Spark RDD编程
Posted 皓洲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark RDD编程相关的知识,希望对你有一定的参考价值。
Spark RDD编程
需要用到的技术:Spark、Hadoop集群、Scala
实验内容
现有大约500万条搜索引擎产生的记录,数据格式如下:

每一行包含6个字段:字段1代表数据产生的时间;字段2代表用户,即UID;字段3代表用户搜索关键词;字段4代表URL超链接在返回结果中的排名;字段5代表用户单击超链接的顺序号;字段6代表用户单击的URL超链接的地址。
请编写Scala程序,实现如下功能:
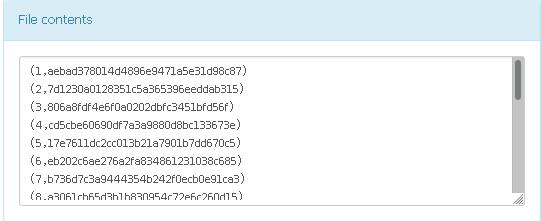
(1)统计用户数量,输出格式如下:

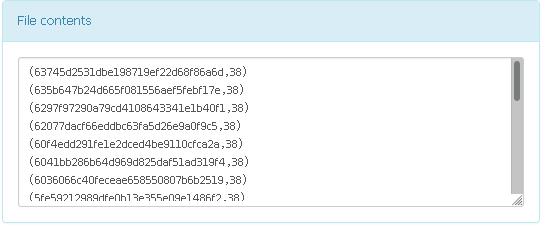
(2)统计搜索次数在20次及以上的用户UID及搜索次数,输出格式(按照搜索次数降序排列,搜索次数相同时按UID升序排列)如下:

注意:(1)数据请上传至HDFS;
(2)统计结果保存至HDFS。
实验思路
(1)思路:拿到数据后先提出所有用户id,然后去重,排序之后统计,顺便输出行号
(2)思路:将用户id和数字1设为一个元组,合并相同的key值然后value值相加,最后倒序输出次数多的,搜索次数相同时按UID升序
任务一
启动spark
- 启动Zookeeper集群、启动hdfs集群、启动yarn集群、启动spark
代码
package spark.zhz
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* @author zhz
* @date 2021/5/27 16:05
* 备注:
*/
object UserCount {
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
//设置名称
conf.setAppName("My-Spark-Work")
//设置集群master节点访问地址
conf.setMaster("spark://centos01:7077");
//创建SparkContext对象,该对象是提交Spark程序的入口
val sc = new SparkContext();
//读取指定路径,生成RDD集合
val linesRDD:RDD[String] = sc.textFile(args(0))
//得到用户列表
val test = "qwe"
val usersRDD:RDD[String] = linesRDD.map(_.split("\\t")(1))
//去除重复用户
val tmpRDD:RDD[(String, Int)] = usersRDD.map((_, 1))
val reduceRDD:RDD[(String, Int)] = tmpRDD.reduceByKey((x,y)=>x+y)
//去除辅助value
val reduceUserRDD:RDD[String] = reduceRDD.map(line=>{line._1})
//添加行号
val indexRDD:RDD[(String, Long)] = reduceUserRDD.zipWithIndex().map{case(x, y)=>(x, y+1)}
//调整排序得到结果
val resultRDD:RDD[(Long, String)] = indexRDD.map(line => {(line._2, line._1)})
//保存结果到指定路径(取第二运行参数)
resultRDD.saveAsTextFile(args(1))
sc.stop();
}
}
执行程序
bin/spark-submit \\
--master yarn \\
--class spark.zhz.UserCount \\
/mnt/hgfs/share/spark.jar \\
/input \\
/userOutput
任务二
代码
package spark.zhz
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
/**
* @author zhz
* @date 2021/5/27 21:03
* 备注:
*/
object SearchCount{
def main(args: Array[String]): Unit = {
//创建SparkConf对象,存储应用程序的配置信息
val conf = new SparkConf()
//设置名称
conf.setAppName("My-Spark-Work")
//设置集群master节点访问地址
conf.setMaster("spark://centos01:7077");
//创建SparkContext对象,该对象是提交Spark程序的入口
val sc = new SparkContext();
//分割数据
val linesRDD:RDD[String] = sc.textFile(args(0))
val usersRDD:RDD[String] = linesRDD.map(_.split("\\t")(1))
val paresRDD:RDD[(String, Int)] = usersRDD.map((_,1))
//合并用户记录
val userCountsRDD:RDD[(String, Int)] = paresRDD.reduceByKey((x,y)=>x+y)
//排序
val tmpRDD = userCountsRDD.map(a =>(new MySortClass(a._1, a._2), a))
val userCountsSortRDD = tmpRDD.sortByKey()
//如果大于等于20,则返回结果
val resultRDD = userCountsSortRDD.map(a=>{if(a._2._2>=20)a._2})
resultRDD.saveAsTextFile(args(1))
sc.stop();
}
}
二次排序
package spark.zhz
/**
* @author zhz
* @date 2021/5/27 21:03
* 备注:该class用于辅助实现二次排序
*/
class MySortClass(val x:String, val y:Int) extends Serializable with Ordered[MySortClass] {
override def compare(that: MySortClass): Int = {
if (!this.y.equals(that.y)) {
this.y - that.y
}
else {
this.x.hashCode - that.x.hashCode
}
}
}
结果
以上是关于Spark RDD编程的主要内容,如果未能解决你的问题,请参考以下文章