5.贝叶斯算法单词拼写错误案例
Posted to.to
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了5.贝叶斯算法单词拼写错误案例相关的知识,希望对你有一定的参考价值。
5.贝叶斯算法
5.1.单词拼写错误案例
5.贝叶斯算法
贝叶斯简介
- 贝叶斯(约1701-1761) Thomas Bayes,英国数学家。
- 贝叶斯方法源于他生前解决一个”逆概”问题写的一篇文章。
- 生不逢时,死后它的作品才被世人认可。
贝叶斯要解决的问题:
-
正向概率:假设袋子里面有N个白球,M个黑球,你伸手进去摸一把,摸出黑球的概率是多大
-
逆向概率:如果我们事先并不知道袋子里面黑白球的比例,而是闭着眼睛摸出一个(或好几个)球,观察这些取出来的球的颜色之后,那么我们可以就此对袋子里面的黑白球的比例作出什么样的推测
Why贝叶斯?
现实世界本身就是不确定的,人类的观察能力是有局限性的。
我们日常所观察到的只是事物表面上的结果,因此我们需要提供一个猜测。

- 男生总是穿长裤,女生则一半穿长裤一半穿裙子
- 正向概率:随机选取一个学生,他(她)穿长裤的概率和穿裙子的概率是多大。
- 逆向概率:迎面走来一个穿长裤的学生,你只看得见他(她)穿的是否长裤,而无法确定他(她)的性别,你能够推断出他(她)是女生的概率是多大吗?
假设学校里面人的总数是U个
穿长裤的(男生):U * P(Boy) * P(Pants|Boy)
- P(Boy)是男生的概率 = 60%
- P(Pants|Boy) 是条件概率,即在 Boy 这个条件下穿长裤的
穿长裤的(女生):U * P(Girl) * P(Pants|Girl)
求解:穿长裤的人里面有多少女生
穿长裤总数:U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)
P(Girl|Pants) = U * P(Girl) * P(Pants|Girl)/穿长裤总数
即:
U * P(Girl) * P(Pants|Girl) / [U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)]
与总人数有关吗?
- U * P(Girl) * P(Pants|Girl) / [U * P(Boy) * P(Pants|Boy) + U * P(Girl) * P(Pants|Girl)
- 容易发现这里校园内人的总数是无关的,可以消去
- P(Girl|Pants) = P(Girl) * P(Pants|Girl) / [P(Boy) * P(Pants|Boy) + P(Girl) * P(Pants|Girl)]
化简:
- P(Girl|Pants) = P(Girl) * P(Pants|Girl) / [P(Boy) * P(Pants|Boy) + P(Girl) * P(Pants|Girl)]
- 分母其实就是P(Pants)
- 分子其实就是P(Pants, Girl)
即:

由此推导出了贝叶斯公式:

5.1.单词拼写错误案例
import re, collections
import sys
# 把语料库的单词全部抽取出来,转写成小写,并去掉单词中间的特殊符号
def words(text):
return re.findall('[a-z]+', text.lower())
"""
如果遇到一个语料库中没有的单词怎么办?
假如说一个单词拼写正确,但是语料库中没有包含这个词,从而这个词也永远不会出现现在的训练集中。if 于是我们要返回出现这个词的概率是0
代表这个事件绝对不可能发生而在我们的概率模型中我们期望用一个很小的概率来代表这种情况。lambda:1
"""
def train(features):
model = collections.defaultdict(lambda: 1)
for f in features:
model[f] += 1
return model
NWORDS = train(words(open('./data/big.txt').read()))
alphabet = 'abcdefghijklmnopqrstuvwxyz'
"""
编辑距离:两个词之间的编辑距离定义为使用了几次插入(在词中插入一个单字母),交换(交换相邻两个字母),
替换(把一个字母换成另一个)的操作从一个词变到另一个词
"""
# 返回所以与单词w编辑距离为1的集合
def editsl(word):
n = len(word)
return set([word[0:i] + word[i + 1:] for i in range(n)] + # deletion
[word[0:i] + word[i + 1] + word[i] + word[i + 2:] for i in range(n - 1)] + # transposition
[word[0:i] + c + word[i + 1:] for i in range(n) for c in alphabet] + # alteration
[word[0:i] + c + word[i:] for i in range(n + 1) for c in alphabet]) # insertion
# 返回所有与单词w编辑距离为2的单词集合
# 在这些编辑距离小于2的中间,只把那些正确的词作为候选词
def know_edits2(word):
return set(e2 for e1 in editsl(word) for e2 in editsl(e1) if e2 in NWORDS)
def known(words):
return set(w for w in words if w in NWORDS)
def correct(words):
candidates = known([words]) or known(editsl(words)) or know_edits2(words) or [words]
return max(candidates, key=lambda w: NWORDS[w])
def main():
while True:
str = input("input word:")
if str == 'break':
return
c = correct(str)
print(c)
if __name__ == '__main__':
main()
在控制台输入内容:
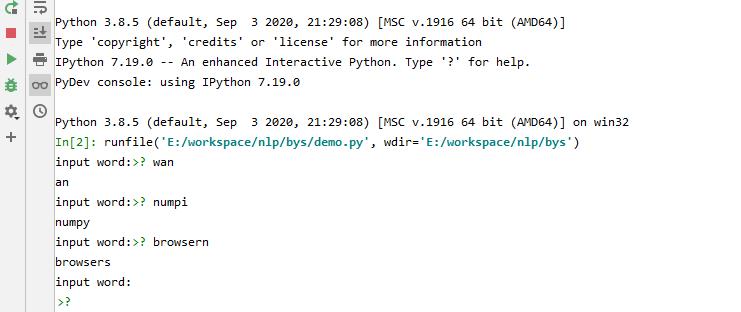
./data/big.txt的内容如下:
Spring Cloud provides tools for developers to quickly build some of the common patterns in distributed systems (e.g. configuration management, service discovery, circuit breakers, intelligent routing, micro-proxy, control bus, one-time tokens, global locks, leadership election, distributed sessions, cluster state). Coordination of distributed systems leads to boiler plate patterns, and using Spring Cloud developers can quickly stand up services and applications that implement those patterns. They will work well in any distributed environment, including the developer’s own laptop, bare metal data centres, and managed platforms such as Cloud Foundry.
Spring Cloud focuses on providing good out of box experience for typical use cases and extensibility mechanism to cover others.
Distributed/versioned configuration Service registration and discovery Routing
Service-to-service calls Load balancing Circuit Breakers Global locks Leadership election and cluster state Distributed messaging
Getting Started Generating A New Spring Cloud Project The easiest way to get started is visit start.spring.io, select your Spring Boot version and the Spring Cloud projects you want to use. This will add the corresponding Spring Cloud BOM version to your Maven/Gradle file when you generate the project.
Adding Spring Cloud To An Existing Spring Boot Application If you an existing Spring Boot app you want to add Spring Cloud to that app, the first step is to determine the version of Spring Cloud you should use. The version you use in your app will depend on the version of Spring Boot you are using.
The table below outlines which version of Spring Cloud maps to which version of Spring Boot.
The server certificate is a public entity. It is sent to every client that connects to the server. The private key is a secure entity and should be stored in a file with restricted access, however, it must be readable by nginx’s master process. The private key may alternately be stored in the same file as the certificate:
in which case the file access rights should also be restricted. Although the certificate and the key are stored in one file, only the certificate is sent to a client.
SSL operations consume extra CPU resources. On multi-processor systems several worker processes should be run, no less than the number of available CPU cores. The most CPU-intensive operation is the SSL handshake. There are two ways to minimize the number of these operations per client: the first is by enabling keepalive connections to send several requests via one connection and the second is to reuse SSL session parameters to avoid SSL handshakes for parallel and subsequent connections. The sessions are stored in an SSL session cache shared between workers and configured by the ssl_session_cache directive. One megabyte of the cache contains about 4000 sessions. The default cache timeout is 5 minutes. It can be increased by using the ssl_session_timeout directive. Here is a sample configuration optimized for a multi-core system with 10 megabyte shared session cache:
Some browsers may complain about a certificate signed by a well-known certificate authority, while other browsers may accept the certificate without issues. This occurs because the issuing authority has signed the server certificate using an intermediate certificate that is not present in the certificate base of well-known trusted certificate authorities which is distributed with a particular browser. In this case the authority provides a bundle of chained certificates which should be concatenated to the signed server certificate. The server certificate must appear before the chained certificates in the combined file:
Most machine learning workflows involve working with data, creating models, optimizing model parameters, and saving the trained models. This tutorial introduces you to a complete ML workflow implemented in PyTorch, with links to learn more about each of these concepts.
We’ll use the FashionMNIST dataset to train a neural network that predicts if an input image belongs to one of the following classes: T-shirt/top, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, or Ankle boot. This tutorial assumes a basic familiarity with Python and Deep Learning concepts.
To define a neural network in PyTorch, we create a class that inherits from nn.Module. We define the layers of the network in the __init__ function and specify how data will pass through the network in the forward function. To accelerate operations in the neural network, we move it to the GPU if available.
We will use a problem of fitting y=sin(x) with a third order polynomial as our running example. The network will have four parameters, and will be trained with gradient descent to fit random data by minimizing the Euclidean distance between the network output and the true output.
Numpy provides an n-dimensional array object, and many functions for manipulating these arrays. Numpy is a generic framework for scientific computing; it does not know anything about computation graphs, or deep learning, or gradients. However we can easily use numpy to fit a third order polynomial to sine function by manually implementing the forward and backward passes through the network using numpy operations:
Numpy is a great framework, but it cannot utilize GPUs to accelerate its numerical computations. For modern deep neural networks, GPUs often provide speedups of 50x or greater, so unfortunately numpy won’t be enough for modern deep learning.
Here we introduce the most fundamental PyTorch concept: the Tensor. A PyTorch Tensor is conceptually identical to a numpy array: a Tensor is an n-dimensional array, and PyTorch provides many functions for operating on these Tensors. Behind the scenes, Tensors can keep track of a computational graph and gradients, but they’re also useful as a generic tool for scientific computing.
Also unlike numpy, PyTorch Tensors can utilize GPUs to accelerate their numeric computations. To run a PyTorch Tensor on GPU, you simply need to specify the correct device.
Here we use PyTorch Tensors to fit a third order polynomial to sine function. Like the numpy example above we need to manually implement the forward and backward passes through the network:
以上是关于5.贝叶斯算法单词拼写错误案例的主要内容,如果未能解决你的问题,请参考以下文章
机器学习贝叶斯算法详解 + 公式推导 + 垃圾邮件过滤实战 + Python代码实现