Day26:分布式NoSQL列存储数据库HBASE
Posted 保护胖丁
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day26:分布式NoSQL列存储数据库HBASE相关的知识,希望对你有一定的参考价值。
- 知识点01:回顾
- 知识点02:目标
- 知识点03:数据存储需求及HBASE诞生
- 知识点04:Hbase介绍
- 知识点05:HBASE设计思想
- 知识点06:HBASE中的对象概念
- 知识点07:HBASE中的存储概念
- 知识点08:HBASE中的按列存储
- 知识点09:HBASE集群架构
- 知识点10:HBASE集群部署
- 知识点11:HBASE开发场景
- 知识点12:HBASE命令行:DDL:NS
- 知识点13:HBASE命令行:DDL:Table
- 知识点14:HBASE命令行:Put
- 知识点15:HBASE命令行:Get
- 知识点16:HBASE命令行:Delete
- 知识点17:HBASE命令行:Scan
- 知识点18:HBASE命令行:incr & count
- 知识点19:Java API:构建连接
- 知识点20:Java API:DDL
- 附录一:Maven依赖
知识点01:回顾
-
Redis如何保证数据的安全性?
-
RDB:默认机制,在一定时间内发生一定次数数据更新,就构建内存全量快照文件进行存储
-
机制
-
手动:save、bgsave、flushall、shutdown
-
自动:配置文件
save 时间 次数
-
-
优点:更快【二进制文件】、更小【全量】、性能更好【后台异步生成】
-
缺点:在满足性能的前提下,可能会有一定概率不确定的部分数据丢失
-
-
AOF:优先级更高,需要手动开启,基于一定规则,将内存数据操作日志增量记录在日志文件中
- 机制
- always:内存中产生一条更新,立即同步记录在日志文件中
- 最安全,性能较差
- everysecond:每s将上一秒的更新,异步追加到日志文件中
- no:不由redis控制,由操作系统的刷写频率实现,不用
- always:内存中产生一条更新,立即同步记录在日志文件中
- 优点:更加安全,追加形式,性能和安全有中和性的选择
- 缺点:性能相对而言不如rdb,日志是增量的,会越来越大,是普通的文本,加载会比较慢
- 解决日志越来越大的问题,按照一定的条件构建全量的日志
- 机制
-
-
Redis的事务有什么特点?
- Redis是单线程
- Redis中的事务是命令的集合,不能保证原子性
- 一般不用
-
Redis的数据过期机制和内存淘汰机制是什么?
- 过期机制
- 命令:expire、setex
- 策略:定时、惰性、定期
- redis:惰性 + 定期
- 内存淘汰
- LRU:最近最少被使用
- 缓存:从所有的Key中通过LRU淘汰对应的数据
- 持久性:从所有有过期时间的Key中使用LRU进行淘汰
- 过期机制
-
Redis的主从复制集群、哨兵集群、分片集群各自有什么特点?
- 主从复制:主从架构
- 主节点提供读写
- 从节点只提供读,与主节点同步数据
- 优点:实现了读写分离,提高了读的并行度
- 缺点:主节点存在单点故障问题
- 哨兵集群:类似于ZK架构
- 设计:解决主节点单点故障问题
- 本质:基于主从复制集群之上构建哨兵监听机制
- 优点:实现集群的高可用
- 缺点:无法解决大数据量问题
- 分片集群:类似于Hadoop架构
- 设计:通过多个小的主从复制集群实现逻辑上合并为一个大的集群
- 分布式存储:将数据分布存储在不同的节点上,构建了分布式内存平台
- 分的规则:槽位分区:CRC16【K】 & 16383
- 数据安全:主从复制小集群来保证安全
- 主从复制:主从架构
知识点02:目标
- Hbase基本介绍
- 功能和应用场景
- 设计思想【核心】
- Hbase使用
- Hbase中概念【核心】
- Hbase架构和集群搭建【实现即可】
- Hbase的命令
- Hbase的Java API
知识点03:数据存储需求及HBASE诞生
-
目标:了解大数据存储业务需求及Hbase的诞生背景
-
路径
- step1:存储需求
- step2:Hbase诞生
-
实施
- 存储需求
- 早期需求:能实现大量数据的存储和计算
- HDFS:基于分布式磁盘的文件系统
- 现在需求:大数据要达到一个实时应用的效果
- 推荐系统、实时监控、机器学习
- 实时应用:实时采集、实时存储、实时计算、实时应用
- Flume
- 如何能实现实时的大数据量的存储?
- 早期需求:能实现大量数据的存储和计算
- Hbase诞生
- Google前三篇论文
- GFS =》 HDFS
- MR =》 MapReduce
- BigTable =》 Hbase
- Chubby =》 Zookeeper
- 解决了大数据实时随机读写的问题
- Google前三篇论文
- 存储需求
-
小结
- 了解大数据存储业务需求及Hbase的诞生背景
知识点04:Hbase介绍
- 目标:掌握Hbase的设计、功能及应用场景
- 实施
-
官方定义:http://hbase.apache.org/
- Hbase是一个基于Hadoop的分布式的可扩展的大数据存储的基于内存列存储NoSQL数据库
-
```
Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS.
```
- 可扩展的大数据存储:分布式
- 随机实时的访问大数据:基于内存存储
-
功能:提供分布式的实时随机的大数据持久性存储
-
应用
- 大数据量、高并发、高性能的结构化数据存储【读写】
- 电商:订单
- 交通:实时监控、实时车辆轨迹
- 金融:交易信息
-
小结
- Hbase的功能与应用场景是什么?
- 功能:实现分布式的实时随机的大数据量的持久性存储
- 应用:大数据、高并发、高性能、结构化存储
- Hbase的功能与应用场景是什么?
知识点05:HBASE设计思想
- 目标:掌握Hbase的设计思想
- 实施
- 核心思想:冷热数据分离
- 思考
- 要想解决大数据:分布式磁盘
- HDFS
- 要想性能非常高:基于内存
- Redis
- 要想解决大数据:分布式磁盘
- Hbase核心设计:分布式内存 + 磁盘
- 所有数据优先写入内存,如果内存达到一定阈值,将内存的数据写入磁盘
- 疑惑:数据刚开始在内存中,读写内存是比较快的,但是如果数据多了以后,数据会从内存写入磁盘,内存中没有了
- 下次读取就必须读取磁盘,读取磁盘怎么能实现实时呢?
- Hbase写入磁盘会构建有序的数据:基于有序的数据磁盘查询依旧是很快的
- Hbase适合数据存储场景:实时
- 数据读取的场景:数据一产生,就立即被采集存储,读取进行计算
- 冷热数据分离
- 冷数据:不经常被读取的数据
- 产生了一段时间的数据,该数据大概率情况下不会再被读取使用了
- 热数据:经常被读取的数据
- 刚产生的数据,立即被读取计算实现实时应用
- 思考
- 为什么Hbase读写速度比较快?
- 上层基于分布式内存:数据优先读写分布式内存
- 下层基于分布式磁盘:基于有序数据、基于列存储、列族设计、缓存设计
- 为什么Hbase可以支持大数据量?
- 数据存储:分布式内存 + 分布式磁盘
- Hbase与HDFS、Redis有什么区别?
- HDFS:离线,文件系统,分布式磁盘,永久性
- Redis:实时,NoSQL数据库,分布式内存,大数据量临时性/小数据量的永久性
- Hbase:实时,NoSQL数据,分布式内存+分布式磁盘,大数据量永久性
- 核心思想:冷热数据分离
- 小结
- 掌握Hbase的设计思想
知识点06:HBASE中的对象概念
-
目标:掌握Hbase中的对象的概念
-
路径
- step1:mysql中的对象
- step2:Hbase中的数据库概念
- step3:Hbase中的表概念
-
实施
-
MySQL中的对象
- 数据库:database
- create / use / drop
- 表:Table
- create / drop / desc / insert / delete / update / select
- 行:所有增删改查都是以行为单位,行是MySQL中的最小操作单元
- 问题:MySQL不同行能不能拥有不同列?
- insert into tbname(id,age) values()
- 问题:MySQL不同行能不能拥有不同列?
- 数据库:database
-
Hbase中的数据库概念NameSpace
-
NameSpace:命名空间,类似于MySQL中的数据库概念,Namespace中有多张表,Hbase中可以有多个Namespace
-
直接把它当做数据库来看
-
Hbase自带了两个Namespace
- default:默认自带的namespace
- hbase:存储系统自带的数据表
-
注意:与MySQL中数据库的概念有不一样的地方
-
Hbase中的NameSpace没有切换命令
- 访问表的两种方式:itcast/heima
-
-
绝对路径
- 数据库.表名:select * from itcast.heima;
-
相对路径
- 进入当前数据库:use itcast;- 直接操作表名:select * from heima;
-
Hbase中的每张表都必须属于某一个Namespace,将namespace当做表名的一部分,只能使用绝对路径来引用表
-
如果在对表进行读写时,必须加上namespace:tbname方式来引用
- 例如:namespace叫做itcast,里面有一张表叫做heima
itcast:heima-
如果不加namespace引用表的操作,这张表就默认为default的namespace下的表
heima
-
-
Hbase中的表概念Table
- Table:表,Hbase中的每张表都必须属于某一个Namespace
-
Hbase中的表时分布式结构,写入Hbase表的数据,会分布式存储到多台机器上
-
注意:在访问表时,如果这张表不在default的namespace下面,必须加上namespace:表名的方式来引用
-
- Table:表,Hbase中的每张表都必须属于某一个Namespace
-
-
小结
- 什么是NameSpace?
- 类似于MySQL中的数据库
- 引用表:namespace:tbname
- Hbase的表与MySQL的表有什么区别?
- Hbase的表是分布式的,表中的数据会分布式存储在不同的Hbase节点上
- 什么是NameSpace?
知识点07:HBASE中的存储概念
-
目标:掌握Hbase中的存储的概念
-
实施
-
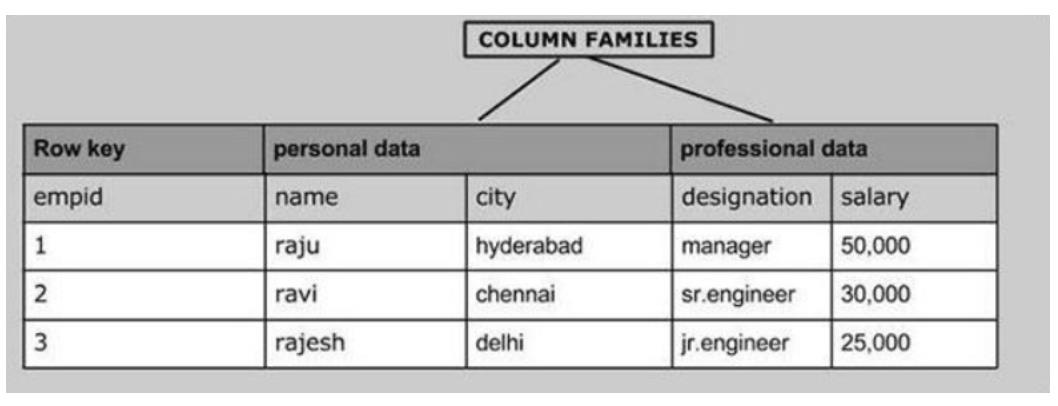
数据行设计Rowkey
-
Rowkey:行健,这个概念是整个Hbase的核心,类似于MySQL主键的概念
-
MySQL主键:可以没有,唯一标记一行、作为主键索引
-
Hbase行健
-
所有Hbase的表不用定义,自带行健这一列【行健这一列的值由用户自己设计】
-
唯一标识一行
-
作为Hbase表中的唯一索引
- Hbase不能创建索引
-
问题:查询数据走索引查询和全表扫描,只有按照rowkey查询才走索引查询
-
Hbase整个数据存储都是按照Rowkey实现数据存储的
-
-
-
列族设计ColumnFamily
-
cf:列族,对除了Rowkey以外的列进行分组,将列划分不同的组中
-
注意:任何一张Hbase的表,都至少要有一个列族,除了Rowkey以外的任何一列,都必须属于某个列族,Rowkey不属于任何一个列族
-
分组:将拥有相似IO属性的列放入同一个列族【要读一起读,要写一起写】
-
设计原因:划分列族,读取数据时可以加快读取的性能
- 如果没有列族,没有划分班级教室:找一个人,告诉你这个人就在这栋楼
- 如果有了列族,划分了教室:找一个人,告诉你这个人在这栋楼某个房间
-
-
-
-
数据列设计Qualifier
-
Qualifier/Column:列,与MySQL中的列是一样
-
注意
-
Hbase除了rowkey以外的任何一列都必须属于某个列族,引用列的时候,必须加上列族的名称
- 如果有一个列族:basic
- 如果basic列族中有两列:name,age
basic:name basic:age -
Hbase是列存储,Hbase中每一行拥有的列是可以不一样的
- 每个Rowkey可以拥有不同的列
-
-
-
-
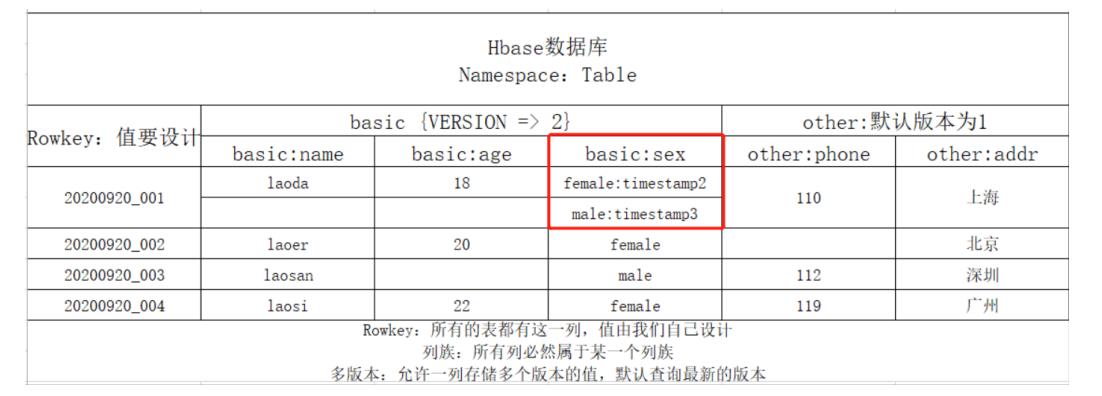
多版本设计VERSIONS
-
功能:某一行的任何一列存储时,只能存储一个值,Hbase可以允许某一行的某一列存储多个版本的值的
- 默认每一列都只能存储1个版本
-
级别:列族级别,指定列族中的每一列最多存储几个版本的值,来记录值的变化的
-
区分:每一列的每个值都会自带一个时间戳,用于区分不同的版本
- 默认情况下查询,根据时间戳返回最新版本的值
-
-
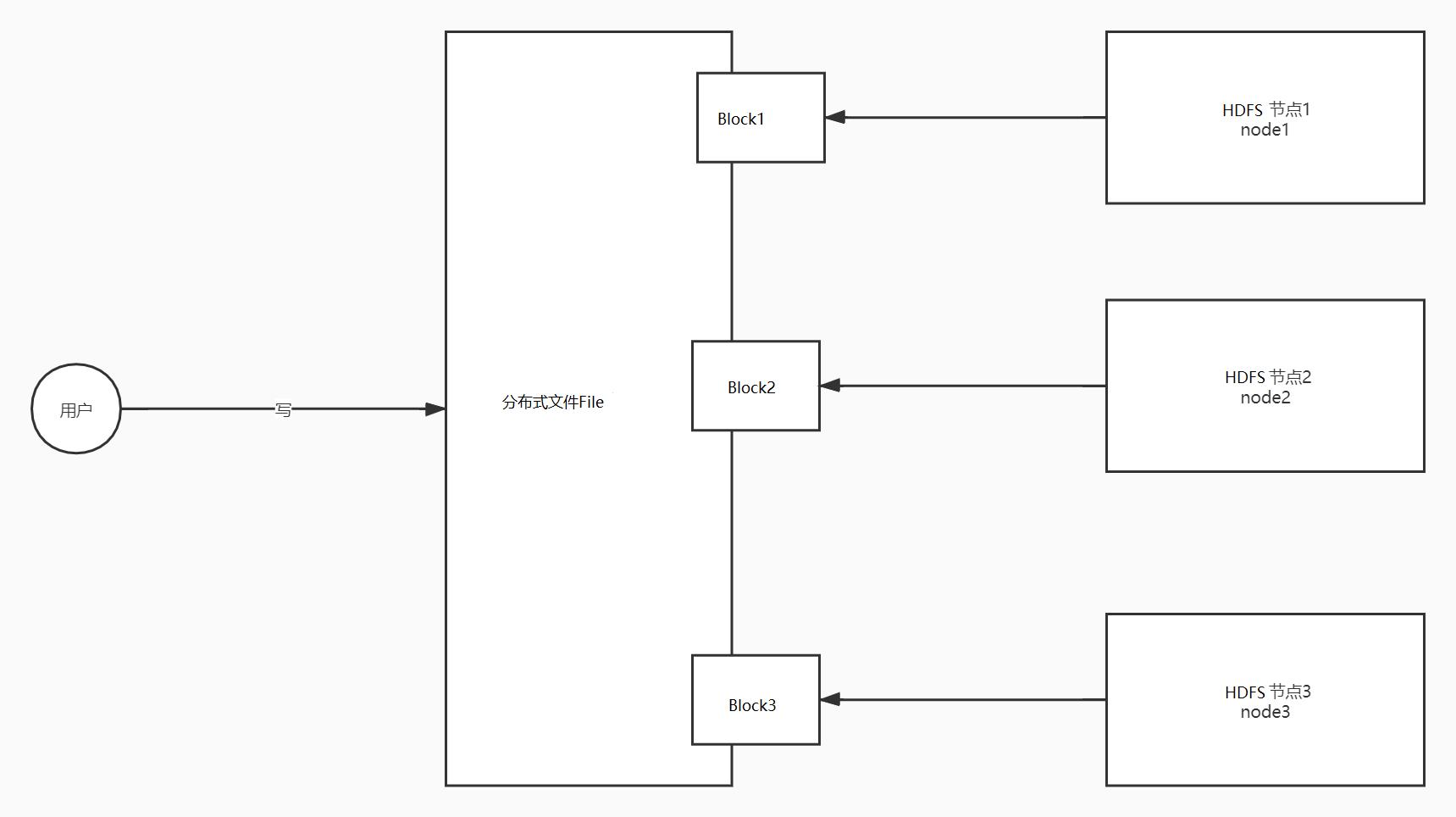
分布式设计
-
HDFS设计
-
文件夹
-
文件:划分Block:根据每128M划分一个块,每个Block存储在不同的机器上
-
-
- Hbase的表如何实现分布式存储的?
- Namespace
- Table
- ==**Region:分区**==,Hbase中任何一张都可以有多个分区,数据存储在表的分区中,每个分区存储在不同的机器上
- 非常类似于HDFS中Block的概念
- 划分规则:==范围分区==
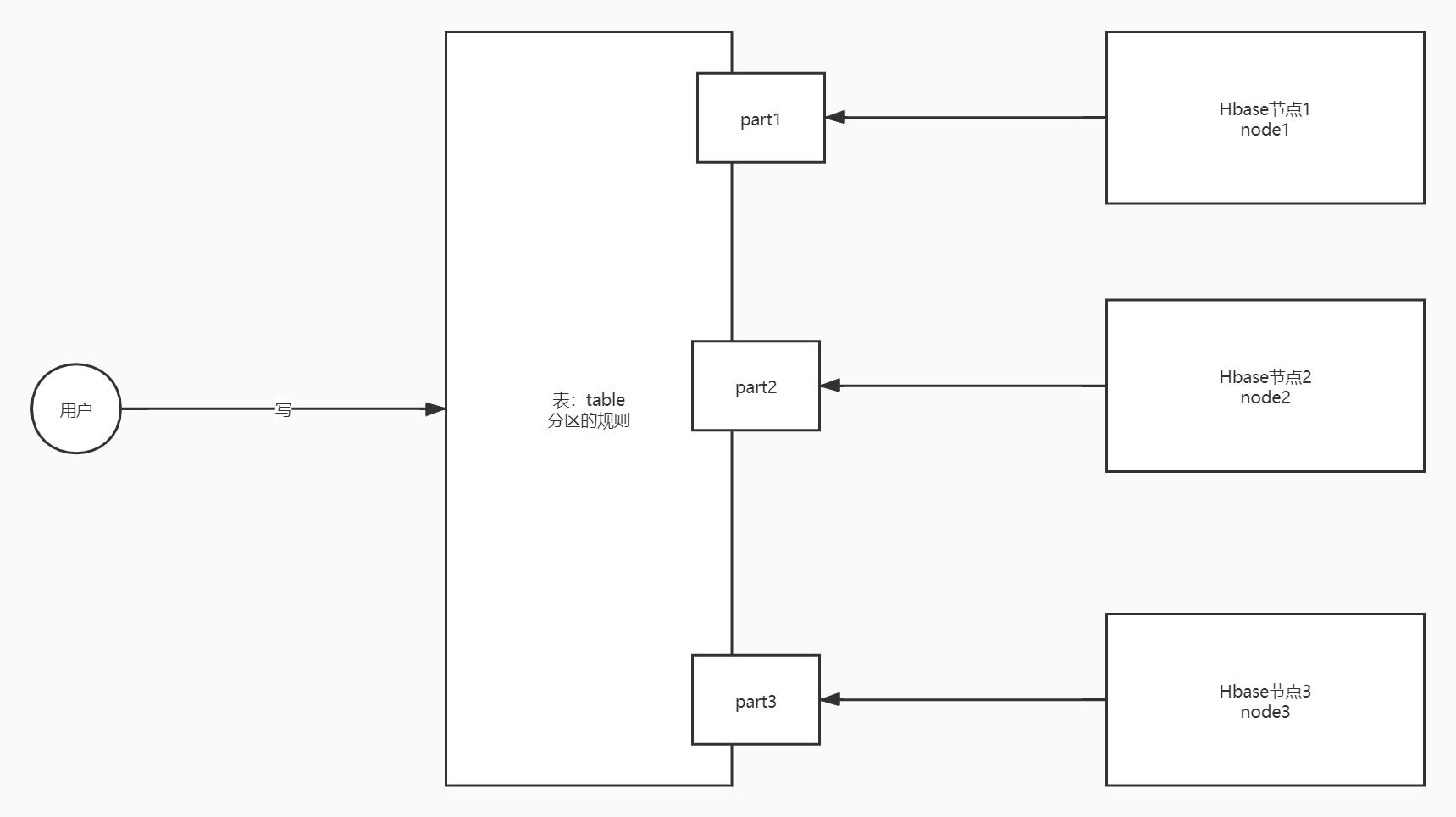
- 设计对比
| 分布式概念 | HDFS | Redis | Hbase |
| :--------: | :----------------: | :------: | :---------------: |
| 对象 | 目录 + 文件 | DB0 | Namespace + Table |
| 分布式 | Block | 分片集群 | Region |
| 划分规则 | 按照大小划分:128M | 槽位划分 | 按照范围划分 |
-
整体概念对比
概念 MySQL Hbase 数据库 DataBase NameSpace 数据表 Table Table【分布式的】 数据分区 - Region 数据行 主键+其他列 Rowkey+其他列 列族 - ColumnFamily 数据列 普通列与对应的值 列【timestamp】与对应的值【支持多版本】 -
小结
- 什么是行健Rowkey?
- 类似于主键概念
- 功能:唯一标识一行,作为Hbase唯一索引,不需要定义,自带这一列,值需要自己指定
- 什么是列族ColumnFamily?
- 本质:对列做了分组
- 规则:将拥有相似IO属性的列放入同一个列族,除了rowkey以外任何一列都必须属于某个列族,表至少有1个列族
- 什么是多版本?
- VERSIONS:一列的值可以存储多个版本
- 区分:通过时间戳进行区分
- 默认:每列只有1个版本的值,多版本场景下查询默认最新版本
- 什么是Region?
- 用于实现Hbase表的分布式的核心:Hbase表的分区
- 一张Hbase表可以有多个分区,每个分区存储在不同的Hbase节点上
- 分区:范围分区
- 什么是行健Rowkey?
知识点08:HBASE中的按列存储
- 目标:了解Hbase中的按列存储的设计
- 实施
-
功能
- Hbase的最小操作单元是列,不是行,可以实现对每一行的每一列进行读写
-
设计
- MySQL:按行存储,最小的操作单元是行
- insert:插入一行
- delete:删除一行
- ……
- Hbase:按列存储,最小操作单元是列
- 插入:为某一行插入一列
- 读取:只读某一行的某一列的
- 删除:只删除这一行的某一列
- MySQL:按行存储,最小的操作单元是行
-
举例
- MySQL中读取数据
- 查询【id,name,age,addr,phone……100列,每一列10M】:select id from table ;
- 先找到所有符合条件的行,将整行的数据所有列全部读取:1000M数据
- 再过滤id这一列:10M
- 查询【id,name,age,addr,phone……100列,每一列10M】:select id from table ;
- Hbase中读取数据
- 查询【id,name,age,addr,phone……100列,每一列10M】:select id from table ;
- 直接对每一行读取这一列的数据:10M
- MySQL中读取数据
-
总结
-
思想:通过细化了操作的颗粒度,来提高读的性能
-
如果按行存储:找一个人,告诉你这个人就在这栋楼某个房间的某一排
-
如果按列存储:找一个人,告诉你这个人在这栋楼某个房间的某一排的某一列
-
-
- 小结
- 了解Hbase中的按列存储的设计
知识点09:HBASE集群架构
-
目标:掌握Hbase集群的集群架构
-
实施
-
架构
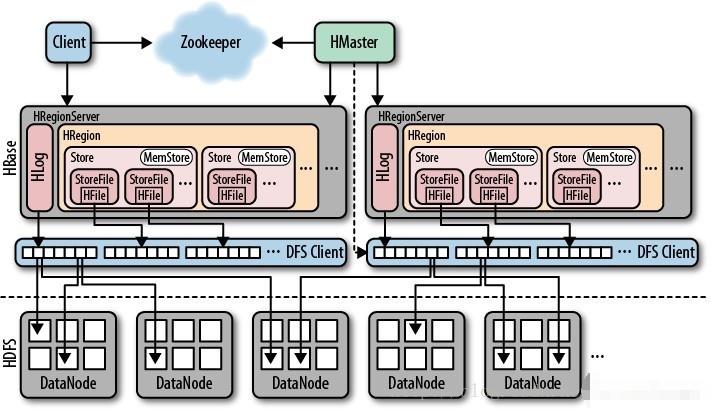
-
Hbase集群:分布式架构集群,主从架构
-
HMaster:主节点:管理节点
- 负责所有从节点的管理
- 负责元数据的管理
-
HRegionServer:从节点:存储节点
-
负责管理每张表的分区数据:Region
-
对外提供Region的读写请求
-
用于构建分布式内存
-
-
-
角色
- Hbase:通过RegionServer构建分布式内存
- 所有表的数据存储优先写入Regionserver内存中
- 如果内存达到阈值,将内存中的数据清空写入磁盘【HDFS】
- HDFS:用于实现分布式磁盘的构建,将RegionServer中内存中数据存储在HDFS上
- Zookeeper
- 存储核心元数据
- 辅助选举
- Hbase:通过RegionServer构建分布式内存
-
-
小结
- 掌握Hbase集群的集群架构
知识点10:HBASE集群部署
-
目标:实现Hbase分布式集群部署
-
实施
-
解压安装
-
上传HBASE安装包到第一台机器的/export/software目录下
cd /export/software/ rz -
解压安装
tar -zxvf hbase-2.1.0.tar.gz -C /export/server/ cd /export/server/hbase-2.1.0/
-
-
-
修改配置
-
切换到配置文件目录下
cd /export/server/hbase-2.1.0/conf/ -
修改hbase-env.sh
#28行 export JAVA_HOME=/export/server/jdk1.8.0_241 #125行 export HBASE_MANAGES_ZK=false -
修改hbase-site.xml
cd /export/server/hbase-2.1.0/ mkdir datas vim conf/hbase-site.xml<property > <name>hbase.tmp.dir</name> <value>/export/server/hbase-2.1.0/datas</value> </property> <property > <name>hbase.rootdir</name> <value>hdfs://node1:8020/hbase</value> </property> <property > <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>node1:2181,node2:2181,node3:2181</value> </property> -
修改regionservers
vim conf/regionserversnode1 node2 node3 -
配置环境变量
vim /etc/profile#HBASE_HOME export HBASE_HOME=/export/server/hbase-2.1.0 export PATH=:$PATH:$HBASE_HOME/binsource /etc/profile
-
-
分发
cd /export/server/ scp -r hbase-2.1.0 node2:$PWD scp -r hbase-2.1.0 node3:$PWD -
服务端启动与关闭
-
step1:启动HDFS
start-dfs.sh -
step2:启动ZK
/export/server/zookeeper-3.4.6/bin/start-zk-all.sh -
step3:启动Hbase
start-hbase.sh
-
- 关闭:先关闭Hbase再关闭zk
```
stop-hbase.sh
stop-zk-all.sh
stop-dfs.sh
```
-
测试
-
访问Hbase Web UI
node1:16010 Apache Hbase 1.x之前是60010,1.x开始更改为16010 CDH版本:一直使用60010
-
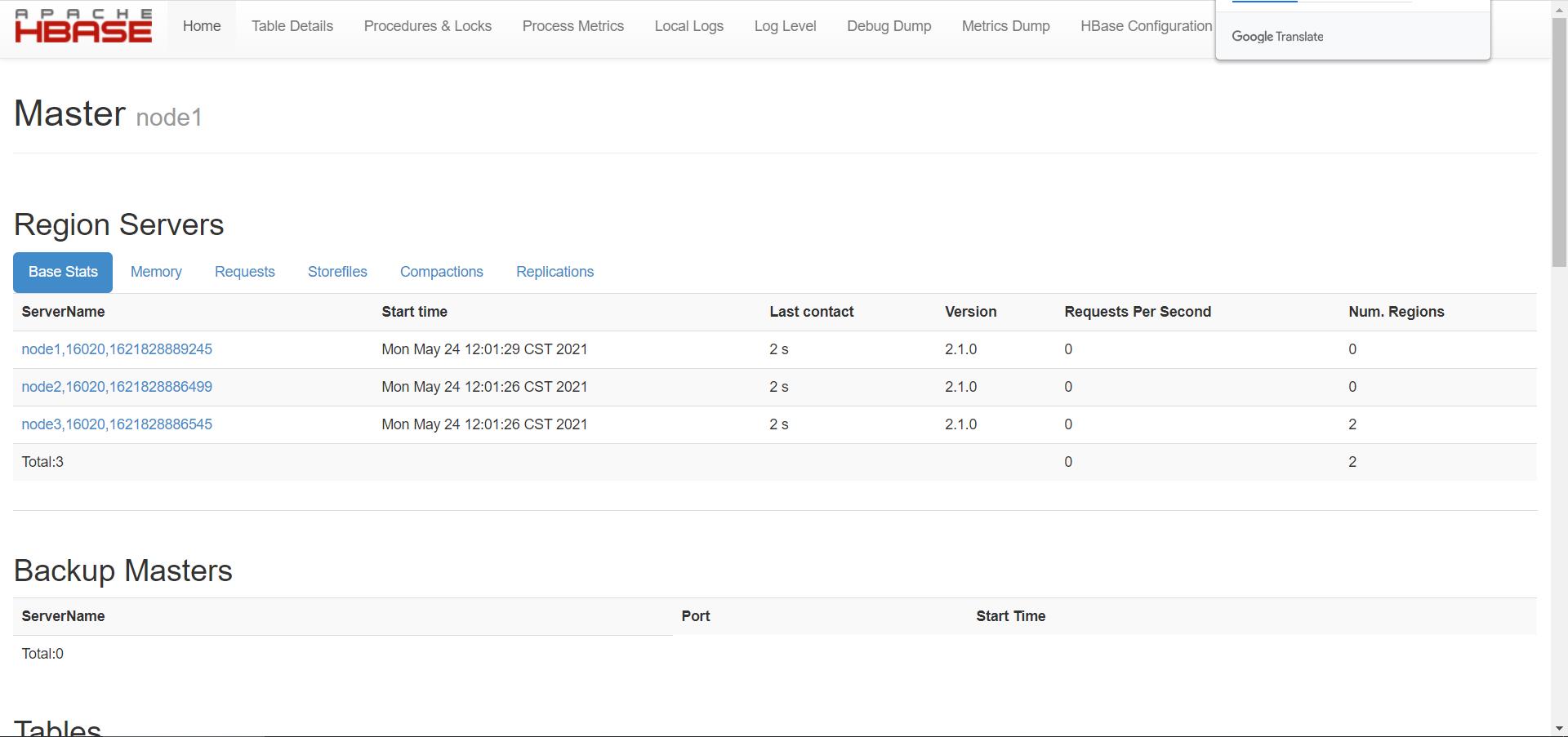
-
搭建Hbase HA
-
关闭Hbase所有节点
stop-hbase.sh -
创建并编辑配置文件
vim conf/backup-mastersnode2 -
启动Hbase集群
-
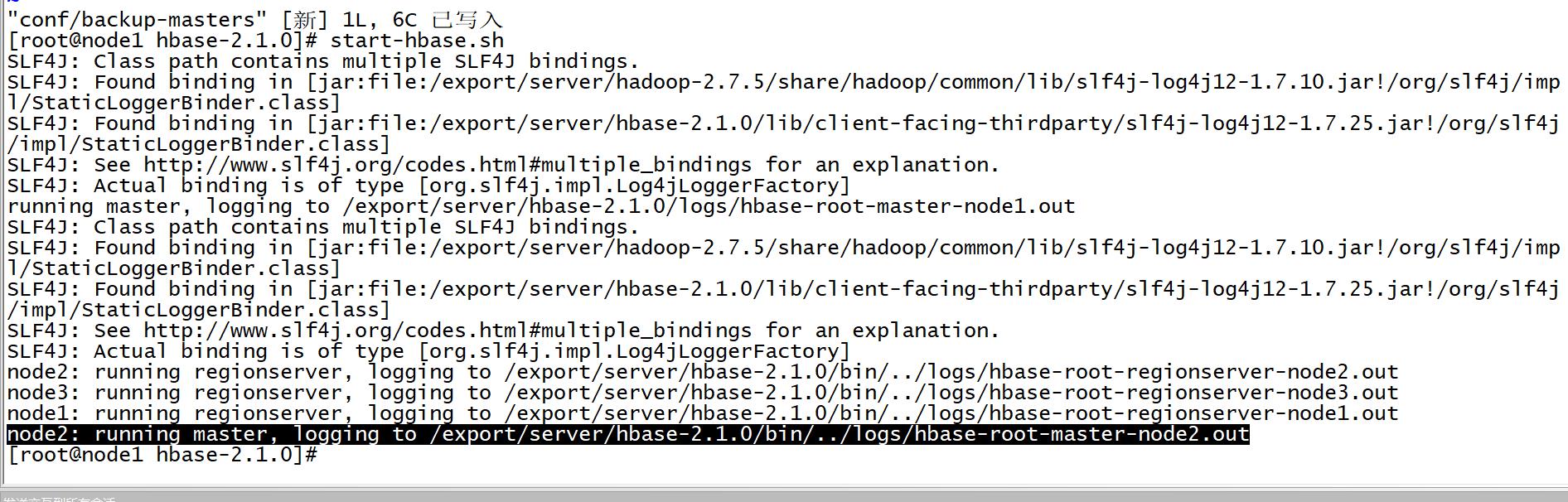

-
测试HA
- 启动两个Master,强制关闭Active Master,观察StandBy的Master是否切换为Active状态
hbase-daemon.sh stop master
-
【测试完成以后,删除配置,只保留单个Master模式】
-
小结
- 实现Hbase分布式集群部署
知识点11:HBASE开发场景
-
目标:了解Hbase使用过程中的不同开发场景
-
实施
-
场景1:集群管理
-
应用场景:运维做运维集群管理,我们开发用的不多
-
需求:封装Hbase集群管理命令脚本
-
类似于hive -f xxx.sql
-
举个栗子:每天Hbase集群能定时的自动创建一张表
-
分析
-
要实现运行Hbase脚本:创建表:/export/data/hbase_create_day.sh
#!/bin/bash create 'tbname','cf1'- 问题是:怎么能通过Linux命令行运行Hbase的命令呢?
-
要实现定时调度:Linux Crontab、Oozie、Azkaban
00 00 * * * sh /export/data/hbase_create_day.sh
-
-
-
实现:通过Hbase的客户端运行命令文件,通过调度工具进行调度实现定时运行
-
用法:hbase shell 文件路径
-
step1:将Hbase的命令封装在一个文件中:vim /export/data/hbase.txt
list exit -
step2:运行Hbase命令文件
hbase shell /export/data/hbase.txt -
step3:封装到脚本
#!/bin/bash hbase shell /export/data/hbase.txt
-
-
注意:所有的Hbase命令文件,最后一行命令必须为exit
-
导入测试数据
- 数据中的字段信息
-
-

- step1:先上传文件
- step2:运行文件
```
hbase shell /export/data/ORDER_INFO.txt
```
- step3:查看表中数据
```
scan 'ORDER_INFO',{FORMATTER=>'toString'}
```
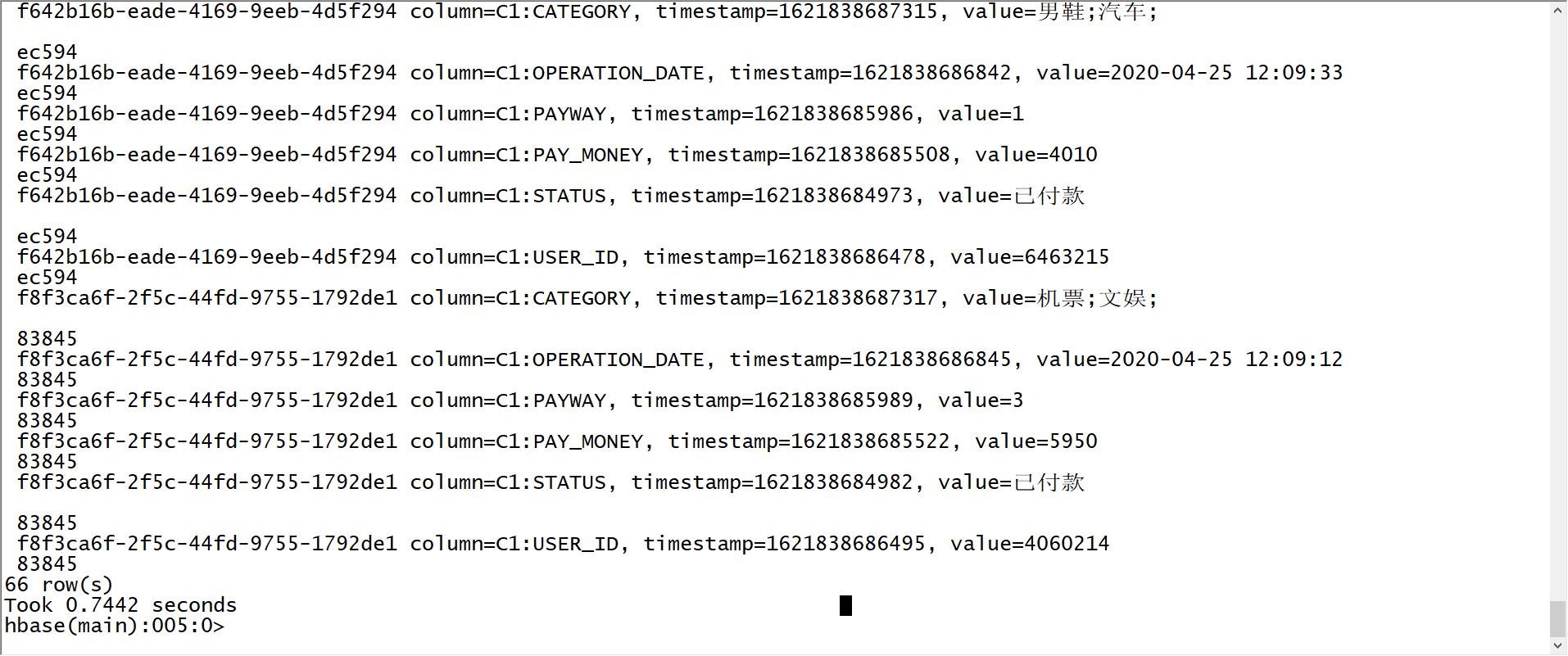
-
场景2:测试开发
-
需求:一般用于测试开发,执行DDL操作,类似于SQL之类的命令
-
实现:Hbase shell命令行
-
用法:hbase shell
-
命令
- 查看帮助:help
- 查看命令的用法:help ‘command’
-
-
场景3:生产开发
-
需求:一般用于生产开发,通过MapReduce或者Spark等程序读写Hbase,类似于JDBC
- 举个栗子:读取Hbase中的数据,进行分析处理,统计UV、PV
- 分析
- step1:通过分布式计算程序Spark、Flink读取Hbase数据
- step2:对读取到的数据进行统计分析
- step3:保存结果
-
实现:分布式计算程序通过Java API读写Hbase,实现数据处理
-
用法:在MapReduce或者Spark中集成API
-
-
小结
- 了解Hbase使用过程中的不同开发场景
知识点12:HBASE命令行:DDL:NS
-
目标:掌握Hbase中的常用DDL的NameSpace管理命令
-
实施
-
NameSpace管理
Group name: namespace
Commands: alter_namespace, create_namespace, describe_namespace, drop_namespace, list_namespace, list_namespace_tables- **列举所有Namespace** - 命令:list_namespace - SQL:show databases - 语法 ``` list_namespace ``` - 示例 ``` list_namespace ``` -
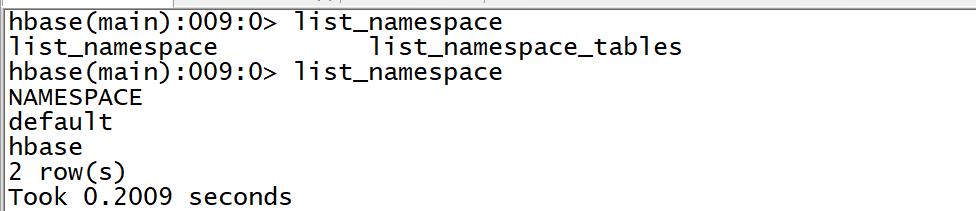
-
列举某个NameSpace中的表
-
命令:list_namespace_tables
- SQL:show tables in dbname
-
语法
list_namespace_tables 'Namespace的名称' -
示例
list_namespace_tables 'hbase'
-
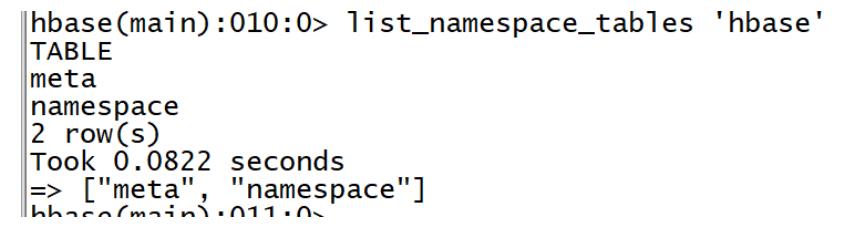
-
创建
-
命令:create_namespace
- SQL:create database dbname
-
语法
create_namespace 'Namespace的名称'- 示例
create_namespace 'heima' create_namespace 'itcast'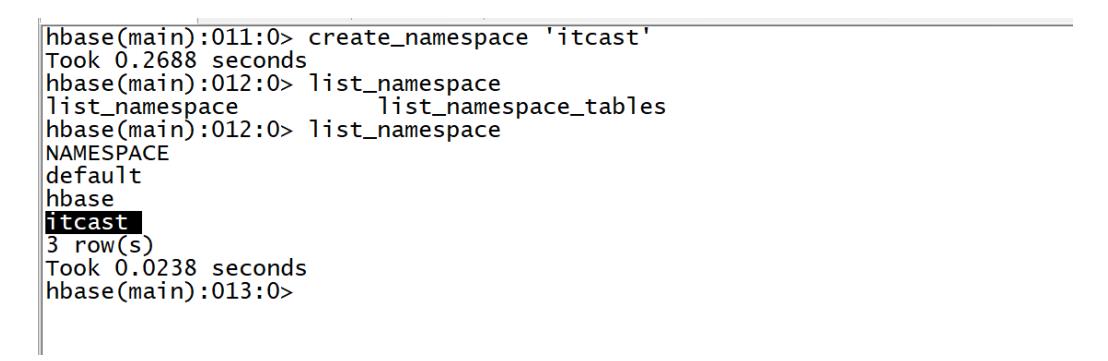
-
删除
-
命令:drop_namespace
- 只能删除空数据库,如果数据库中存在表,不允许删除
-
语法
drop_namespace 'Namespace的名称' -
示例
drop_namespace 'itcast' drop_namespace 'heima'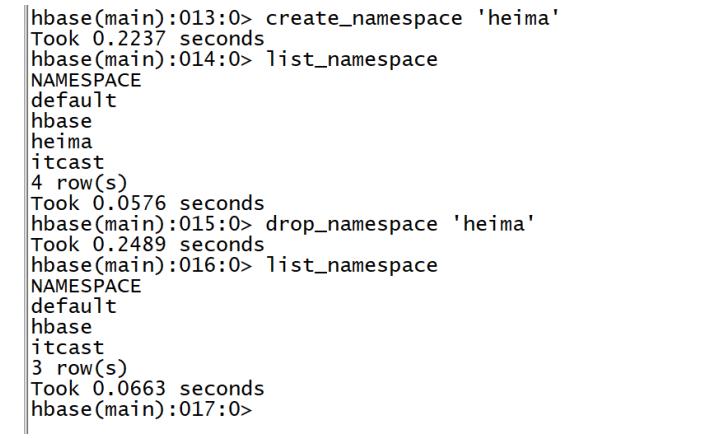
-
-
小结
- 掌握Hbase中的常用DDL的NameSpace管理命令
知识点13:HBASE命令行:DDL:Table
-
目标:掌握Hbase中的常用DDL表的命令
-
实施
Group name: ddl
Commands: alter, alter_async, alter_status, clone_table_schema, create, describe, disable, disable_all, drop, drop_all, enable, enable_all, exists, get_table, is_disabled, is_enabled, list, list_regions, locate_region, show_filters
-
列举
-
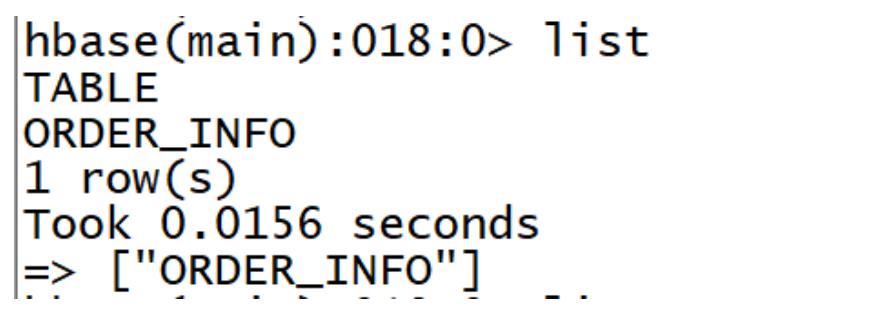
命令:list
- SQL:show tables
-
语法: list
-
示例
list
-
创建
-
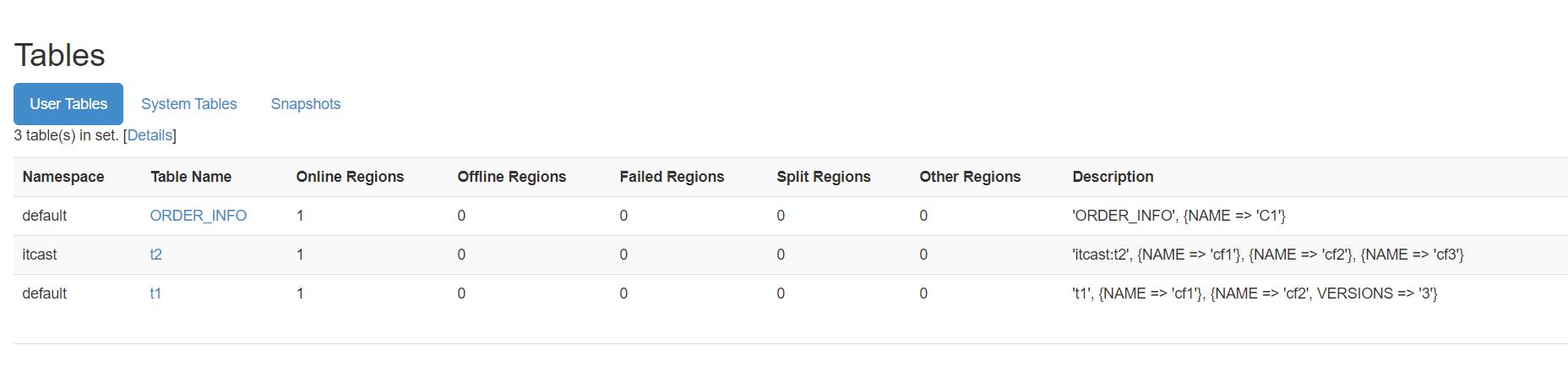
命令:create
-
SQL:表名 + 列的信息【名称和类型】
create table tbname(
col1
col2
col3
……
);- Hbase:必须指定表名 + 至少一个列族 - 表名 - 至少一个列族 -
-
语法
#表示在ns1的namespace中创建一张表t1,这张表有一个列族叫f1,这个列族中的所有列可以存储5个版本的值 create 'ns1:t1', {NAME => 'f1', VERSIONS => 5} #在default的namespace中创建一张表t1,这张表有三个列族,f1,f2,f3,每个列族的属性都是默认的 create 't1', 'f1', 'f2', 'f3' -
示例
#如果需要更改列族的属性,使用这种写法 create 't1',{NAME=>'cf1'},{NAME=>'cf2',VERSIONS => 3} #如果不需要更改列族属性 create 'itcast:t2','cf1','cf2','cf3' = create 't1',{NAME=>'cf1'},{NAME=>'cf2'},{NAME=>'cf3'}
-
-
查看
-
命令:desc
- SQL :desc tbname
-
语法
desc '表名' -
示例
desc 't1'
-

-
删除
-
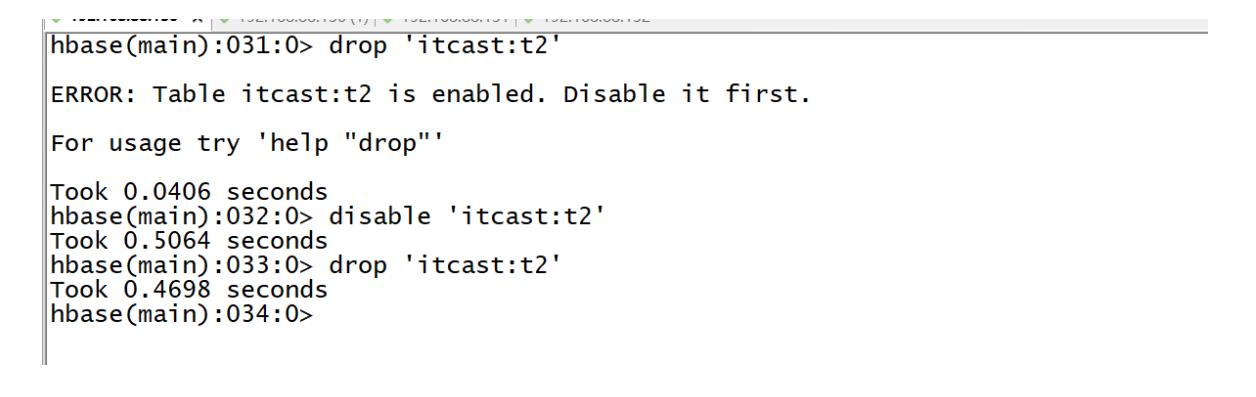
命令:drop
- SQL:drop table tbname
-
语法
drop '表名' -
示例
drop 't1' -
注意:如果要对表进行删除,必须先禁用表,再删除表
-
-
禁用/启用
-
命令:disable / enable
-
功能
- Hbase为了避免修改或者删除表,影响这张表正在对外提供读写服务
- 规则:修改或者删除表时,必须先禁用表,表示这张表暂时不能对外提供服务
- 如果是删除:禁用以后删除
- 如果是修改:先禁用,然后修改,修改完成以后启用
-
语法
disable '表名' enable '表名' -
示例
disable 't1' enable 't1'
-
-
判断存在
-
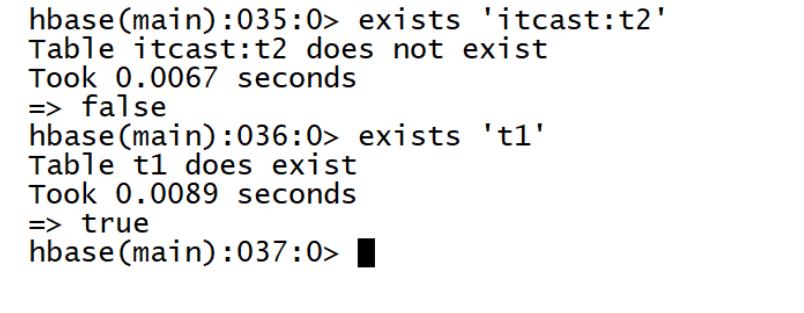
命令:exists
-
语法
exists '表名' -
示例
exists 't1'
-
-
小结
- 掌握Hbase中的常用DDL表管理命令
知识点14:HBASE命令行:Put
-
目标:掌握Hbase插入更新的数据命令put的使用
-
实施
Group name: dml Commands: append, count, delete, deleteall, get, get_counter, get_splits, incr, put, scan, truncate, truncate_preserve-
功能:插入 / 更新数据【某一行的某一列】
-
语法
put NS名称:表的名称,'Rowkey','列族:列','值' put 'ns1:t1', 'r1', 'cf:c1', 'value' -
示例
create 'itcast:t2','cf1',{NAME=>'cf3',VERSIONS => 3}put 'itcast:t2','20210201_001','cf1:name','laoda' put 'itcast:t2','20210201_001','cf1:age',18 put 'itcast:t2','20210201_001','cf3:phone','110' put 'itcast:t2','20210201_001','cf3:addr','shanghai' put 'itcast:t2','20210101_000','cf1:name','laoer' put 'itcast:t2','20210101_000','cf3:addr','bejing' -
注意
-
put:如果不存在,就插入,如果存在就更新
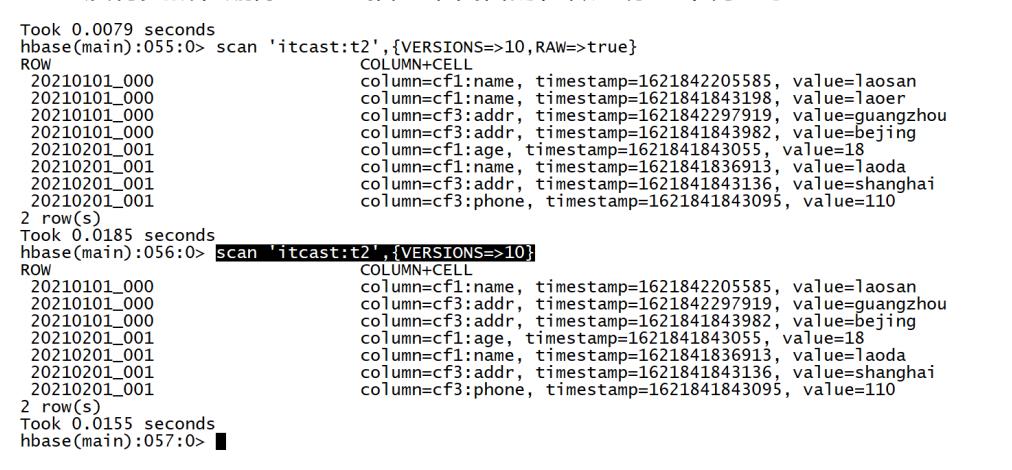
put 'itcast:t2','20210101_000','cf1:name','laosan' put 'itcast:t2','20210101_000','cf3:addr','guangzhou' scan 'itcast:t2',{VERSIONS=>10}
-
-
观察结果
-
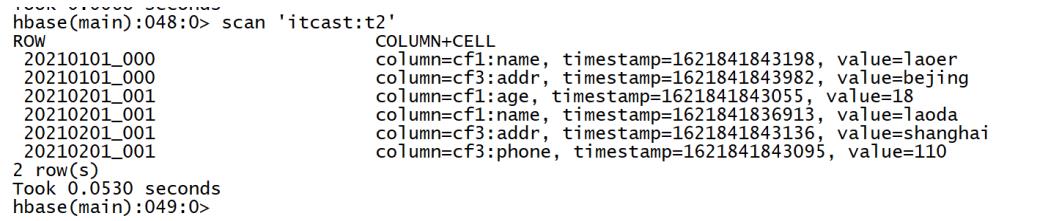
- Hbase表会自动按照Rowkey构建字典有序:逐位比较
- 没有更新和删除:通过插入来代替的,做了标记不再显示
-
小结
-
put的功能及语法是什么?
-
功能:插入和更新
-
语法
put 'nsname:tbname','rowkey','cf:col','value'
-
-
知识点15:HBASE命令行:Get
-
目标:掌握Hbase查询的数据命令get的使用
-
实施
-
功能:读取某个Rowkey的数据
- 缺点:get命令最多只能返回一个rowkey的数据,根据Rowkey进行检索数据
- 优点:Get是Hbase中查询数据最快的方式,并不是最常用的方式
- Rowkey作为唯一索引
-
语法
get 表名 rowkey [列族,列] get 'ns:tbname','rowkey' get 'ns:tbname','rowkey',[cf] get 'ns:tbname','rowkey',[cf] | [cf:col] -
示例
get 'ORDER_INFO','f8f3ca6f-2f5c-44fd-9755-1792de183845' get 'ORDER_INFO','f8f3ca6f-2f5c-44fd-9755-1792de183845','C1' get 'ORDER_INFO','f8f3ca6f-2f5c-44fd-9755-1792de183845','C1:USER_ID'
-
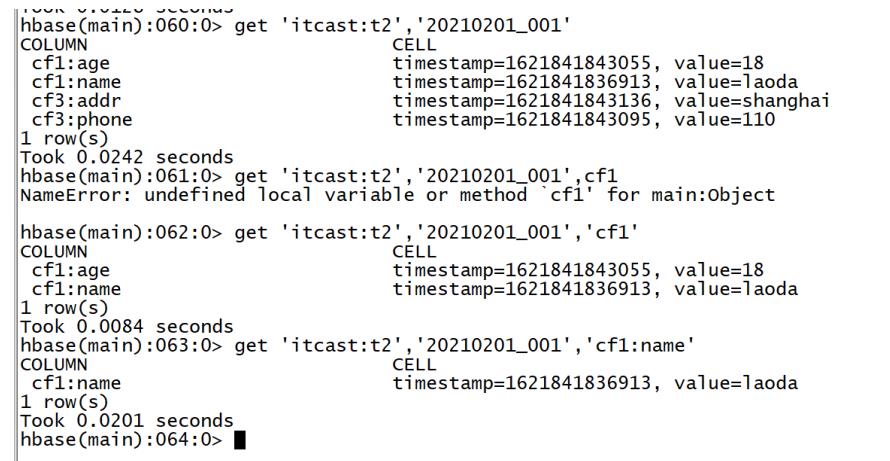
-
小结
-
get的功能及语法是什么?
-
功能:读取数据
-
特点:根据rowkey进行读取,走索引查询,最多返回一个Rowkey对应的数据
-
语法
get 'nsname:tbname','rowkey',[cf:col]
-
-
知识点16:HBASE命令行:Delete
-
目标:掌握Hbase的删除数据命令delete的使用
-
实施
-
功能:删除Hbase中的数据
-
语法
#删除某列的数据 delete tbname,rowkey,cf:col #删除某个rowkey数据 deleteall tbname,rowkey #清空所有数据 truncate tbname -
示例
delete 'itcast:t2','20210101_000','cf3:addr' deleteall 'itcast:t2','20210101_000' truncate 'itcast:t2'
-
-
小结
-
Hbase中的数据如何删除?
-
delete:删除某一列的数据
delete ‘ns:tbname’,'rowkey','cf:col' -
deleteall:删除某个rowkey的所有数据
deleteall ‘ns:tbname’,'rowkey' -
truncate:清空整张表
truncate 'ns:tbname'
-
-
知识点17:HBASE命令行:Scan
-
目标:掌握Hbase的查询数据命令scan的使用
-
实施
-
功能:根据条件匹配读取多个Rowkey的数据
-
语法
#读取整张表的所有数据 scan 'tbname'//一般不用 #根据条件查询:工作中主要使用的场景 scan 'tbname',{Filter} //用到最多 -
示例
hbase> scan 't1', {ROWPREFIXFILTER => 'row2', FILTER => " (QualifierFilter (>=, 'binary:xyz')) AND (TimestampsFilter ( 123, 456))"} hbase> scan 't1', {FILTER => org.apache.hadoop.hbase.filter.ColumnPaginationFilter.new(1, 0)}scan 'itcast:t2' #rowkey前缀过滤器 scan 'itcast:t2', {ROWPREFIXFILTER => '2021'} scan 'itcast:t2', {ROWPREFIXFILTER => '202101'} #rowkey范围过滤器 #STARTROW:从某个rowkey开始,包含,闭区间 #STOPROW:到某个rowkey结束,不包含,开区间 scan 'itcast:t2',{STARTROW=>'20210101_000'} scan 'itcast:t2',{STARTROW=>'20210201_001'} scan 'itcast:t2',{STARTROW=>'20210101_000',STOPROW=>'20210201_001'} scan 'itcast:t2',{STARTROW=>'20210201_001',STOPROW=>'20210301_007'}
-
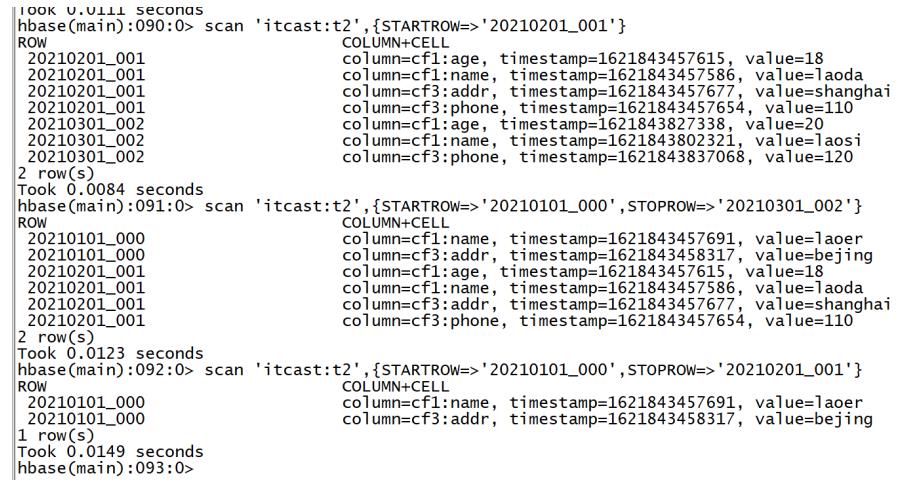
- 注意
- 在Hbase数据检索,尽量走索引查询:按照Rowkey条件查询
- 尽量避免走全表扫描
- Hbase所有Rowkey的查询都是==前缀匹配==
```
Rowkey的是什么至关重要:
如果rowkey的前缀是时间,20210201_001
如果我要查询:2021年2月到2021年9月所有的数据
scan 'itcast:t2',{startrow => 202102 ,stoprow = 202110}
走索引查询
如果rowkey的前缀是用户id,001_20210201
如果我要查询:2021年2月到2021年9月所有的数据
scan 'itcast:t2',{columnValuePrefix(time >= 202102 and time <= 202109)}
不走索引
```
-
小结
-
scan的功能及语法是什么?
-
功能:查询数据
-
特点:scan可以基于数据条件进行查询
-
用法
scan 'ns:tbname' scan 'ns:tbname' + Filter:最常用的用法
-
-
知识点18:HBASE命令行:incr & count
-
目标:了解Hbase的incr和count命令的使用
-
实施
-
incr:自动计数命令
-
功能:一般用于自动计数的,不用记住上一次的值,直接做自增
-
需求:一般用于做数据的计数
-
与Put区别
-
put:需要记住上一次的值是什么
put 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT',12 put 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT',13 put 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT',14 -
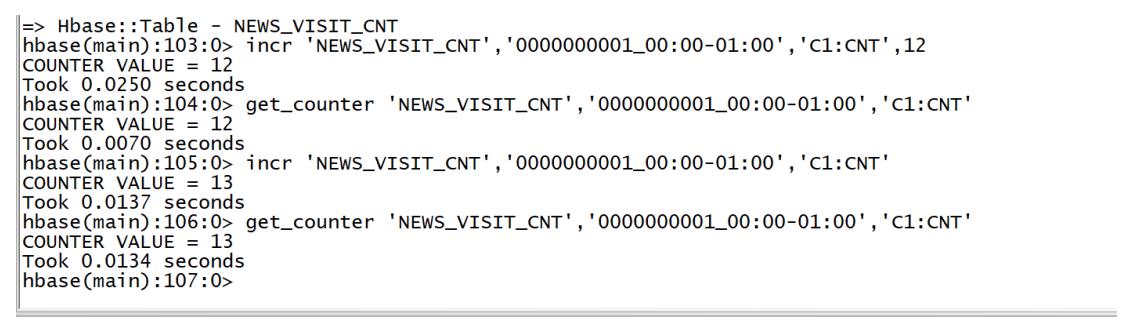
incr:不需要知道上一次的值是什么,自动计数
incr 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT',12 incr 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT' incr 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT'
-
-
-
语法
incr '表名','rowkey','列族:列' get_counter '表名','rowkey','列族:列' -
示例
create 'NEWS_VISIT_CNT', 'C1' incr 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT',12 get_counter 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT' incr 'NEWS_VISIT_CNT','0000000001_00:00-01:00','C1:CNT'
-
-
-
count:统计命令
-
功能:统计某张表的行数【rowkey的个数】
-
语法
count '表名' -
示例
count 'ORDER_INFO' -
面试题:Hbase中如何统计一张表的行数最快?
-
方案一:分布式计算程序,读取Hbase数据,统计rowkey的个数
#在第三台机器启动 start-yarn.sh #在第一台机器运行 hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'ORDER_INFO'-
方案二:count命令,相对比较常用,速度中等
count 'ORDER_INFO' -
方案三:协处理器,最快的方式
- 类似于Hive中的UDF,自己开发一个协处理器,监听表,表中多一条数据,就加1
- 直接读取这个值就可以得到行数了
-
-
-
-
小结
-
了解Hbase的incr和count命令的使用
知识点19:Java API:构建连接
-
目标:实现Hbase Java API的开发构建连接
-
实施
//todo:1-构建连接对象 //构建配置对象,用于管理当前程序的所有配置:用于加载hbase-default和hbase-site文件 Configuration conf = HBaseConfiguration.create(); //在配置中指定服务端地址:Hbase服务端地址:Zookeeper地址 conf.set("hbase.zookeeper.quorum","node1:2181,node2:2181,node3:2181"); //构建连接对象 Connection conn = ConnectionFactory.createConnection(conf); -
小结
- 用到了哪些类和方法?
知识点20:Java API:DDL
-
目标:实现Hbase Java API的开发NS的管理
-
实施
-
构建管理员
以上是关于Day26:分布式NoSQL列存储数据库HBASE的主要内容,如果未能解决你的问题,请参考以下文章
-