《C++Primer(第5版)》第十三章笔记
Posted qq_34132502
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《C++Primer(第5版)》第十三章笔记相关的知识,希望对你有一定的参考价值。
第十三章——拷贝控制
当定义一个类时,我们显式地或隐式地指定在此类型的对象拷贝、移动、赋值和销毁时做什么。一个类通过定义五种特殊的成员函数来控制这些操作,包括:拷贝构造函数、 拷贝赋值运算符、移动构造函数、移动赋值运算符和析构函数。 拷贝和移动构造函数定义了当用同类型的另一个对象初始化本对象时做什么。拷贝和移动赋值运算符定义了将一个对象赋予同类型的另一个对象时做什么。析构函数定义了当此类型对象销毁时做什么。我们称这些操作为拷贝控制操作。
13.1 拷贝、赋值与销毁
13.1.1 拷贝构造函数
如果一个构造函数的第一个参数是自身类类型的引用,且任何额外参数都有默认值,则此构造函数是拷贝构造函数。
class Foo{
Foo(); // 默认构造函数
Foo(const Foo&); // 拷贝构造函数
};
虽然我们可以定义一个接受非const引用的拷贝构造函数,但此参数几乎总是一个const的引用。拷贝构造函数在几种情况下都会被隐式地使用。因此,拷贝构造函数通常不应该是explicit(声明为explicit的构造函数,不能用于对象的隐式创建)的。
合成拷贝构造函数
如果我们没有为一个类定义拷贝构造函数,编译器会为我们定义一个。与合成默认构造函数不同,即使我们定义了其他构造函数,编译器也会为我们合成一个拷贝构造函数。编译器从给定对象中依次将每个非static成员拷贝到正在创建的对象中。
每个成员的类型决定了它如何拷贝:对类类型的成员,会使用其拷贝构造函数来拷贝;内置类型的成员则直接拷贝。虽然我们不能直接拷贝一个数组,但合成拷贝构造函数会逐元素地拷贝一个数组类型的成员。如果数组元素是类类型,则使用元素的拷贝构造函数来进行拷贝。
例如,Sales_data类的合成拷贝构造函数等价于:
class Sales_data {
public:
// ...
// 与合成的拷贝构造函数等价的拷贝构造函数声明
Sales_data(const Sales_data&);
private:
std:string bookNo;
int units_sold = 0;
double revenue = 0.0;
};
// 与Sales_data的合成的拷贝构造函数等价
Sales_data::Sales_data(const Sales_data &orig):
bookNo(orig.bookNo), // 使用string的拷贝构造函数
units_sold(orig.units_sold), // 拷贝orig.units_sold
revenue(orig.revenue) // 拷贝orig.revenue
{} // 空函数体
拷贝初始化
现在,我们可以完全理解直接初始化和拷贝初始化之间的差异了
当使用直接初始化时,我们实际上是要求编译器使用普通的函数匹配来选择与我们提供的参数最匹配的构造函数。当我们使用拷贝初始化(copy initialzation)时,我们要求编译器将右侧运算对象拷贝到正在创建的对象中,如果需要的话还要进行类型转换。
如果一个类有移动构造函数,则拷贝初始化有时会使用移动构造函数而非拷贝构造函数来完成。
拷贝初始化不仅在我们使用=定义变量时会发生,在下列情况也会:
- 将一个对象作为实参传递给一个非引用类型的形参
- 从一个返回类型为非引用类型的函数返回一个对象
- 用花括号列表初始化一个数组中的元素或一个聚合类中的成员
某些类类型还会对它们所分配的对象使用拷贝初始化。例如,当我们初始化标准库容器或是调用其insert或push成员时,容器会对其元素进行拷贝初始化。与之相对,用emplace成员创建的元素都进行直接初始化。
参数和返回值
在函数调用过程中,具有非引用类型的参数要进行拷贝初始化。类似的,当一个函数具有非引用的返回类型时,返回值会被用来初始化调用方的结果。
拷贝构造函数被用来初始化非引用类类型参数,这一特性解释了为什么拷贝构造函数自己的参数必须是引用类型。如果其参数不是引用类型,则调用永远也不会成功——为了调用拷贝构造函数,我们必须拷贝它的实参,但为了拷贝实参,我们又需要调用拷贝构造函数,如此无限循环。
拷贝初始化的限制
如前所述,如果我们使用的初始化值要求通过一个explicit的构造函数来进行类型转换,那么使用拷贝初始化还是直接初始化就不是无关紧要的了:
vector<int> v1(10); // 正确:直接初始化
vector<int> v2 = 10; // 错误接受大小参数的构造函数是explicit的
void f(vvector<int>); // f的参数进行拷贝初始化
f(10); // 错误:不能用一个explicit的构造函数拷贝一个实参
f(vector<int>(10)); // 正确:从一个int直接构造一个临时vector
直接初始化v1是合法的,但看起来与之等价的拷贝初始化v2则是错误的,因为vector的接受单一大小参数的构造函数是explicit的。出于同样的原因,当传递一个实参或从函数返回一个值时,我们不能隐式使用一个explicit构造函数(先隐式的构造一个vector再通过拷贝构造传递过去)。如果我们希望使用一个explicit构造函数,就必须显式地使用,像此代码中最后一行那样。
编译器可以绕过拷贝构造函数
在拷贝初始化过程中,编译器可以(但不是必须)跳过拷贝/移动构造函数,直接创建对象。即,编译器被允许将下面的代码:
string null_book = "9-999-99999-9"; // 拷贝初始化
改写为
string null_bool("9-999-99999-9"); // 编译器略过了拷贝构造函数
但是,即使编译器略过了拷贝/移动构造函数,但在这个程序点上,拷贝/移动构造函数必须是存在且可访问的(例如,不能是private的)。
13.1.2 拷贝赋值运算符
与类控制其对象如何初始化一样,类也可以控制其对象如何赋值:
Sales_data trans, accum;
trans = accum;
与拷贝构造函数-一样,如果类未定义自己的拷贝赋值运算符,编译器会为它合成一个。
合成拷贝赋值运算符
与处理拷贝构造函数一样,如果一个类未定义自己的拷贝赋值运算符,编译器会为它生成一个合成拷贝赋值运算符( synthesized copy-assignment operator)。类似拷贝构造函数,对于某些类,合成拷贝赋值运算符用来禁止该类型对象的赋值。如果拷贝赋值运算符并非出于此目的,它会将右侧运算对象的每个非static成员赋予左侧运算对象的对应成员,这一工作是通过成员类型的拷贝赋值运算符来完成的。对于数组类型的成员,逐个赋值数组元素。合成拷贝赋值运算符返回一个指向其左侧运算对象的引用。
例如,下面的代码等价于Sales_data的合成拷贝赋值运算符:
Sales_data& Sales_data::operator=(const Sales_data &rhs) {
bookNo = rhs.bookNo; // 调用string::operator=
units_sold = rhs.units_sold; // 使用内置的int赋值
revennue = rhs.revenue; // 使用内置的double赋值
return *this; // 返回一个此对象的引用
}
13.1.3 析构函数
析构函数执行与构造函数相反的操作:构造函数初始化对象的非static数据成员,还可能做一些其他工作;析构函数释放对象使用的资源,并销毁对象的非static数据成员。
析构函数不接受参数,因此不能被重载
析构函数完成什么任务
在构造函数中,成员的初始化是在函数体执行之前完成的,按照它们在类中出现的顺序进行初始化
在析构函数中,首先执行函数体,然后销毁成员,按照初始化顺序逆序销毁
在一个析构函数中,不存在类似构造函数中初始化列表的东西来控制成员如何销毁,析构部分是隐式的。成员销毁时发生什么完全依赖于成员的类型。销毁类类型的成员需要执行成员自己的析构函数。内置类型没有析构函数,因此销毁内置类型成员什么也不需要做。
与普通指针不同,智能指针是类类型,所以具有析构函数。因此,与普通指针不同,智能指针成员在析构阶段会被自动销毁。
【Note】隐式销毁一个内置指针类型的成员不会delete它所指向的对象。
什么时候会调用析构函数
无论何时一个对象被销毁,就会自动调用其析构函数:
- 变量在离开其作用域时被销毁。
- 当一个对象被销毁时,其成员被销毁。
- 容器(无论是标准库容器还是数组)被销毁时,其元素被销毁。
- 对于动态分配的对象,当对指向它的指针应用delete运算符时被销毁。
- 对于临时对象,当创建它的完整表达式结束时被销毁。
由于析构函数自动运行,我们的程序可以按需要分配资源,而(通常)无须担心何时释放这些资源
合成析构函数
当一个类未定义自己的析构函数时,编译器会为它定义–个合成析构函数。类似拷贝构造函数和拷贝赋值运算符,对于某些类,合成析构函数被用来阻止该类型的对象被销毁。如果不是这种情况,合成析构函数的函数体就为空。
例如,下面的代码等价于Sales_data的合成析构函数:
class Sales_data{
public:
// 成员会被自动销毁,除此之外不需要做其他事情
~Sales_data() {}
// ...
};
13.1.4 三 / 五法则
如前所述,有三个基本操作可以控制类的拷贝操作:拷贝构造函数、拷贝赋值运算符和析构函数。而且,在新标准下,一个类还可以定义一个移动构造函数和一个移动赋值运算符。
C++语言并不要求我们定义所有这些操作:可以只定义其中一个或两个,而不必定义所有。但是,这些操作通常应该被看作一个整体。通常,只需要其中一个操作,而不需要定义所有操作的情况是很少见的。
需要析构函数的类也需要拷贝和赋值操作
当我们决定一个类是否要定义它自己版本的拷贝控制成员时,一个基本原则是首先确定这个类是否需要一个析构函数。通常,对析构函数的需求要比对拷贝构造函数或赋值运算符的需求更为明显。如果这个类需要-个析构函数,我们几乎可以肯定它也需要一个拷贝构造函数和一个拷贝赋值运算符。
如一个类HasPtr有一个内置指针作为成员,需要在构造函数中分配动态内存。析构函数不会delete一个指针数据成员,因此需要析构函数。
假设使用合成拷贝构造函数和合成拷贝赋值运算符:
class HasPtr{
public:
HasPtr(const str::string &s = std::string()):
ps(new std::string(s)), i(0) {}
~HasPtr() {delete ps;}
private:
std::string *ps;
int i;
};
如果只是简单地拷贝指针,则意味着可能多个HasPtr对象指向相同的内存,这显然有重大风险。
需要拷贝操作的类也需要赋值操作,反之亦然
虽然很多类需要定义所有(或是不需要定义任何)拷贝控制成员,但某些类所要完成的工作,只需要拷贝或赋值操作,不需要析构函数。
作为一个例子,考虑一个类为每个对象分配一个独有的、 唯一的序号。 这个类需要一个拷贝构造函数为每个新创建的对象生成-一个新的、独一无二的序号。除此之外,这个拷贝构造函数从给定对象拷贝所有其他数据成员。这个类还需要自定义拷贝赋值运算符来避免将序号赋予目的对象。但是,这个类不需要自定义析构函数。
这个例子引出了第二个基本原则:如果一个类需要一个拷贝构造函数,几乎可以肯定它也需要一个拷贝赋值运算符。反之亦然——如果一个类需要一个拷贝赋值运算符,几乎可以肯定它也需要一个拷贝构造函数。然而,无论是需要拷贝构造函数还是需要拷贝赋值运算符都不必然意味着也需要析构函数。
13.1.5 使用=default
我们可以通过将拷贝控制成员定义为=default来显式地要求编译器生成合成的版本:
class Sales_data{
public:
Sales_data() = default;
Sales_data(const Sales_data&) = default;
Sales_data& operator=(const Sales_data&);
~Sales_data() = default;
}
Sales_data& Sales_data::operator=(const Sales_data&) = default;
13.1.6 阻止拷贝
例如,iostream 类阻止了拷贝,以避免多个对象写入或读取相同的IO缓冲。
定义删除的函数
删除的函数是这样一种函数:我们虽然声明了它们,但不能以任何方式使用它们。在函数的参数列表后面加上=delete来指出我们希望将它定义为删除的:
struct NoCopy{
NoCopy() = default;
NoCopy(const NoCopy&) = delete;
NoCopy &operator=(const NoCopy&) = delete;
~NoCopy() = default;
};
与=default不同,=delete必须出现在函数第一次声明的时候,这个差异与这些声明的含义在逻辑上是吻合的。一个默认的成员只影响为这个成员而生成的代码,因此=default直到编译器生成代码时才需要。而另一方面,编译器需要知道一个函数是删除的,以便禁止试图使用它的操作。
与=default的另一个不同之处是,我们可以对任何函数指定=delete(我们只能对编译器可以合成的默认构造函数或拷贝控制成员使用=default)。虽然删除函数的主要用途是禁止拷贝控制成员,但当我们希望引导函数匹配过程时,删除函数有时也是有用的。
析构函数不能使删除的成员
合成的拷贝控制成员可能是删除的
如前所述,如果我们未定义拷贝控制成员,编译器会为我们定义合成的版本。类似的,如果一个类未定义构造函数,编译器会为其合成一个默认构造函数。对某些类来说,编译器将这些合成的成员定义为删除的函数:
- 如果类的某个成员的析构函数是删除的或不可访问的(例如,是private的),则类的合成析构函数被定义为删除的。
- 如果类的某个成员的拷贝构造函数是删除的或不可访问的,则类的合成拷贝构造函数被定义为删除的。如果类的某个成员的析构函数是删除的或不可访问的,则类合成的拷贝构造函数也被定义为删除的。
- 如果类的某个成员的拷贝赋值运算符是删除的或不可访问的,或是类有一个const的或引用成员,则类的合成拷贝赋值运算符被定义为删除的。
- 如果类的某个成员的析构函数是删除的或不可访问的,或是类有一个引用成员,它没有类内初始化器,或是类有一个const成员,它没有类内初始化器且其类型未显式定义默认构造函数,则该类的默认构造函数被定义为删除的。
本质上,这些规则的含义是:如果一个类有数据成员不能默认构造、拷贝、复制或销毁,则对应的成员函数将被定义为删除的。
private拷贝控制
在新标准发布之前,类是通过将其拷贝构造函数和拷贝赋值运算符声明为private的来阻止拷贝
class PrivateCopy{
// 无访问说明符,接下来的成员默认为private
PrivateCopy(const PrivateCopy&);
PrivateCopy &operator=(const PrivateCopy&);
public:
PrivateCopy() = default;
~PrivateCopy();
};
由于析构函数是public的,用户可以定义PrivateCopy类型的对象。但是,由于拷贝构造函数和拷贝赋值运算符是private的,用户代码将不能拷贝这个类型的对象。但是,友元和成员函数仍旧可以拷贝对象。为了阻止友元和成员函数进行拷贝,我们将这些拷贝控制成员声明为private的,但并不定义它们。
声明但不定义一个成员函数是合法的,对此只有一个例外。试图访问一个未定义的成员将导致一个链接时错误。通过声明(但不定义)private的拷贝构造函数,我们可以预先阻止任何拷贝该类型对象的企图:试图拷贝对象的用户代码将在编译阶段被标记为错误:成员函数或友元函数中的拷贝操作将会导致链接时错误。
13.2 拷贝控制和资源管理
我们首先必须确定此类型对象的拷贝语义。一般来说,有两种选择:可以定义拷贝操作,使类的行为看起来像一个值或者像一个指针。
类的行为像一个值,意味着它应该也有自己的状态。当我们拷贝一个像值的对象时,副本和原对象是完全独立的。改变副本不会对原对象有任何影响,反之亦然。
行为像指针的类则共享状态。当我们拷贝一个这种类的对象时,副本和原对象使用相同的底层数据。改变副本也会改变原对象,反之亦然。
在我们使用过的标准库类中,标准库容器和string类的行为像一个值。 而不出意外的,shared_ptr类提供类似指针的行为。
13.2.1 行为像值的类
为了提供类值的行为,对于类管理的资源,每个对象都应该拥有一份自己的拷贝。这意味着对于ps指向的string,每个HasPtr对象都必须有自己的拷贝。为了实现类值行为,HasPtr需要
- 定义一个拷贝构造函数,完成string的拷贝,而不是拷贝指针
- 定义一个析构函数来释放string
- 定义一个拷贝赋值运算符来释放对象当前的string, 并从右侧运算对象拷贝string
class HasPtr {
public:
HasPtr(const std:string &s = std::string()):
ps(new std::string(s)), i(0) { }
// 对ps指向的string,每个HasPtr对象都有自己的拷贝
HasPtr(const HasPtr &p):
ps(new std::string(*p.ps)), i(p.i) { }
~HasPtr() { delete ps; }
private:
std::string *ps;
int i;
};
类值拷贝赋值运算符
赋值运算符通常组合了析构函数和构造函数的操作。类似析构函数,赋值操作会销毁左侧运算对象的资源。类似拷贝构造函数,赋值操作会从右侧运算对象拷贝数据。但是,非常重要的一点是, 这些操作是以正确的顺序执行的,即使将一个对象赋予它自身,也保证正确。而且,如果可能,我们编写的赋值运算符还应该是异常安全的——当异常发生时能将左侧运算对象置于一个有意义的状态。
在本例中,通过先拷贝右侧运算对象,我们可以处理自赋值情况,并能保证在异常发生时代码也是安全的。在完成拷贝后,我们释放左侧运算对象的资源,并更新指针指向新分配的string:
HasPtr& HasPtr::operator=(const HasPtr &rhs){
auto newp = new string(*rhs.ps); // 拷贝底层string
delete ps; // 释放旧内存
ps = newp; // 从右侧运算对象拷贝数据到本对象
i = rhs.i;
return *this; // 返回本对象
}
赋值运算符:
当编写赋值运算符是,有两点需要记住
- 如果将一个对象赋予它自身,赋值运算符必须能正确工作
- 大多数赋值运算符组合了析构函数和拷贝构造函数
当编写一个赋值运算符时,一个好的模式是先将右侧运算对象拷贝到一个局部临时对象中。当拷贝完成后,销毁左侧运算对象的现有成员就是安全的了。一旦左侧运算对象的资源被销毁,就只剩下将数据从临时对象拷贝到左侧运算对象的成员中了。
13.2.2 定义行为像指针的类
对于行为类似指针的类,我们需要为其定义拷贝构造函数和拷贝赋值运算符,来拷贝指针成员本身而不是它指向的string。 我们的类仍然需要自己的析构函数来释放接受string参数的构造函数分配的内存。但是,在本例中,析构函数不能单方面地释放关联的string。只有当最后一个指向string的HasPtr销毁时,它才可以释放string。
令一个类展现类似指针的行为的最好方法是使用shared_ptr来管理类中的资源。拷贝(或赋值)一个shared_ptr会拷贝(赋值)shared_ptr所指向的指针。shared_ptr类自己记录有多少用户共享它所指向的对象。当没有用户使用对象时,shared_ptr类负责释放资源。
但是,有时我们希望直接管理资源。在这种情况下,使用引用计数(reference count)就很有用了。为了说明引用计数如何工作,我们将重新定义HasPtr,令其行为像指针一样,但我们不使用shared_ptr,,而是设计自己的引用计数。
引用计数
引用计数工作方式如下:
- 除了初始化对象外,每个构造函数(拷贝构造函数除外)还要创建一个引用计数,用来记录有多少对象与正在创建的对象共享状态。当我们创建一个对象时, 只有一个对象共享状态,因此将计数器初始化为1。
- 拷贝构造函数不分配新的计数器,而是拷贝给定对象的数据成员,包括计数器。拷贝构造函数递增共享的计数器,指出给定对象的状态又被一个新用户所共享。
- 析构函数递减计数器,指出共享状态的用户少了一个。如果计数器变为0,则析构函数释放状态。
- 拷贝赋值运算符递增右侧运算对象的计数器,递减左侧运算对象的计数器。如果左侧运算对象的计数器变为0,意味着它的共享状态没有用户了,拷贝赋值运算符就必须销毁状态。
解决此问题的一种方法是将计数器保存在动态内存中。当创建一个对象时,我们也分配一个新的计数器。当拷贝或赋值对象时,我们拷贝指向计数器的指针。使用这种方法,副本和原对象都会指向相同的计数器。
定义一个使用引用计数的类
class HasPtr {
public:
// 构造函数分配的新的string和新的计数器,将计数器置为1
HasPtr(const std::string &s = std::string()):
ps(new std::string(s)), i(0), use(new std::size_t(1)) {}
// 拷贝构造函数拷贝所有单个数据成员,并递增计数器
HasPtr& operator=(const HasPtr&);
~HasPtr();
private:
std::string *ps;
int i;
std::size_t *use; // 用来记录有多少个对象共享*ps的成员。
};
类指针的拷贝成员“篡改”引用计数
当拷贝或赋值一个HasPtr对象时,我们希望副本和原对象都指向相同的string。即,当拷贝一个HasPtr时,我们将拷贝ps本身,而不是ps指向的string。当我们进行拷贝时,还会递增该string关联的计数器。
(我们在类内定义的)拷贝构造函数拷贝给定HasPtr的所有三个数据成员。这个构造函数还递增use成员,指出ps和p.ps指向的string又有了一个新的用户。
析构函数不能无条件地delete ps——可能还有其他对象指向这块内存。析构函数应该递减引用计数,指出共享string的对象少了一个。如果计数器变为0,则析构函数释放ps和use指向的内存:
HasPtr::~HasPtr() {
if (--*use == 0) { // 如果引用计数变为0
delete ps; // 释放string内存
delete use; // 释放计数器内存
}
}
拷贝赋值运算符与往常一样执行类似拷贝构造函数和析构函数的工作。即,它必须递增右侧运算对象的引用计数(即,拷贝构造函数的工作),并递减左侧运算对象的引用计数,在必要时释放使用的内存(即,析构函数的工作)。
而且与往常一样, 赋值运算符必须处理自赋值。我们通过先递增rhs中的计数然后再递减左侧运算对象中的计数来实现这一 点。通过这种方法,当两个对象相同时,在我们检查ps(及use)是否应该释放之前,计数器就已经被递增过了:
HasPtr& HasPtr::operator=(const HasPtr &rhs) {
++*rhs.use; // 递增右侧运算对象的引用计数
if (--*use == 0) { // 然后递增本对象的引用计数
delete ps; // 如果没有其他用户
delete use; // 释放本对象分配的成员
}
ps = rhs.ps; // 将数据从rhs拷贝到本对象
i = rhs.i;
use = rhs.use;
return *this; // 返回本对象
}
13.3 交换操作
除了定义拷贝控制成员,管理资源的类通常还定义一个名为swap的函数。对于那些与重排元素顺序的算法一起使用的类,定义swap是非常重要的。这类算法在需要交换两个元素时会调用swap。
如果一个类定义了自己的swap,那么算法将使用类自定义版本。否则,算法将使用标准库定义的swap。虽然与往常一样我们不知道swap是如何实现的,但理论上很容易理解,为了交换两个对象我们需要进行一次拷贝和两次赋值。例如,交换两个类值HasPtr对象的代码可能像下面这样:
HasPtr temp = v1;
v1 = v2;
v2 = temp;
理论上,这些内存分配都是不必要的。我们更希望swap交换指针,而不是分配string的新副本。即,我们希望这样交换两个HasPtr:
string *temp = v1.ps;
v1.ps = v2.ps;
v2.ps = temp;
编写我们自己的swap函数
可以在我们的类上定义一个自己版本的swap来重载swap的默认行为:
class HasPtr{
friend void swap(HasPtr&, HasPtr&);
// ...
};
inline void swap(HasPtr& &lhr, HasPtr &rhs) {
using std::swap;
swap(lhs.ps, rhs.ps); // 交换指针,而不是string数据
swap(lhs.i, rhs.i); // 交换int成员
}
我们首先将swap定义为friend,以便能访问HasPtr的(private的)数据成员。由于swap的存在就是为了优化代码,我们将其声明为inline函数。swap的函数体对给定对象的每个数据成员调用swap。我们首先swap绑定到rhs和lhs的对象的指针成员,然后是int成员。
值得注意的是,这里的swap函数调用了std::swap,而不是swap。因为他的成员函数都是内置数据类型。但如果是自己定义的类型的话,则必须使用那个类型所定义的swap。如果类Foo中含有一个类型为HasPtr的成员h:
void swap(Foo &lhs, Foo &rhs) {
// 错误:这个函数使用了标准库版本的swap,而不是HasPtr版本
std::swap(lhs.h, rhs.h);
// 其他swap
}
与拷贝控制成员不同,swap 并不是必要的。但是,对于分配了资源的类,定义swap可能是一种很重要的优化手段。
在赋值运算符中使用swap
定义swap的类通常用swap来定义它们的赋值运算符。这些运算符使用了一种名为拷贝并交换的技术。这种技术将左侧运算对象与右侧运算对象的一个副本进行交换:
// 注意rhs是按值传递的,意味着HasPtr的拷贝构造函数将右侧运算对象中的string拷贝到rhs
HasPtr& HasPtr::operator=(HasPtr rhs) {
swap(*this, rhs); // rhs现在指向本对象曾经使用的内存
return *this; // rhs被销毁,从而delete了rhs中的指针
}
在这个版本的赋值运算符中,参数并不是一个引用,我们将右侧运算对象以传值方式传递给了赋值运算符。因此,rhs是右侧运算对象的一个副本。参数传递时拷贝HasPtr的操作会分配该对象的string的一个新副本。
在赋值运算符的函数体中,我们调用swap来交换rhs和*this中的数据成员。这个调用将左侧运算对象中原来保存的指针存入rhs中,并将rhs中原来的指针存入*this中。因此,在swap调用之后,*this 中的指针成员将指向新分配的string——右侧运算对象中string的一个副本。当赋值运算符结束时,rhs被销毁,HasPtr的析构函数将执行。此析构函数deleterhs现在指向的内存,即,释放掉左侧运算对象中原来的内存。
这个技术的有趣之处是它自动处理了自赋值情况且天然就是异常安全的。它通过在改变左侧运算对象之前拷贝右侧运算对象保证了自赋值的正确,这与我们在原来的赋值运算符中使用的方法是一致的。它保证异常安全的方法也与原来的赋值运算符实现一样。代码中唯一可能抛出异常的是拷贝构造函数中的new表达式。如果真发生了异常,它也会在我们改变左侧运算对象之前发生。
使用拷贝和交换的赋值运算符自动就是异常安全的,且能正确处理自赋值。
14.3 拷贝控制示例
虽然通常来说分配资源的类更需要拷贝控制,但资源管理并不是一个类需要定义自己的拷贝控制成员的唯一原因。一些类也需要拷贝控制成员的帮助来进行簿记工作或其他操作。
作为类需要拷贝控制来进行簿记操作的例子,我们将概述两个类的设计,这两个类可能用于邮件处理应用中。两个类命名为Message和Folder吗,分别表示电子邮件消息和消息目录。每个Message对象可以出现在多个Folder中。但是,任意给定的Message的内容只有一个副本。这样,如果一条Message的内容被改变,则我们从它所在的任何Folder来浏览此Message时,都会看到改变后的内容。
为了记录Message位于哪些Folder中,每个Message都会保存一个它所在Folder的指针的set,同样的,每个Folder都保存一-个它包含的Message的指针的set。
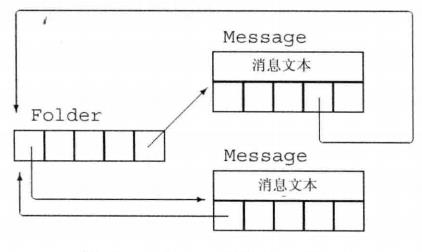
当我们拷贝一个Message时,副本和原对象将是不同的Message 对象,但两个Message都出现在相同的Folder中。因此,拷贝Message的操作包括消息内容和Folder指针set的拷贝。而且,我们必须在每个包含此消息的Folder中都添加一个指向新创建的Message的指针。
当我们将一个Message对象赋予另一个Message对象时,左侧Message的内容会被右侧Message的内容所替代。我们还必须更新Folder集合,从原来包含左侧Message的Folder中将它删除,并将它添加到包含右侧Message的Folder中。
观察这些操作,我们可以看到,析构函数和拷贝赋值运算符都必须从包含一条Message的所有Folder中删除它。类似的,拷贝构造函数和拷贝赋值运算符都要将一个Message添加到给定的一组Folder中。我们将定义两个private的工具函数来完这些工作。
Message类
class Message {
friend class Folder;
public:
// folders被隐式初始化为空集合
explicit Message(const std::string& str = "") :
contents(str) {}
// 拷贝控制成员,用来管理指向本Message的指针
Message(const Message&);
Message& operator=(const Message&);
~Message();
// 从给定Folder集合中添加、删除本Message
void save(Folder以上是关于《C++Primer(第5版)》第十三章笔记的主要内容,如果未能解决你的问题,请参考以下文章