数字如潮人如水
Posted Debroon
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数字如潮人如水相关的知识,希望对你有一定的参考价值。
社会学简介
天文学的研究对象是天体和天体运行的规律。
物理学,研究物质世界的构成和物质世界的运行规律。
心理学稍微复杂一点,心理学研究人们的情感认知、内心活动的过程。
人的活动背后含有TA的意图,而且同样的举动可以有不同的含义,所以说,研究人是非常复杂的一门学问。
而天底下有木有比研究人更具有挑战的学科呢?
有啊,这就是我们的社会学,社会学是对人建模,在我们研究的某个局面中、在我们研究的某个具体的事情上,人一定是某个样的,是局面决定了人。
-
社会学研究内容:研究一群人所构成的社会,研究一群人的互动,他们所形成的规则、制度、文化。
-
社会学研究对象:研究构成社会的个体、群体、组织互动模式,以及推动社会运行的条件和机制。
此外,社会学对方法特别强调。
我们得学会一整套的定性研究的方法,和一整套定量研究的方法。
-
定量:数字量化,如 人的体重、男女生的人数 等
-
定性:像性别、观点之类的无法用数字来表示的
定性的方法包括现场调查、调研等等,定量的方法我们得学大数据分析、社会网络分析、计算机模拟等等。
定量研究
定量研究是社会学最重要的研究方法。
数据思维:用数据思考,让世界讲得通
我们一方面要尽可能获取多样性数据,另一方面,数据不是目的,所有数据都要服从某种算法。在你没搞清楚算法之前,你获取的太多数据很可能就把你搅晕了。
工具和方法既是利器,也能成为我们的枷锁;它在消除我们盲点的同时也在悄悄制造盲点甚至是盲维。
数据是客观的,对数据的看法是主观的,和对话、沟通一样,它们都极易出现大逆转——本来是抱着消除误解、化解冲突的沟通和对话,最后出乎意料地演变为关系破裂、甚至大打出手的局面。原因很简单,对话和沟通出现了致命的盲维。
我们在警匪片里常常看到这样的场面,两大黑帮出现了利益冲突,双方都同意坐下来谈判,但谈着谈着火药味越来越浓,最后是双方都把枪指向彼此。这个时候,往往会出现一个有威望的和事佬站出来,说一句:“大家发财,大家发财!”
听到句话,双方如梦初醒,突然明白,大家坐在一起不是为了逞口舌之利,不是为了打个你死我活。这个和事佬的功能,就是提醒、彰显大家在激烈的单维争执中被无视、被遗忘了的那个维度。
所以说,数据思维比工具和方法重要。
…
虽然定量是一种可信赖的方法,但数据也不是万能。
越是高学历的人、越是专业人士,越有可能对不符合自己愿望对证据视而不见,越善于把反方向对证据往正对方向解释。
如果你陷入愿望思维,再给你多少数据也没用。你的愿望,你的情感,是你的弱点。所以如果你想要用统计学了解真相,就必须先克制自己的情感。
所谓愿望思维,就是把自己的愿望等同于事实。因为我希望 X 是对的,所以我相信 X 是对的。
愿望总会调动人的美好情感,你一想象这件事就会获得一种愉悦感,你越想就越觉得它是真的。以至于你根本想不到、也不愿意跳出来。
所以作为一个主观的人,一定得倾听自己的情绪,不要因为不喜欢一个数字就忽略这个数字,也不要因为喜欢一条证据就强化这条证据。
一、感知数据
让您提高数据感,学会感知数据背后的意义。
1.1 培养数据感:定性思考到定量思考
思维一:量转型。
-
定义:你要把过去用定性的方式思考、谈论和使用一个东西的习惯,有意识地转变为用定量的方式思考、谈论和使用。
举个例子,看见一个小姐姐远远地走来,你就不要说,“小姐姐好漂亮”,而要说“小姐姐颜值好高”。
为什么呢?用“漂亮”这个词,就是在用定性的方式思考;而用“颜值”,就是用数量的方式思考。漂亮,只有漂亮和不漂亮两种可能;而颜值,空间就大了,可以是10分制,也可以用百分制。这就是“量转型”。
给女生的容貌打分有这么大的意义吗?真的很有,你知道Facebook的故事吗?
Facebook现在是世界上最重要、规模最大的社交软件,但它起步的时候,就是创始人扎克伯格他们几个男同学想给女同学的颜值打分。
没有这一步,就没有现在Facebook的成就。
其实,日常生活里的任何东西,只要你想,就都可以量转型。
比如,你买一盏台灯,就不要买只有一个开关的,而是买那种亮度可以调节的。这样,就从“照亮”这个概念转型成了“亮度”这个定量的概念。
思维二:量定义。
-
定义:我们要用量来定义质,从量的方面抓住事物的本质。我们一定可以找到一个关键量,这个量抓住了事物的本质,使这个事物得以与其他事物区别开来。
举个例子,你听见老耿说,“我买了一台标准钢琴”,那你就会反应出,老耿买的钢琴有88个琴键。只有有88个琴键的钢琴才叫标准钢琴。量定义就是这个意思。
有些概念在观念世界里很清楚,但是要在现实世界里抓住它、看到它,就需要一个重要的方法,用量来定义这个概念。在现实世界,我们就是用测量的方式,逼进一个观念世界里的概念的。
比如,我们用生理上的60岁代表老了,那社会老龄化(社会老了)是怎么定义的呢?
这就需要一个像生理年龄一样的标准去测量它。因此,我们就把老年人口占全体人口的比例看成是测量一个社会“生理上”老化程度的指标。
定义一个老年人的标准是60岁以上,那么老年人口就是所有60岁及以上的群体。这样一来,通过老年人口占全体人口的比例,我们就能测量一个社会的老化程度了。
思维三:对应值
-
定义:在量定义的基础上,为事情确定一个明确的对应值。对应值反映的是你对事物性质和原因的理解,理解不同,选择的值就可能不一样。但从数据思维的角度来说,你必须确定一个对应值,才能定义清楚你对事物的理解。
接着社会的老龄化问题。量定义清楚了,使用老年人口占全体人口的比例来测量。那么,这个比例要达到多少才是一个老龄社会呢?
这里,对应值就出场了。根据人口学家的共识,老年人口,也就是60岁以上的人口所占的比例超过10%,就是老龄社会。这个10%就是对应值。
老龄社会的对应值比较有共识,但是还有很多情况,对应值并没有共识,需要你来研究确定。
有了对应值这个概念,我们就开辟了一个思考问题的新角度。
举个例子,什么是微笑呢?你就不一定非从心理上定义,而是可以找到一个量来定义它。比如,露出三分之一的牙,在观察者看来就是微笑。
这个方式就是银行、证监会、支付宝和微信支付等金融机构监控异常情况的逻辑。
以金融信贷审批模型 - 个人信用评估来总结定性思考到定量思考的思维变化过程:
- 第一,量转型,用“定性”的方式思考转变为用“定量”的方式思考,针对某人信用的评价,从信用好与不好,转变为信用分的高低。
- 第二,量定义,信用分的高低反应的是一个人的金融履约的概率大小,信用分越高表示这个人按时还款的概率越高。
- 第三,对应值,信用分的阈值区间是350-750分,多少算高、多少算低呢,例如对于免押金应用,经过模型测算,认为550分以上属于该类应用的高信用分群体,可以赋予免押金租赁的资格。
从数量的维度理解现实世界(量转型、量定义、对应值),任何定量分析方法(数据分析、机器学习)都是这个思路展开的。
1.2 意义取决背景:输入看定义,输出看情境
学概率统计拼的不是数学,而是语文能力。
单纯的概率计算,其实是非常简单的。为什么这么说呢?举个简单的例子您就明白了:
-
老王家先后有两个孩子,已知老大是女孩,问另一个是男孩的概率是多少?
这很简单,老大的性别已经确定了,所以老二要么是男孩,要么是女孩,概率就是1/2嘛。但是,只要改变条件里的一个词,把“老大是女孩”变成“其中一个是女孩”,就改了一个词哦,这时候概率就变了。
两个孩子,其中一个是女孩,就有“女孩男孩、男孩女孩、女孩女孩”三种情况,有男孩的情况有两种,所以另一个是男孩的概率马上就变大了,从1/2变成了2/3。是不是很神奇?
我举这个例子,其实就是想告诉您,好多概率统计题拼的都是语文能力,看您能不能正确找到条件、理解题意。很多人不会做概率统计题,都不是因为不会计算,而是因为没有审好题,没有正确理解题意。真正打败他们的不是数学,而是语文。
方向一:理解事情的属性
-
定义:理解事情的属性,也就是“是什么”这类问题,或者说是分类问题、定性问题。一件事情,是健康的,还是病态的;是合法的,还是非法的;是雄性的,还是雌性的等。这类问题都指向一个确定的基准,比如一个临界点、一个里程碑、一个正常范围、一个关键门槛等。
近些年来,英国伦敦以外地区的出生婴儿死亡率,明显比伦敦市要高。这引起了人们的警觉,是不是伦敦以外地区的医疗水平不行了呢?结果不是。
这个事儿的关键在于,到底什么叫“婴儿死亡”。孩子从怀孕到出生大概需要 40 周,如果是 37 周之前出生就是早产,但早产婴儿也是婴儿。伦敦市的标准是 24 周就算是一个生命了,只要是 24 周之后死亡,就算作婴儿死亡;不到 24 周的死亡才叫做流产。
那你说这个 24 周的规定有啥道理呢?难道 23 周的胎儿就不是生命吗?他其实已经长成型会动了啊。英国在伦敦以外的医院,就把“婴儿死亡”的定义,划线到了 22 周。正是因为这个定义的差别,导致了两个地区的婴儿死亡率不同。
这个差距挺明显的。2010 年,美国的婴儿死亡率是千分之 6.1,芬兰是 2.3,人们因此纷纷指责美国,但是这里面也有定义不同的因素。美国医院普遍对婴儿的定义是 22 周。如果我们只看 24 周以后的婴儿死亡率,那么美国其实是 4.2,芬兰是 2.1,仍然有差距,但是差距没有那么大。
数什么,决定了数数的结果。你说现在贫富差距变大,那到底什么叫富人,什么叫穷人?我们应该算总财产呢,还是算年收入?这两个统计结果的差别是巨大的。
有些问题的基准相对容易找,比如体脂率这样的科学问题,已经研究得很深入了。而有些问题没有现成的基准,就需要你创制一个,只要你的理由可以让大家接受就行。当然,也有些前人的经验可以借鉴。
方向二:理解事情的相对情况
-
定义:一件事情是快是慢、是轻是重、是大是小、是远是近,都是相对的。所以,理解这类问题,就要找参照系、找对比值。
即便定义清楚,一个数字到底是大是小,我们还得看具体的情境才知道。
那个新闻为什么说「伦敦的谋杀率第一次超过了纽约」呢?其实就一组数字:2018 年 2 月,纽约有 14 起谋杀案,而伦敦有 15 起,这是历史上第一次伦敦的谋杀案多于纽约。
那这对伦敦来说是多大的坏事呢?没有具体情境的数字就如同没有测量单位一样。首先你得知道伦敦和纽约各自的人口数量,但是因为两个城市的人口差不多,直接比较数字是可以的。
而后你得考虑时间情境。是不是伦敦治安变差了呢?并不是。我们对比 1990 年全年,伦敦有 184 起谋杀案,纽约有 2262 起 —— 所以不是伦敦变差了,而是纽约变好了。更合理的说法是伦敦的治安一直都很好。
数字的情境包括时间尺度、空间尺度、总人口、GDP、财富总量等等。对这些常用的数字有个基本感觉,你就容易评估新闻里那些数字了。
方向三:理解当事人的意图
-
定义: 数据背后的意义是什么?
某天迪士尼乐园的后台,发现墙上有大大的海报,写着好几个顾客满意度。作者注意到,所有的满意率都在75%到80%之间。很诧异。因为每一个人肯定都有感觉,很少有人对迪士尼乐园不满意,怎么满意率这么低呢?
我们得看看这个满意度调查是怎么做的。顾客是在“很满意、比较满意、满意、比较不满意和很不满意”这5种选项中选择,而迪士尼只计算很满意的那部分。
如果三种满意都计算,数字会特别好看,都是99%以上,这会让员工觉得没有提升空间,没有什么可以做得更好。为什么要只计算很满意呢?因为我们发现,选择很满意的顾客的忠诚度是选择比较满意的顾客的6倍。
重点来了,你以为迪士尼调查的是顾客满意度,其实人家调查的顾客忠诚度,也就是来了一次之后还会再回来玩儿的那些人,而不是来了一次下次就不来了的那些人。
1.3 让数据说话:如何发现已知数据背后隐藏的信息
发现已知数据背后隐藏的信息,类似福尔摩斯的推理,从华生身上的特征推论他去过阿富汗。
方法一:数学推断
-
定义:利用数学知识作出假设,而后进行推断。
媒体报告,离婚对数与结婚对数的比值这个指标今年又上升了,那情况是否也是如此呢?
这时候,你就可以反过来把媒体的思路拆解,先看看它的假设是什么,而后再判断这个消息靠不靠谱。
从离婚率的定义上看,是离婚对数与结婚对数的比值越来越大,但是,有三种可能会导致这个变化:一种是主要原因在分子,也就是离婚的越来越多;另一种是主要原因在分母,也就是结婚的越来越少;第三种是相对情况,比如分子分母同步变化,但是分子的变化幅度更大。
所以,要真正读懂离婚率,我们要找到主要因素。
-
先看分子——当年的离婚对数。但是,谁能离婚呢?必须要先结婚才能离婚吧?所以这么些年下来,已婚的人数会逐渐累积增多。已婚人数多了,离婚的自然也就会多,即使离婚率没有变化,离婚对数也会增长。所以,分子逐渐变大是正常的,关键在于变大的速度是不是加快了。
-
再看分母——当年的结婚对数。这个数字与进入婚龄的人口数量相关,也就是受到20年前新生人口数的影响。20年前新生人口数越多,现在结婚的自然就越多。
查阅近20年的数据,我们看到的是:离婚对数在20年内慢慢上升,坡度很缓。而结婚对数的曲线是一个大鼓包,20年间,前14年在快速上升,在2013年达到高峰,随后快速下降,到2019年回到了2001年的规模。
这样看来,近年来的离婚对数与结婚对数比值的上升,不是离婚多了,而是结婚少了。如果今年这个数据上升,隐含的信息不是婚姻幸福的人越来越少了,越来越多的新婚夫妇都离婚了,而是结婚人数在不断下降。
-
方法二:逻辑推理
-
定义:从各个领域的规则和限制条件出发,进行合理化猜测。
比如斗地主,这是一种扑克游戏,三个人打一副牌,分成两边对战。如果你手里有4个5,没有4,现在上家出了2个4,那么,牌面上的2个4还隐藏了什么信息呢?答案是,下家还有2个4。
推理过程是这样的:
- 首先,上家不可能有4个4。因为4个4是一个炸弹,价值很高,他不会傻到不要炸弹而把4个4拆开。
- 其次,上家会不会有3个4呢?如果他有3个4,还要只出2个4,必定是手里有顺子,比如45678之类的。但是,你手里有4个5,所以上家不可能有顺子。结论,另外2个4在下家。
这里没有复杂的数学,但要充分理解游戏规则,把这些规则作为限制条件来进行推理。
方法三:切换视角
-
定义:在不同的视角、关系下观察数据,数据就会发出不同的隐含信息。
看见你看不见的,这很重要。
从选择的维度来看问题。
比如说征兵制,国家发布一纸命令,说所有的年轻人都有当兵的义务,既然是义务给你多少钱都可以,这样不就可以省下一大笔国防开支了吗?省下来的国防开支是看得见的,看不见的是每一个人的机会成本;多了一个便宜的兵是看得见的,但丢了的那些劳动服务,社会上少了的物理学家、化学家、小提琴家是看不见的损失。我们要把他们纳入到我们的考虑当中。
比如说水资源保护法,到底是不是节省资源的问题。看得见的是通过水资源保护法保护下来的水,看不见的是由此而产生的其他资源的浪费。你要节省水可能就得浪费电,可能得浪费木材,可能得浪费时间,甚至得浪费健康。我们把各种各样的选项都摆在桌面上,这时候就比较容易看出我们到底丢失了什么。
从时间的维度看见看不见的。
上个世纪 90 年代的时候,美国汽车经销商当时在大力推销一款价值1万美金的车,但是当时美国的汽车市场已经特别的饱和了,所以市场的销售情况一点儿也不好。有的车行就不惜血本打折,打折到15%销售,但是效果也不是特别理想。
这个时候,有一个经销商他就想出了一个“免费送车”的主意,怎么说呢?就是买一辆车,送一张面值1万美金的30年期的美国国债。1万美金的车,送价值1万美金的债券,这听上去像什么?免费拿了一辆车。这个诱惑实在是太大了。所以很多根本就不打算买车的人这时候就开始争先恐后地往车行跑,生怕去晚了,这个天上掉的馅饼砸不到自己,所以车行的生意一下子变得特别的火爆。
但是,聪明的您估计已经注意到了,这个赠品不是1万美金的现金,而是“面值1万美金的30年期的折价国债”,换句话说,你拿到的“1万美金”是30年后付给你的1万美金。
按照90年代中期平均8%左右的国债利率算,折算到30年后,这个面值1万美金的债券只剩下994美金。也就是说,销售商其实只给了你994美金的礼物,让利幅度只有9.94%,比那个15%的打折力度差远了。
从…看见看不见的,了解到不同视角中有着不同的真相,不是要让我们和他人划清界限,而是邀请我们向其他更多的视角开放、倾听、理解和学习。
1.4 工程直觉:数据的估算方法
如果您去过大公司面试,可能发现,除了专业技能,大公司更在意候选人有没有能力胜任未来的工作,更看重候选人解决问题的思路等等。
如果您去大公司面试,遇到的可能是这样的题:
- 芝加哥有多少个钢琴调音师?
- 西雅图有多少个加油站?
- 北京有多少家星巴克?
- 当前所处的房间里能装下多少个高尔夫球?
… …
面试官不是要面试者估算得多精准,而是想测试你,面对什么线索都没有的问题时,你有没有解决问题的思路和办法。
如果靠直觉瞎猜,在数量级上会相差十万八千里,而遵循一套工程思路解决问题的人,对这个问题估计出来的大致数量级不大会错。
在工程里,量化方法就隐藏在量化目标中。
确定真正要量化什么,是几乎所有科学研究的起点。
量化思维的重点,不是计算,也不追求精确的数据,而是把握重点,要选择出需要量化的指标。
量化的方式能让不确定的问题,逐步清晰起来。使用量化思维,即使没有精确的数据,我们也能解决一些生活中,那些看似解决不了的问题。
量化思维的关键是,我们要意识到什么事情是应该量化的。这往往就是解决问题的突破点,掌握了量化思维的关键点,你其实就掌握了一种解决问题的能力。
问:芝加哥有多少个钢琴调音师?
我们先把这个问题分解成几个小问题:
- 第一是,芝加哥有多少架钢琴?
- 第二是,钢琴每年要调几次音?
- 第三是,调一次得多长时间?
- 第四是,调音师平均每年工作多长时间?
第一个,芝加哥有多少架钢琴?
- 不知道,但是芝加哥的人口大概有250万,钢琴还蛮贵的,大概一百个人里,有两个人会有一架钢琴吧,这么一算,芝加哥大约有5万架钢琴。
第二个,钢琴每年要调几次音?
- 估计是一年一次。
第三个,调一次得多久?
- 大概两小时吧。
第四个,调音师每年工作多长时间呢?
- 按每天8小时的标准算,一年工作2000个小时,但调音师是上门服务的,要减去路上的时间。路上大概得花400个小时吧,调音师每年大概工作1600个小时。
答,我们有了以下这几条假设:
- 大约有250万人生活在芝加哥
- 每100个人中,约拥有2台钢琴
- 钢琴每年需要调整一次
- 每个调音师大约需要2小时来调一台琴
- 每个调音师每天上班8小时,包括路上时间一年需要2000个小时,所以一年总共调音1600小时
上面这些数字,全都是粗略的,都不精准。
我们就用这些数字简单算一下,5万架钢琴每年需要调一次音,每次两小时,一共就是10万小时,调音师每年工作1600小时。10万除以1600,得数是62.5,再四舍五入,估算出芝加哥大概有63位调音师。
那么,事实上芝加哥到底有多少钢琴调音师呢?
大约83名,有些人名还是重复的,可以说与估算的数值非常接近了。
大公司面临的问题很多都是新问题,对于这些从来没见过的问题的解决方案,大部分人根本就不能事先就完整规划出来,于是问题在不同的人手里就有了不同的结果:
靠直觉、经验的人,会觉得这件事情根本不可能完成,这个问题肯定就解决不了。
有工程直觉的人,解决方案不是事先就完整规划出来的,而是自下而上一步步在过程当中找到的。
所以,生活中有模糊不清的地方,就量化吧,一开始肯定不精确,但这肯定比凭着感觉猜测要好。
1.5 懂数据:数据是什么
数据是什么,我们需要从三个层面来梳理。
第一:数据是对现实世界的映射。
-
定义:从数据和实体的关系来看,数据是对现实世界实体的映射。
比如你照镜子,镜子里出现了你美丽的脸庞,镜子中的脸跟你的脸是一种一一对应的关系。这就叫“映射”。
不过,镜子中的脸仅仅是光的虚像,既不是实体,也不是数据。但如果用手机拍照,那就不一样了。手机中的摄影系统会记录你的长相,并且转换成数字,最终变成一份文件。这份文件中的数据与你的脸是一一对应的。数据的来源就是这样的。
比如,人脸识别。有两张照片是同一个人的:

对于这个问题,人是很容易分辨出来的,但计算机应该怎么办呢?其中一种方法就是将之线性化。首先,给出此人更多的照片:

将其中某张照片分为眼、鼻、嘴三个部位,这是人脸最重要的三个部位。通过某种算法,可以用三个实数来分别表示这三个部位,比如下图得到的分别是 150 150 150、 30 30 30、 20 20 20:

将所有这些照片分别算出来,用三维坐标来表示得到的结果,比如上图得到的结果就是 ( 150 , 30 , 20 ) ( 150 , 30 , 20 ) (150,30,20)。
将这些三维坐标用点标注在直角坐标系中,发现这些点都落在某平面上,或该平面的附近。因此,可认为此人的脸线性化为了该平面。
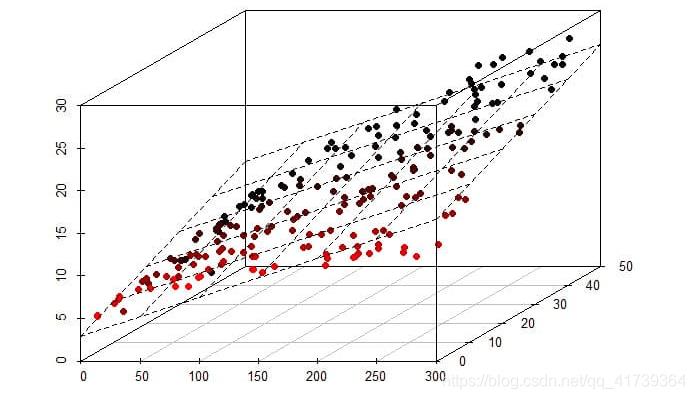
将人脸线性化为平面后,再给出一张新的照片,按照刚才的方法算出这张照片的三维坐标,发现不在平面上或者平面附近,就可以判断不是此人的照片:
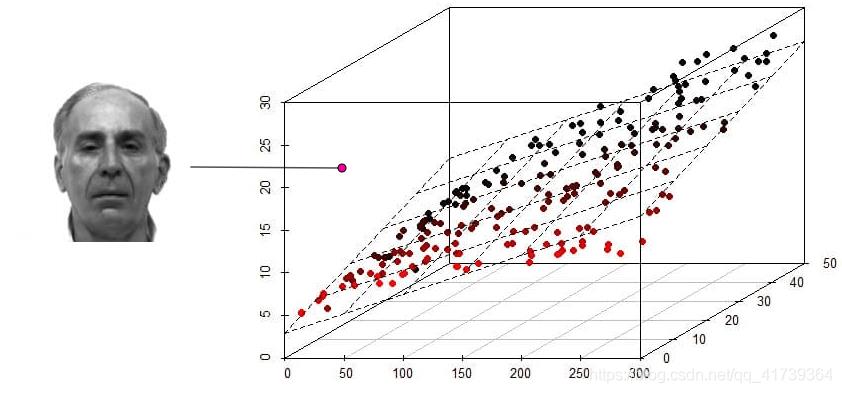
第二:我们需要元数据来说明数据。 -
定义:元数据是对某个对象作出的描述。
以前有个叫斯诺登的前美国中情局工作人员,爆料说美国有一个“棱镜计划”在收集所有的通话内容。这还了得!
这让高度关注个人隐私的美国人大惊失色,异常愤怒。结果查下来,发现美国情报部门并没有收集通话的内容,收集的只是通话的元数据,就是说明通话在何时、何地、通了多少时间那些记录。
通话内容是数据(表达什么),通话记录是元数据(谁和谁通话、何时、何地、通了多少时间)。
就像朋友圈的视频,那个视频往往有文字说明,介绍视频里面的元数据(非视频内容),这很重要。
比如,如果你是一个公众人物,那我就在公开媒体上记录你的行踪。一旦我收集到了你去过的4个地方和4个时间,我就能知道你的手机号码(政府人员可以动用各种数据库)。知道了你的手机号码,在网上跟你手机号码绑定的所有信息就都知道了。你说元数据厉害不厉害?
第三:要把数据、数据容器、数据蕴含的信息分开
选书、买书、读书,这是多简单的事儿啊!事实并非如此。很多人的关注焦点常常在封面设计上,在书名上,还有的人关注焦点在腰封上,看“哪些牛人推荐了这本书”…… 甚至有些人的关注焦点在书的价格与页数的比例上,估计你听过这样的评论:“这么薄的书,咋卖这么贵?!” —— 他们买的不是知识,而是纸张而已。
两分钟讲清楚,让自己把关注焦点放到更有价值的信息上去:
- 看版次
- 看印数
- 看出版社
- 看参考文献列表
这些东西,常常在书的最后几页。多次再版、多次重印、每次印数更多的书籍,相对质量更有保障(虽然不是绝对)。
书,可是要读进脑袋里的东西啊!怎么可能稀里糊涂就选了,稀里糊涂就读了,稀里糊涂就信了呢?可惜,真的有很多人,竟然一直没有调整优化过自己的关注焦点,于是…… 那个惨状想想吧,我就不花笔墨描述下去了。
不过,这也不怪他们 — 我们经常把数据和数据容器混淆。
- 数据:文字背后的思想
- 数据容器:承载思想的纸张
- 元数据:版次、印数、出版社、作者、名人推荐、参考文献列表
二、收集数据
2.1 变量类型:人类在认识客观世界的过程就是采用了分类的方法
像一本小说是有各种分类:
- 小说按照篇幅及容量可分为长篇小说、中篇小说、短篇小说和微型小说(小小说)。
- 按照表现的内容可分为神话、仙侠、武侠、科幻、悬疑、古传、当代、玄幻小说等小说。
- 按照体制可分为章回体小说、日记体小说、书信体小说、自传体小说。
- 按照语言形式可分为文言小说和白话小说。
分门别类 是科学研究的基本方法和途径,人类在认识客观世界的过程就是采用了分类的方法。
世界分为 生物和非生物。
-
生物分为动物、植物、微生物等等。
-
或者是界、门、纲、目、科、属、种。
酒是有不同的类型的,什么葡萄酒、白酒、啤酒等。数据也是一样,它也有自己的类型。
别看现实世界的数据千差万别,但其实它们都可以归为四类,分别是类别数据、次序数据、间隔数据和比例数据。
类别数据:会给所有的东西分类的数据,如下图:
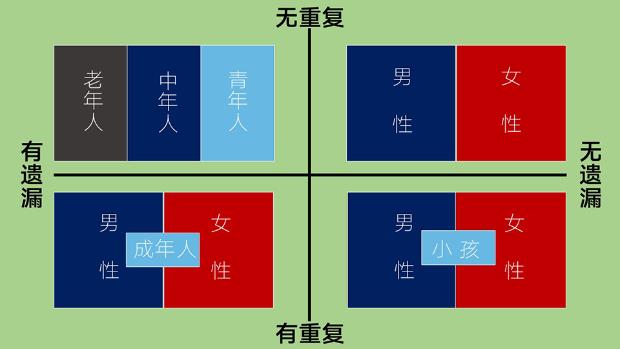
但是分类可不好弄,需要完全穷尽,相互独立,您得把所有的分类情况都包括在内,又没有逻辑上重复的地方。
我看新浪网经常会做各种在线投票调查,它给的那些选项,常常在逻辑上都不完备,更不用说还都有倾向性。我一看那个问卷都火冒三丈。
所有事物的分类方式都有两种,一种是并列结构的,比如头痛的生理性、心理性两种分法。还有一种是数理结构的,把问题拆解为数学公式,比如煎饼摊的月利润 = 每天卖出的煎饼数量 × 每套煎饼的价格 × 每月工作天数 - 煎饼运营一个月的总成本。
这两个一种是有等式关联的,是一个数学公式,另外一种是并列结构,没有等式关联的。
我们在做分类的时候,应该要尽量去寻找那种有数理结构的分类方式。也就是说能够公式化一切的方式。因为这是最能保证科学分类的最理想的方式。
次序数据:本质上,次序数据还是类别数据,但是多了一个大小顺序的信息。
这件事对你来说,是非常重要、重要、无所谓、不重要,还是非常不重要呢?这个问题测量出来的结果就是次序数据。
间隔数据:每一个间隔都是相等的,数字之间的距离是相等的。
最典型的间隔数据就是智商(IQ值)。
智商可以有90、100、110等,90和100之间、100和110之间,距离是相等的。
比例数据:如男女比例。
某生殖医学中心某年出生的试管婴儿的性别数据,在男性编码为1,女性编码为0的情况下,把这些数加起来除以总的试管婴儿出生数,假设结果是0.25,说明男女比例是 1:3。
2.2 变量测量:定量的测量一个事物的方法
测量的目标是什么?必须得到一组指标。
几个盲人被要求摸一头大象,告诉大家大象是什么。摸到大象牙齿的说,大象像大萝卜;摸到了耳朵的说,大象像大蒲扇;摸到腿的说像柱子;摸到尾巴的说像草绳。
我们要测量大象、描述大象这种动物,而不是测量大象的身高、体重这样单一的指标。
为了全面把握一个事物,测量时用维度拆分,维度尽量关联、完备。
2.3 变量描述:通过抽样对总体做定量描述
具体收集数据时,如果调查对象内部差异特别大,又不能全部测量,那就用抽样,用样本推断总体。
如果用2000人就能知道2亿人的情况,省事又省钱,还调查2亿人干嘛呢?这个就是抽样。
抽样,是从一大堆东西中挑选出一小部分样本,然后通过样本的情况对总体做定量描述。通俗地说,就是以小见大。
怎么才能做到一个好的抽样呢?
- 样本要对总体有代表性。
选择样本的原则:必须使用概率样本
- 定义:当样本的各种特征大体接近总体的特征的时候,样本就具有代表性。
1936年,美国《文学文摘》预测总统大选,编辑部发出了1000万张问卷,回收了240万份,而当时的选民总数才4000万。
因此,编辑部在发布预测结果的时候,还假惺惺地谦虚了一把,说“我们不能使用绝对无误这个词,我们十分清楚模拟选举的局限性”,意思就是,“也就跟你们客气客气,我们才不会错”。
结果呢?他们不但错了,连方向都是反的。
杂志社的样本绝大部分来自于家里有电话或者有汽车的家庭,而1936年的美国,刚走出经济大萧条。
这时候家里有电话、汽车的都是富人。所以,尽管样本量高达240万,但是穷人不在里面,而穷人的数量又比富人多多了,因此,这个样本就没法代表全国选民。
同样是在1936年,《文学文摘》倒下去,盖洛普调查公司站了起来,因为总统大选预测正确而一战成名。
盖洛普做对了什么呢?
它使用了配额样本,就是根据总体的情况分配样本数量。比如,总体中男女比例是7比3,那么如果样本总量是100人的话,男生就分配70人,女生分配30人。盖洛普凭借这个方法,连续预测成功。
不过,事不过三,1948年,盖洛普第四次预测总统大选时也被打脸了。
为什么呢?当时,盖洛普配额的依据是美国1940年的人口普查数据。但是,二战结束了,大量农村人口涌入城市,改变了人口结构,1940年的配额方案已经代表不了1948年的选民情况了。于是,和《文学文摘》一样,盖洛普也倒在了代表性这个坑里。
配额样本毕竟不是概率样本。
关于抽样,只有概率样本才能确保全面反映总体情况。为了保证代表性,必须使用概率样本。
概率样本的意思是说,每一个样本都要按照事先确定的概率规则选取。听起来,配额样本和概率样本有点像,但其实不一样。
比如,抽中一个男生宿舍,宿舍一共有6个学生,要调查其中1个学生。配额样本的做法是,找这个宿舍里任何1个学生都可以。而概率样本的做法是,随机地确定1个学生。怎么随机确定呢?先给这6个学生编号,123456,然后扔骰子。一扔,5号。那好,只能找5号学生。你说5号学生去图书馆了,不在。那不行,喊他回来,别的同学不能代替。
由于有数学上的保证,概率样本确保可以推断总体的情况。但配额样本好不好使,就要看运气了,有些条件下还可以,另一些条件下就不行。
选择样本量的原则:根据需求确定样本量
现在我们知道选择样本原则了,新问题又出现了——要选择多少样本呢?这个主要看你的需求。
比如,盖洛普预测美国总统大选是2000人,增加样本量,抽2万人,20万人,200万人,对预测总统大选来说,和2000人差不多,精度不会有大的提高。
因为样本量和误差水平之间不是线性关系,而是有两个阶段:
- 刚开始是随着样本量的增加,误差水平减少;
- 但超过一个范围后,样本量的增加就很少导致误差的减少了。
选美国总统,大部分情况是二选一,不是民主党就是共和党,这种情况对样本量的要求不大。
但是像辉瑞制药公司做的新冠疫苗三期临床试验,受试者高达4.3万人。就是因为疫苗涉及生命安全,对样本的代表性要求特别高,需要调查很多人才能体现真实的概率,因此就需要更大的样本量。
调查的原则:非概率样本应对复杂情况
现实是复杂的,概率样本固然靠谱,但很多情况下我们都做不了概率样本,这时,可以用非概率样本应对复杂情况。
比如,我们想了解同性恋人群的情况,可这是一个非常敏感的问题,很多人不会告诉你实情,怎么办呢?
可以试试滚雪球抽样。先找到一个同性恋者,再请这个同性恋者介绍其他的同性恋者,这样循环下去,就像滚雪球那样,越滚越大,最后可以得到足够多的样本量。
非概率抽样有很多形式,上面的是滚雪球抽样,此外还有方便抽样、定额抽样、立意抽样、空间抽样等。
解释调查结果的原则:抽样结果是个有限制的范围
选择了样本、确定好了样本量,调查也完成了,怎么解释调查的结果呢?
抽样调查的结果是一个有限制条件的范围,而不是一个单一的数值。
假如随机抽样2000名中国人,女性比例是49%,我们可以说中国人的性别比例是女性占49%吗?
不能,不能用样本的结果直接代表总体的特征。
真正的抽样调查的结论是这样一个句式:
- 在什么置信度水平下,总体的特征值在什么范围内”。
上面那个例子,结论的正确表述是,“在95%的置信度之下,中国人的女性比例在46.8%到51.2%之间。
置信度是表达你对结论的信心,95%的置信度就是100次可能有5次错误。这是一个行业通用标准,一般通用标准是P<0.05,也就是95%或95%以上的置信度。
一定不要把抽样结果直接用在总体上,真正的结果是一个带限制条件的范围。
2.4 P<0.05:科研界的灰色做法
所有心理学、医学和社会调查研究中,凡是涉及到统计方法的研究,从理论上来讲,哪怕科学家都是兢兢业业老老实实地工作,大约每20篇论文中,就有一篇的结果,其实是无效的。
而因为科研界很多灰色的做法(P<0.05),实际情况比1/20要坏很多,这个误差,是科学方法本身所决定的。
统计结论是怎么来的?
比如现在有人发明了一种新药,你怎么证明这个药是有疗效的呢?有个病人吃了这个药,他的病就好了,你能说这个药有疗效吗?不能。因为有些病不吃药也能好。
科学的做法,当然是做个随机实验。我找100个病人,随机分成两组,每组50人。给第一组病人吃新药,给第二组病人吃跟新药看上去一模一样的……糖豆,也就是“安慰剂”。
病人自己并不知道被分到了哪一组,我们甚至还可以让负责发药的医护人员也不知道每次发的是新药还是安慰剂,这样所有病人除了吃的药不一样,其他方面都是一样的,这就做成了一个“双盲”实验。
如果在一个疗程之后,第一组病人全都治好了,第二组病人全都死了,那我们就有充分的理由相信这个新药是有疗效的。
现代医学的本质,是为自我修复提供时间、创造条件。
即便是ICU这种运用了全世界最前沿、最高端救命设备的地方,几乎所有的救命手段都是支持。
-
呼吸机,是支持肺,让肺休息,等待自愈;
-
床旁血液净化,是支持肾,替代肾脏的功能,等待自愈;
-
全世界最前沿的ECMO,也就是老百姓说的“魔肺”,是对心脏和肺,最高级别的支持。
所有这些顶级的医疗设备,都是为了先把命保住,给自我修复赢得时间、创造条件,等待自我修复发挥作用。
可能你会说,有的病看上去确实是医生治好的,它怎么看都跟自我修复没啥关系。
比如肺炎,医生用抗生素杀死细菌,病人治愈。
听上去确实是抗生素起了作用。但是这个例子,同样体现了“医疗的本质是支持自我修复”这个基本共识。
为什么呢?
得了肺炎,先用抗生素杀死大部分细菌,但是总有耐药的,没被杀死的细菌。怎么办?
这个时候,人体的白细胞发挥作用,消灭剩下的细菌,让肺炎痊愈。
白细胞吞噬、杀灭细菌的过程,就是自我修复。
同样是肺炎,但是白血病病人或者艾滋病病人就没有这么幸运了,会非常难治,这些病人甚至会因为肺炎去世。
因为这类病人的白细胞吞噬功能差,自我修复能力低下,因此,再强大的抗生素效果也不好。
治愈疾病,最终靠的还是自我修复。
你想,这些病是怎么来的?
是人长期生活方式不健康,胡吃海塞不锻炼积累出来的,怎么可能通过一颗神药就药到病除呢?
治疗这些病,其实本质上是重构一个人的生活方式本身,这不是医生和药厂单方面的任务啊。
肥胖也是,这是由人现在的生活方式决定的,所以减肥的本质,是换一种人生。减肥成功的标志,是您换上了一种健康的生活方式。
所以说,哪有什么神药啊,即便是在市场上很火的药,有效率也没有那么高,经常都只是比不吃药稍好一点而已。
你的实验结果更可能是第一组有22个人的病好了,4个人死了,第二组只有15个人病好了,但是只死了3个。
这就让人很无奈。你说这个药无效吧,第一组的治愈率确实比第二组要好。你说这个药有效吧,疗效似乎不怎么明显,死亡率还上升了。
这就得用到统计方法了。这个思想的关键,就是我们要判断,现在这个结果,到底是药物疗效导致的呢,还是纯粹是个偶然事件。
咱们干脆考虑一个最简单的例子,只看死活:假设第一组的所有病人都活着,而第二组死了5个病人。也许正是新药的疗效,才让第一组没死人,但也许这只是一个巧合。
科学家的做法,是先来一个无效假设:假设药物无效,并且这个疾病的死亡率就是第二组所揭示的10%。
科学家的问题是,如果这个无效假设是对的,那么请问,出现第一组不死人这个结果的可能性,有多大?
这个问题的本质,就是问,你第一组这么好的结果,到底是不是纯属偶然。纯属偶然是完全可能的。
哪怕药物完全无效,以至于这个病还是有10%的死亡率,那也不见得第一组就也应该死5个病人 — 你要知道,哪怕是抛硬币,也存在一个连抛50次都正面朝上的可能性。
那我们就来算算这个可能性。每个病人不死的概率是0.9,50个人都不死的可能性就是0.9的50次方,等于0.00515。
科学家把无效假设成立的可能性,称为“ P值 ”。那么在这个例子中,P = 0.00515。
那也就是说,无效假设不成立、第一组实验结果并非偶然的可能性,是 1 - P = 0.99485。
那么科学家就会这么写论文:“实验证明,这种药是有效的,P = 0.00515。”
读者读到这句话,就可以这么理解,实验结果应该不是巧合,这种药有效的可能性高达99.485%。
这才是理解论文的正确思路。P 值告诉我们巧合的可能性。
P.S. 这种药有效的可能性高达99.485%,其实是错的,P 值的真正意思是说, 相对于“死亡率是10%”这个“无效假设” ,实验结果纯属巧合的可能性是0.00515。
回到最初的案例,在一定的 P 值的指导之下 ,我们也许可以说:药物疗效大概是真的,第一组的治愈率高 很可能不是巧合,而第一组多死了一个人这件事, 很可能只是巧合。
现在学术界的一个几乎是“黄金标准”的标准,是 P 值要小于 0.05。如果 P > 0.05 ,别人会认为你这个结果很可能纯属巧合,根本不值得认真对待,你都不好意思写论文发表。如果 P < 0.05 ,人们就说这个结果是“ 显著的(significant) ”。
为啥非得是 0.05 呢? 纯粹是科学家的约定俗成而已。当然是越精确(越小)越好,但做实验想要得到 P 值小于0.001的结果,需要找太多受试者,成本实在太高。大家退而求其次,都默认了 0.05。
其实就算做到了 P < 0.05,也不能说实验结果就是真的。
P = 0.05 意味着有 1/20 的可能性,在你这个特定的无效假设之下,这篇论文的结果纯属巧合。事实情况比这个严重得多,如果你考虑到无效假设的任意性之类的统计方法上的因素(比如上面说读者可以这样理解 — 这种药有效的可能性高达99.485%”,P 值的真正意思是说, 相对于“死亡率是10%”这个“无效假设” ,实验结果纯属巧合的可能性是0.00515。那我为啥非得用死亡率是10%这个无效假设,我为什么不用别的无效假设呢?这纯粹是科学家的主观选择。),一篇 P = 0.01 的论文,属于巧合的可能性,在某些情况下,高达11%!
如果你把很多论文都放在一起,看看 P 值在这些论文中的分布情况,你就会发现一个很有意思的现象。
P < 0.05 纯粹是人为的约定,没有任何自然意义,所以各个研究中 P 值的分布应该是一条光滑的曲线,0.05这个数值在曲线上不应该有任何突兀之处,对吧?当然,有些 P > 0.05 的结果也许没有发表,那么曲线应该在0.05这个地方有个截断,但是0.05不应该比0.045重要,对吧?
可过去这几年,就不断有研究发现,在经济学、心理学和生物学论文中, P 值的分布,在0.05处有个明显的凸起:
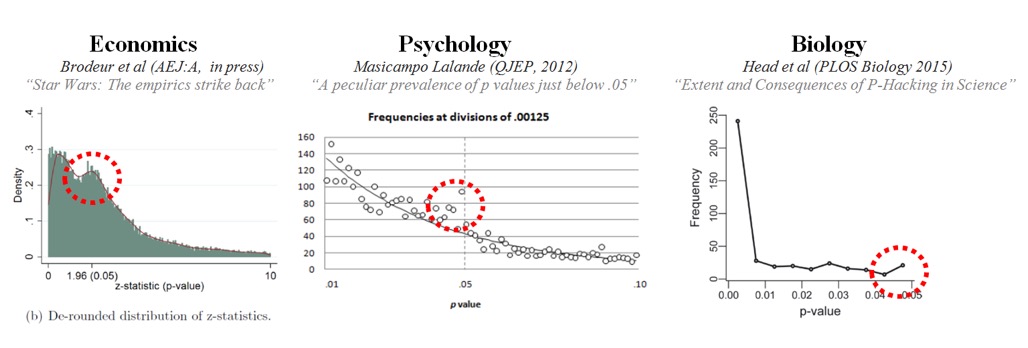
唯一的解释,就是有很多论文故意把 P 值做到了“恰好”在 0.05 以内。
2.5 问卷调查:在收集数据这个场景下,问卷是最常见、最重要的工具之一
如果想了解人的内部状态,那就用问卷。
可目前的问题就是问卷得出的数据不真实怎么破……不光数据不真实而且相当费钱?
其实能主动去学习一下怎么做问卷调查,这就很不错了。
诺曼·布拉德伯恩的《问卷设计手册:市场研究、民意调查、社会调查、健康调查指南》,十分推荐。
问卷的核心是问,而不是卷。
比如高考,冰淇淋能出现在高考试卷上吗?答案是,不能。因为农村很多孩子没有吃过,甚至没有见过冰淇淋,所以这些孩子就会不理解。这样的考题对他们就不公平。
回答必须让答题者准确理解,还有一层意思就是,你得问答题者可以回答的问题。
一整套提问下来,好的问卷(考卷)可以反应真实水平,让100分的人得到100分,让80分的人得80·····
我看新浪网经常会做各种在线投票调查,它给的那些选项,常常在逻辑上都不完备,更不用说还都有倾向性。我一看那个问卷都火冒三丈。
2.6 变量实验:以确立因果关系为目标的收集数据的方式
生活里还有一些时候,我们就是看到了两个事物,想确定它们之间有没有因果关系,或者想知道一个判断是不是靠谱。这时候还可以怎么办呢?
以确立因果关系为目标的收集数据的方式——实验。
因果关系的表达应该是这样的句式,“因为……所以……”。因为你吃了这片药,所以你变聪明了。但关键问题是,怎么证明这件事呢?怎么证明确实是吃药让人变聪明了呢?
要证明这一点,就要分好几步。
第一步,肯定是要吃药。
吃药这个行为,用实验的术语就叫“操纵自变量”,也叫“干预”,也可以叫“处理”。这一步看起来好像很容易,只要受试者把药吃了就行。但实际上,非常不容易。这个药是用水服下的,还是用茶水服下的?是整个吞下的,还是碾碎了吃的?是饭前吃的,还是饭后吃的……也就是说,你要保证干预和处理的标准一致。
第二步,吃药之后,得看看受试者是不是比吃药前更聪明了。
怎么证明这一点呢?得做两次智商测验。实验开始前做一次,比如得了90分,吃药之后一小时,再做一次。只有得分大于90,而且还得大不少,才能说明确实变聪明了。要是第二次测验得了91分,只比原来多1分,你说吃这个药会让人变聪明,我估计不会有人相信的。智商测试本来就是个范围,万一有误差呢?
这里,智商是因变量,也就是我们要干预或者处理的结果。智商测试,就是测量因变量。
其中,第一次智商测试,用实验的术语叫“前测”;第二次测试,就叫“后测”。后测和前测的差异,也就是你实施干预或者处理的前后差别,就是“效果”。
如果差异大,就说明有效果。此时,你就可以下结论——吃这款药是你变聪明的原因。
实验法通过操纵自变量、控制无关变量、观测因变量这样的逻辑,确保得出因果性结论。
既找到了因果性,也能知道原因的效果大小。
但事实上,在实验室发生的社会过程很难在真实的社会环境中出现,所以实验室中发现的效应很多都是临时的,不能应用到社会上。
因此,实验法特别适合范围有限、界定明确的概念和假设。
三、理解数据
1.1 事物定性:怎么用数据去表征一个事物呢?
四、操作数据
概率统计
概率世界
统计世界
社会网络:最潮流、最前沿的定量分析方法
市场调研:
以上是关于数字如潮人如水的主要内容,如果未能解决你的问题,请参考以下文章