汉字识别基于贝叶斯网络实现汉字识别matlab源码
Posted Matlab咨询QQ1575304183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了汉字识别基于贝叶斯网络实现汉字识别matlab源码相关的知识,希望对你有一定的参考价值。
一、简介
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本、非线性及高维模式识别中表现出许多特有的优势,并能够推广应用到函数拟合等其他机器学习问题中。
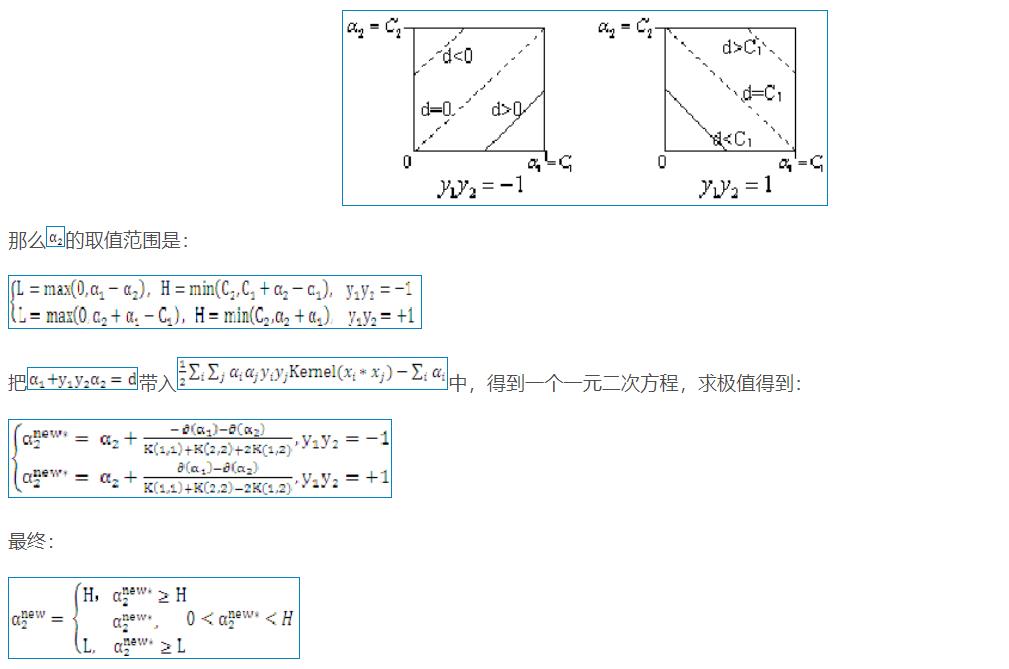
1 数学部分
1.1 二维空间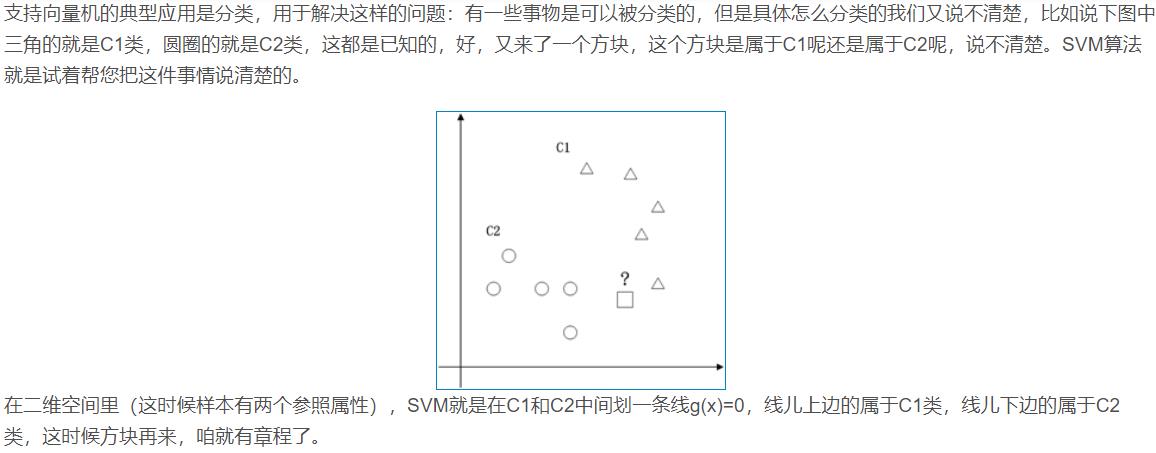


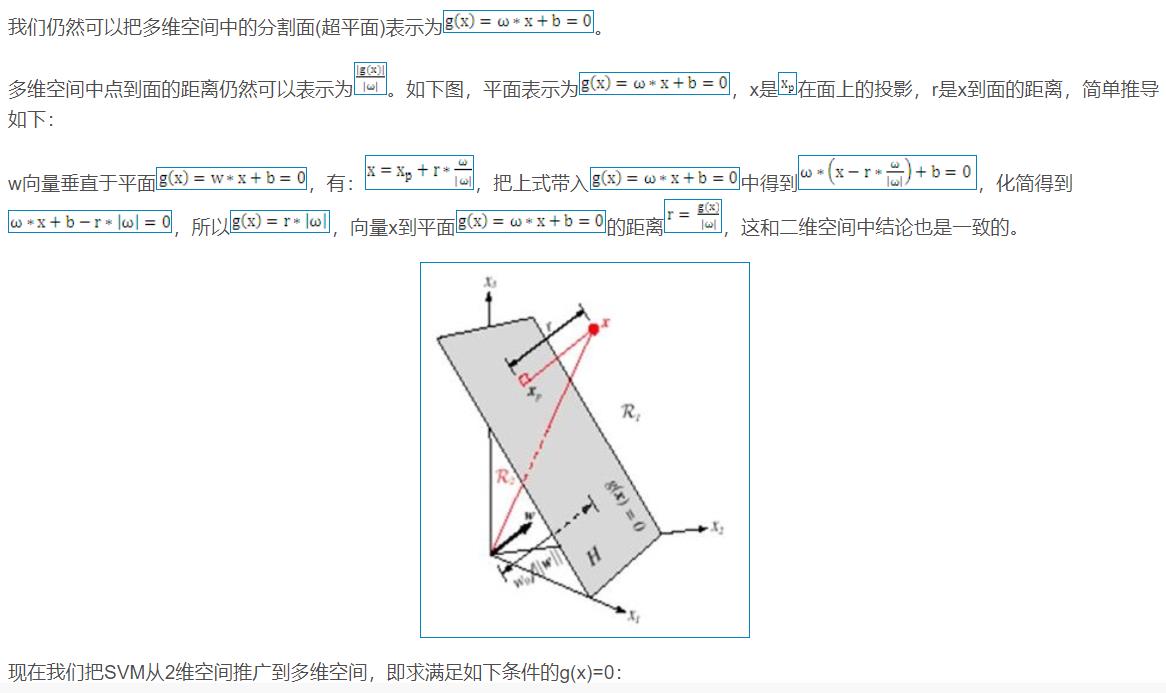





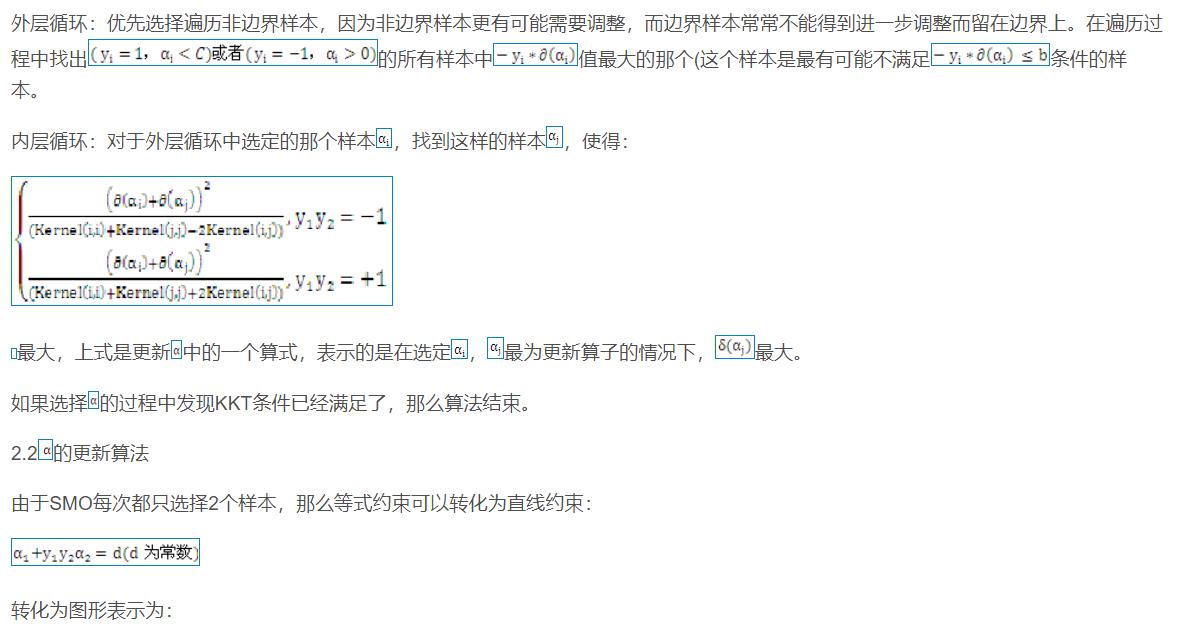
2 算法部分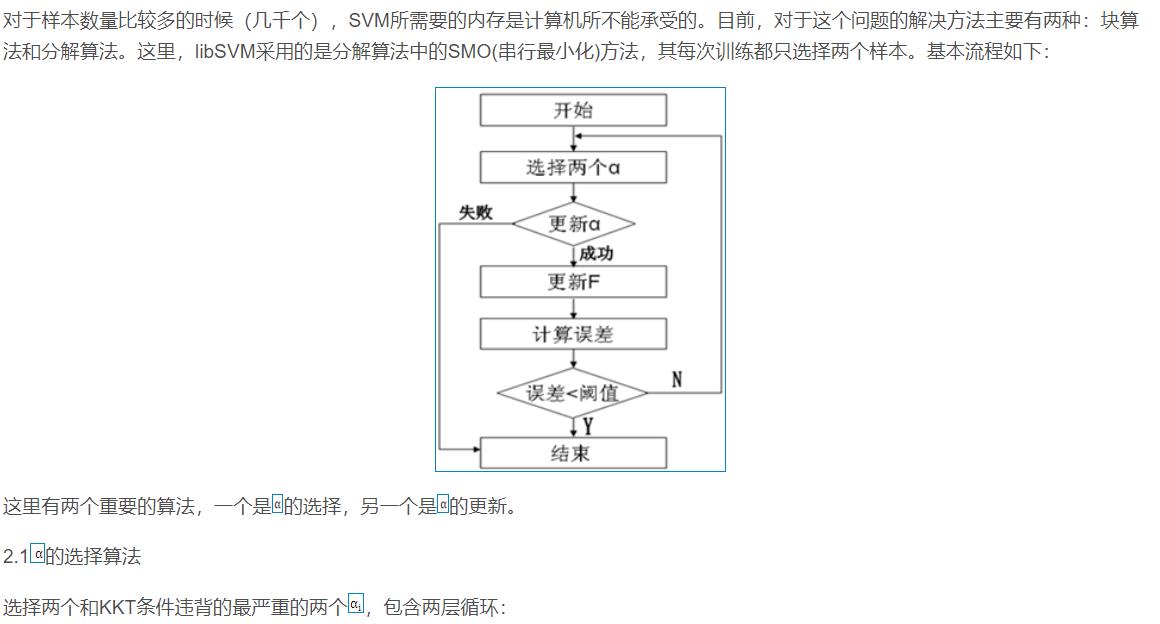

二、源代码
clc,clear,close
for i=1:5
imp=imread(['.\\字库',num2str(i),'.jpg']);
create_database(imp,i);
end
load templet pattern;
aa=imread('example_1.png');
[word cnum]=get_picture(aa);
%cc=imresize(aa,[120 90]);
for i=1:cnum
class=bayesBinaryTest(word{i});
Code(i)=pattern(class).name;
end
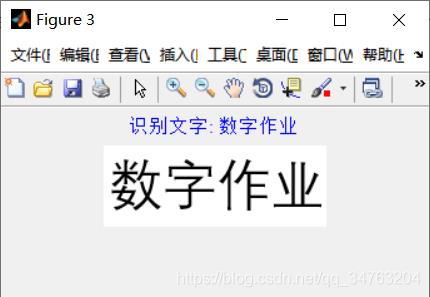
figure(3);
imshow(aa);
tt=title(['识别文字: ', Code(1:cnum)],'Color','b');
function y = bayesBinary(sample)
%基于概率统计的贝叶斯分类器
%sample为要识别的图片的特征(1列100行的概率)
clc; %清屏
load templet pattern; %加载汉字特征
sum = 0; %初始化sum
prior = []; %先验概率
p = []; %各类别代表点
likelihood = []; %类条件概率
pwx = []; %贝叶斯概率
%%计算先验概率
for i=1:12
sum = sum+pattern(i).num; %特征总数
end
for i=1:12
prior(i) = pattern(i).num/sum; %出现每个汉字的可能性(先验概率)
end
%%计算类条件概率
for i=1:12 %12个汉字
for j=1:100 %100个模块
sum = 0;
for k=1:pattern(i).num %特征数
if(pattern(i).feature(j,k)>0.05) %概率大于阈值0.05则数量+1
sum = sum+1;
end
end
p(j,i) = (sum+1)/(pattern(i).num+2);%计算概率估计值即Pj(ωi),注意拉普拉斯平滑处理
end
end
for i=1:12
sum = 1;
for j=1:100
if(sample(j)>0.05)
sum = sum*p(j,i);%如果待测图片当前概率大于0.05认为特征值为1,直接乘Pj(ωi)
else
sum = sum*(1-p(j,i));%如果待测图片当前概率小于0.05认为特征值为0,乘(1-Pj(ωi))
end
end
likelihood(i) = sum; %将类条件概率赋值给likelihood
end
%%计算后验概率
sum = 0;
for i=1:12
sum = sum+prior(i)*likelihood(i); %求和即得P(X)
end
for i=1:12
pwx(i) = prior(i)*likelihood(i)/sum; %贝叶斯公式
end
三、运行结果
完整代码或仿真咨询QQ1575304183
以上是关于汉字识别基于贝叶斯网络实现汉字识别matlab源码的主要内容,如果未能解决你的问题,请参考以下文章