的一种。
在垂直扩展模型中,想要增加系统负荷就意味着要在系统现有的部件上下工夫,即通过提高系统部件的能力来实现。例如,假设你现在负责一批木材采伐的操作。

在这个例子中,我们假设有3辆卡车,每辆车一次可以运25根木材,计算花费1小时的情况下可以运送到指定地点等待处理的木材数量。通过这些数字我们可以算出我们系统最大的负荷量:
如果我们选择垂直扩展模型,那么我们将怎么做来使我们每小时可以处理150根木材?我们需要至少做以下两件事中的一件:
使每辆卡车的运输量增加一倍(50棵树每小时),或者使每辆卡车的运输时间减半(每辆卡车30分钟)。
3辆卡车 * 25棵树 * 30分钟 = 150棵树/每小时
我们没有增加系统的成员数,但是我们通过增加系统成员的生产效率来获得期望的负荷量。
在水平扩展模型中,我们不是通过增加单个系统成员的负荷而是简单的通过增加更多的系统成员来实现。也就是说,在以上运送木材的例子中,通过增加卡车的数量来运送木材。因此,当我们需要将负荷从75棵树每小时增加到150棵树每小时,那么只需要增加3辆卡车。
假如我们已经选择了垂直扩展方式,那么我们想要每小时处理150棵被砍伐的树时需要怎么做呢?我们需要做到以下两方面之一:要么使每辆卡车的运输量翻倍(50棵木材一次),要么使每辆开车的运输时间减半(30分钟)。
3辆卡车 * 50棵树 * 30分钟 = 150棵树/每小时
在这个例子中,系统每个成员的生产力依然没变,我们通过增加更多的卡车来提高系统的能力。
通过对水平扩展和垂直扩展的基本了解,下面让我们来关注web系统的扩展。一个网站通常有很多组件都需要去考虑它们的扩展性,但是我通常喜欢关注处在最边缘的一个:数据库。为什么数据库是最边缘的?因为数据库通常是共享资源,是几乎所有请求最终的连接点。
在 扩展你的数据库时,你必须要问的一个重要问题是:“我所面对的系统是什么类型的?”你所面对的是一个读操作多还是写操作多的系统?读操作多的网站一般包 括:在线商城,在商城里用户大部时间是在浏览(读操作),只有少数时间在付款(写操作)、或者博客,在博客上人们大部分时间是在浏览博文(读操作),只有 少数时间是在评论或者发表博文(写操作)。相反的,关于写操作非常多的很好的例子包括:信用卡交易处理器,这个系统的主要负载时在处理记录交易(写操 作),偶尔会查找交易(读操作)、或者Google分析,主要工作实在记录业务数据(写操作),偶尔会展示分析图(读操作)。
了解你所创建的网站是什么类型的,可以在网站成长过程中帮助你选择正确的技术。
如 果你的系统读操作非常多,那么通过关系型数据库如mysql或者PostgreSql来垂直扩展数据存储是一个不错的选择。结合你的关系型数据库通过使用 memcached或者CDN来构建一个健壮的缓存系统,那么你的系统将非常容易扩展。在这种模式中,如果数据库超负荷运行,那么将更多的数据放入缓存中 来缓解系统的读压力。当没有更多的数据往缓存中放时,可以更换更快的数据存储硬件或者买更多核的处理器来获取更多的运行通道。摩尔定律使通过这种方法来垂 直扩展变得和购买更好的硬件一样简单。
如 果你的系统写操作非常多,那么你可能更希望考虑使用可水平扩展的数据存储方式,比如Riak,Cassandra或者HBase。和大多数关系型数据管理 系统不同,这种数据存储随着增长增加更多的节点。由于你的系统大部分时间是在写入,所以缓存曾并不能像在读操作比较频繁的系统中起到那么大作用。很多写频 繁的系统一开始使用垂直扩展的方式,但是很快发现并不能根本解决问题。为什么?因为硬盘数和处理器数在某一点达到平衡,在这个边界上再增加一个处理器或者 一个硬盘都会是每秒钟的I/O操作数成指数性增长。相反,如果对写频繁的系统采取水平扩展策略,那么你将达到一个拐点,在这个拐点之后如果在增加一个节点 都远比使用更多的硬盘来的实惠。
另 一件事需要记住的是每种扩展策略下预想不到的开销。采用垂直扩展的系统将开销凡在单独的组件上。当我们去提升系统负荷时,这些单独的组件需要在管理上花费 更多。拿我们运送木材的例子来说,如果需要使每辆卡车的货运量翻倍,那么我们需要更宽、更长、或者更高的车厢。也许有的路因为桥的高度对车辆高度有要求, 或者基于巷子宽度车宽不能太大,又或者由于机动车安全驾驶要求车厢不能太长。这里的限制就是对单个卡车做垂直扩展做的什么程度。同样的概念延伸到服务器垂 直扩展:更多的处理器要求更多的空间,进而要求更多的服务器存储架。
相反的,采用水平扩展的系统将额外的开销放在系统中连接起来的共享组件 上。当我们去提升系统负荷时,共享的开销和新增加的成员之间的协调性有关。在我们运送木材的例子中,当我们在路上增加更多卡车时,那么路就是共享资源也就 成了约束条件。这条路上适合同时跑多少量卡车?我们是否有足够的安全缓冲区使得所有的车可以同时装运木材?如果再来看我们水平扩展的数据库系统,那么经常 被忽略的开销就是服务器同时连接时的网络开销(译者注:网络为各个系统的共享资源)。当你为系统增加更多的节点时,共享资源的负荷也就越来越重,通常呈非 线性改变。
和 计算机的大多数东西一样,好的解决办法通常并不像我这里列出来的这么简单。而我在这里尝试简化这种思想用来来说明这中概念而不是讲具体的解决办法。扩展是 个困难的问题,这是个需要在实际处理的每个步骤中都要思考的问题。扩展策略没有魔法,也没有魔法般的软件帮你建立一个完整可靠的可扩展系统。就像扩展中的 其他问题一样,一个大的解决方案通常是由很多个一起协调工作的小的解决办法组成的。这需对每一个中解决方案进行精心正确的设计和开发。
参考:[转]理解水平扩展和垂直扩展
以上是关于垂直扩展+水平扩展的主要内容,如果未能解决你的问题,请参考以下文章
使用 AWS ECS Fargate 进行水平和垂直自动扩展
在任何浏览器维度的中间居中垂直和水平可扩展的 div [重复]