利用 eBPF redirection 提升socket性能
Posted 一口Linux
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用 eBPF redirection 提升socket性能相关的知识,希望对你有一定的参考价值。
- p:这是一个存储 socket 信息的映射表。作用:
- 一段 BPF 程序监听所有的内核 socket 事件,并将新建的 socket 记录到这个 map;
- 另一段 BPF 程序拦截所有 sendmsg 系统调用,然后去 map 里查找 socket 对端,之后 调用 BPF 函数绕过 TCP/IP 协议栈,直接将数据发送到对端的 socket queue。
- cgroups:指定要监听哪个范围内的 sockets 事件,进而决定了稍后要对哪些 socket 做重定向。
sockmap 需要关联到某个 cgroup,然后这个 cgroup 内的所有 socket 就都会执行加 载的 BPF 程序。
运行本文中的例子一台主机就够了,非常适合 BPF 练手。译文所用的完整代码, 原文用的完整代码。
由于译者水平有限,本文不免存在遗漏或错误之处。如有疑问,请查阅原文。
以下是译文。
很多用户基于我们提供的服务来构建实时应用(real time applications),这些应用对性能 有着严格的要求,因而促使我们不断探索各种提升性能的方式,eBPF 就是尝试之一 ,用于加速应用之间的通信。由于这方面资料尚少,因此我们整理成两篇文章分享给大家: 本篇讲实现,下一篇 是一些性能测试和问题讨论。
引言
BPF 基础
通常情况下,eBPF 程序由两部分构成:
- 内核空间部分:内核事件触发执行,例如网卡收到一个包、系统调用创建了一个 shell 进程等等;
- 用户空间部分:通过某种共享数据的方式(例如 BPF maps)来读取内核部分产生的数据。
本文主要关注内核部分。内核支持不同类型的 eBPF 程序,它们各自可以 attach 到不同的 hook 点,如下图所示:
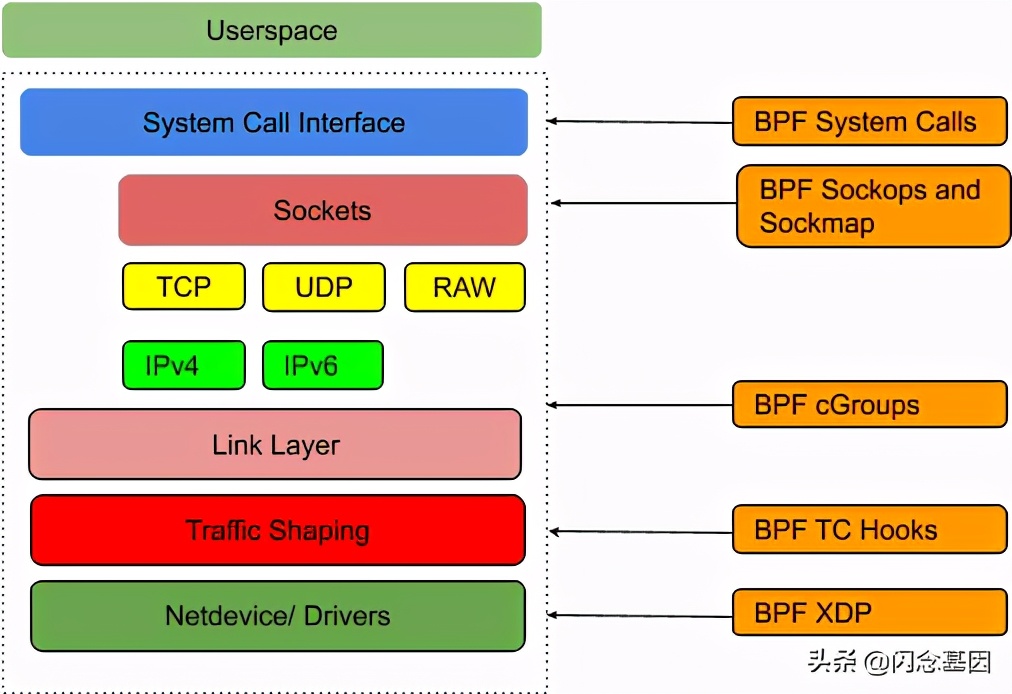
当内核中触发了与这些 hook 相关的事件(例如,发生 setsockopt() 系统调用)时, attach 到这里的 BPF 程序就会执行。
用户侧需要用到的所有 BPF 类型都定义在 UAPI bpf.h。 本文将主要关注下面两种能拦截到 socket 操作(例如 TCP connect、sendmsg 等)的类型:
- BPF_PROG_TYPE_SOCK_OPS:socket operations 事件触发执行。
- BPF_PROG_TYPE_SK_MSG:sendmsg() 系统调用触发执行。
本文将:
- 用 C 编写 eBPF 代码;
- 用 LLVM Clang 前端来生成 ELF bytecode;
- 用 bpftool 将代码加载到内核(以及从内核卸载)。
下面看代码实现。
本文 BPF 程序总体设计
首先创建一个全局的映射表(map)来记录所有的 socket 信息。基于这个 sockmap,编写两段 BPF 程序分别完成以下功能:
- 程序一:拦截所有 TCP connection 事件,然后将 socket 信息存储到这个 map;
- 程序二:拦截所有 sendmsg() 系统调用,然后从 map 中查 询这个 socket 信息,之后直接将数据重定向到对端。
BPF 程序一:监听 socket 事件,更新 sockmap
监听 socket 事件
程序功能:
- 系统中有 socket 操作时(例如 connection establishment、tcp retransmit 等),触发执行;
- 指定加载位置来实现:__section("sockops")
- 执行逻辑:提取 socket 信息,并以 key & value 形式存储到 sockmap。
代码如下:
__section("sockops") // 加载到 ELF 中的 `sockops` 区域,有 socket operations 时触发执行
int bpf_sockmap(struct bpf_sock_ops *skops)
{
switch (skops->op) {
case BPF_SOCK_OPS_PASSIVE_ESTABLISHED_CB: // 被动建连
case BPF_SOCK_OPS_ACTIVE_ESTABLISHED_CB: // 主动建连
if (skops->family == 2) { // AF_INET
bpf_sock_ops_ipv4(skops); // 将 socket 信息记录到到 sockmap
}
break;
default:
break;
}
return 0;
}
对于两端都在本节点的 socket 来说,这段代码会执行两次:
- 源端发送 SYN 时会产生一个事件,命中 case 2
- 目的端发送 SYN+ACK 时会产生一个事件,命中 case 1
因此对于每一个成功建连的 socket,sockmap 中会有两条记录(key 不同)。
提取 socket 信息以存储到 sockmap 是由函数 bpf_sock_ops_ipv4() 完成的,接下 来看下它的实现。
将 socket 信息写入 sockmap
static inline
void bpf_sock_ops_ipv4(struct bpf_sock_ops *skops)
{
struct sock_key key = {};
int ret;
extract_key4_from_ops(skops, &key);
ret = sock_hash_update(skops, &sock_ops_map, &key, BPF_NOEXIST);
if (ret != 0) {
printk("sock_hash_update() failed, ret: %d\\n", ret);
}
printk("sockmap: op %d, port %d --> %d\\n", skops->op, skops->local_port, bpf_ntohl(skops->remote_port));
}
三个步骤:
- 调用 extract_key4_from_ops() 从 struct bpf_sock_ops *skops(socket metadata)中提取 key;
- 调用 sock_hash_update() 将 key:value 写入全局的 sockmap sock_ops_map,这 个变量定义在我们的头文件中。
- 打印一行日志,方面我们测试用,后面会看到效果。
从 socket metadata 中提取 sockmap key
map 的类型可以是:
- BPF_MAP_TYPE_SOCKMAP
- BPF_MAP_TYPE_SOCKHASH
本文用的是第二种,sockmap 定义如下:
struct bpf_map_def __section("maps") sock_ops_map = {
.type = BPF_MAP_TYPE_SOCKHASH,
.key_size = sizeof(struct sock_key),
.value_size = sizeof(int), // 存储 socket
.max_entries = 65535,
.map_flags = 0,
};
key 定义如下:
struct sock_key {
uint32_t sip4; // 源 IP
uint32_t dip4; // 目的 IP
uint8_t family; // 协议类型
uint8_t pad1; // this padding required for 64bit alignment
uint16_t pad2; // else ebpf kernel verifier rejects loading of the program
uint32_t pad3;
uint32_t sport; // 源端口
uint32_t dport; // 目的端口
} __attribute__((packed));
下面是提取 key 的实现,非常简单:
static inline
void extract_key4_from_ops(struct bpf_sock_ops *ops, struct sock_key *key)
{
// keep ip and port in network byte order
key->dip4 = ops->remote_ip4;
key->sip4 = ops->local_ip4;
key->family = 1;
// local_port is in host byte order, and remote_port is in network byte order
key->sport = (bpf_htonl(ops->local_port) >> 16);
key->dport = FORCE_READ(ops->remote_port) >> 16;
}
插入 sockmap
sock_hash_update() 将 socket 信息写入到 sockmap,这个函数是我们定义的一个宏, 会展开成内核提供的一个 hash update 函数,不再详细展开。
小结
至此,第一段代码就完成了,它能确保我们拦截到 socket 建连事件,并将 socket 信息写入一个全局的映射表(sockmap)。
BPF 程序二:拦截 sendmsg 系统调用,socket 重定向
第二段 BPF 程序的功能:
- 拦截所有的 sendmsg 系统调用,从消息中提取 key;
- 根据 key 查询 sockmap,找到这个 socket 的对端,然后绕过 TCP/IP 协议栈,直接将 数据重定向过去。
要完成这个功能,需要:
- 在 socket 发起 sendmsg 系统调用时触发执行,
- 指定加载位置来实现:__section("sk_msg")
- 关联到前面已经创建好的 sockmap,因为要去里面查询 socket 的对端信息。
- 通过将 sockmap attach 到 BPF 程序实现:map 中的所有 socket 都会继承这段程序, 因此其中的任何 socket 触发 sendmsg 系统调用时,都会执行到这段代码。
拦截 sendmsg 系统调用
__section("sk_msg") // 加载目标文件(ELF )中的 `sk_msg` section,`sendmsg` 系统调用时触发执行
int bpf_redir(struct sk_msg_md *msg)
{
struct sock_key key = {};
extract_key4_from_msg(msg, &key);
msg_redirect_hash(msg, &sock_ops_map, &key, BPF_F_INGRESS);
return SK_PASS;
}
当 attach 了这段程序的 socket 上有 sendmsg 系统调用时,内核就会执行这段代码。它会:
- 从 socket metadata 中提取 key,
- 调用 bpf_socket_redirect_hash() 寻找对应的 socket,并根据 flag(BPF_F_INGRESS), 将数据重定向到 socket 的某个 queue。
从 socket message 中提取 key
static inline
void extract_key4_from_msg(struct sk_msg_md *msg, struct sock_key *key)
{
key->sip4 = msg->remote_ip4;
key->dip4 = msg->local_ip4;
key->family = 1;
key->dport = (bpf_htonl(msg->local_port) >> 16);
key->sport = FORCE_READ(msg->remote_port) >> 16;
}
Socket 重定向
msg_redirect_hash() 也是我们定义的一个宏,最终调用的是 BPF 内置的辅助函数。
最终需要用的其实是内核辅助函数 bpf_msg_redirect_hash(),但后者无法直接访问, 只能通过 UAPI linux/bpf.h 预定义的
BPF_FUNC_msg_redirect_hash 来访问,否则校验器无法通过。
msg_redirect_hash(msg, &sock_ops_map, &key, BPF_F_INGRESS) 几个参数:
- struct sk_msg_md *msg:用户可访问的待发送数据的元信息(metadata)
- &sock_ops_map:这个 BPF 程序 attach 到的 sockhash map
- key:在 map 中索引用的 key
- BPF_F_INGRESS:放到对端的哪个 queue(rx 还是 tx)
编译、加载、运行
bpftool 是一个用户空间工具,能用来加载 BPF 代码到内核、创建和更新 maps,以及收集 BPF 程序和 maps 信息。其源代码位于 Linux 内核树中:tools/bpf/bpftool。
编译
用 LLVM Clang frontend 来编译前面两段程序,生成目标代码(object code):
$ clang -O2 -g -target bpf -c bpf_sockops.c -o bpf_sockops.o
$ clang -O2 -g -target bpf -c bpf_redir.c -o bpf_redir.o
加载(load)和 attach sockops 程序
加载到内核:
$ sudo bpftool prog load bpf_sockops.o /sys/fs/bpf/bpf_sockops type sockops
- 这条命令将 object 代码加载到内核(但还没 attach 到 hook 点)
- 加载之后的代码会 pin 到一个 BPF 虚拟文件系统 来持久存储,这样就能获得一个指向这个程序的文件句柄(handle)供稍后使用。
- bpftool 会在 ELF 目标文件中创建我们声明的 sockmap(sock_ops_map 变量,定 义在头文件中)。
Attach 到 cgroups:
$ sudo bpftool cgroup attach /sys/fs/cgroup/unified/ sock_ops pinned /sys/fs/bpf/bpf_sockops
- 这条命令将加载之后的 sock_ops 程序 attach 到指定的 cgroup
- 这个 cgroup 内的所有进程的所有 sockets,都将会应用这段程序。如果使用的是 cgroupv2 时,systemd 会在 /sys/fs/cgroup/unified 自动创建一个 mount 点。
查看 map ID:
至此,目标代码已经加载(load)和附着(attach)到 hook 点了,接下来查看 sock_ops 程序所使用的 map ID,因为后面要用这个 ID 来 attach sk_msg 程序:
MAP_ID=$(sudo bpftool prog show pinned /sys/fs/bpf/bpf_sockops | grep -o -E 'map_ids [0-9]+'| cut -d '' -f2-)
$ sudo bpftool map pin id $MAP_ID /sys/fs/bpf/sock_ops_map
加载和 attach sk_msg 程序
加载到内核:
$ sudo bpftool prog load bpf_redir.o /sys/fs/bpf/bpf_redir \\
map name sock_ops_map \\
pinned /sys/fs/bpf/sock_ops_map
- 将程序加载到内核
- 将程序 pin 到 BPF 文件系统的 /sys/fs/bpf/bpf_redir 位置
- 重用已有的 sockmap,指定了 sockmap 的名字为 sock_ops_map 并且文件路径为 /sys/fs/bpf/sock_ops_map
Attach:
将已经加载到内核的 sk_msg 程序 attach 到 sockmap,
$ sudo bpftool prog attach pinned /sys/fs/bpf/bpf_redir msg_verdict pinned /sys/fs/bpf/sock_ops_map
从现在开始,sockmap 内的所有 socket 在 sendmsg 时都将触发执行这段 BPF 代码。
查看:
查看系统中已经加载的所有 BPF 程序:
$ sudo bpftool prog show
...
38: sock_ops name bpf_sockmap tag d9aec8c151998c9c gpl
loaded_at 2021-01-28T22:52:06+0800 uid 0
xlated 672B jited 388B memlock 4096B map_ids 13
btf_id 20
43: sk_msg name bpf_redir tag 550f6d3cfcae2157 gpl
loaded_at 2021-01-28T22:52:06+0800 uid 0
xlated 224B jited 156B memlock 4096B map_ids 13
btf_id 24
查看系统中所有的 map,以及 map 详情:
$ sudo bpftool map show
13: sockhash name sock_ops_map flags 0x0
key 24B value 4B max_entries 65535 memlock 5767168B
# -p/--pretty:人类友好格式打印
$ sudo bpftool -p map show id 13
{
"id": 13,
"type": "sockhash",
"name": "sock_ops_map",
"flags": 0,
"bytes_key": 24,
"bytes_value": 4,
"max_entries": 65535,
"bytes_memlock": 5767168,
"frozen": 0
}
打印 map 内的所有内容:
$ sudo bpftool -p map dump id 13
[{
"key":
["0x7f", "0x00", "0x00", "0x01", "0x7f", "0x00", "0x00", "0x01", "0x01", "0x00", "0x00", "0x00", "0x00", "0x00", "0x00", "0x00", "0x03", "0xe8", "0x00", "0x00", "0xa1", "0x86", "0x00", "0x00"
],
"value": {
"error":"Operation not supported"
}
},{
"key":
["0x7f", "0x00", "0x00", "0x01", "0x7f", "0x00", "0x00", "0x01", "0x01", "0x00", "0x00", "0x00", "0x00", "0x00","0x00", "0x00", "0xa1", "0x86", "0x00", "0x00", "0x03", "0xe8", "0x00", "0x00"
],
"value": {
"error":"Operation not supported"
}
}
]
其中的 error 是因为 sockhash map 不支持从用户空间获取 map 内的值(values)。
测试
在一个窗口中启动 socat 作为服务端,监听在 1000 端口:
# start a TCP listener at port 1000, and echo back the received data
$ sudo socat TCP4-LISTEN:1000,fork exec:cat
另一个窗口用 nc 作为客户端来访问服务端,建立 socket:
# connect to the local TCP listener at port 1000
$ nc localhost 1000
观察我们在 BPF 代码中打印的日志:
$ sudo cat /sys/kernel/debug/tracing/trace_pipe
nc-13227 [002] .... 105048.340802: 0: sockmap: op 4, port 50932 --> 1001
nc-13227 [002] ..s1 105048.340811: 0: sockmap: op 5, port 1001 --> 50932
清理
从 sockmap 中 detach 第二段 BPF 程序,并将其从 BPF 文件系统中 unpin:
$ sudo bpftool prog detach pinned /sys/fs/bpf/bpf_redir msg_verdict pinned /sys/fs/bpf/sock_ops_map
$ sudo rm /sys/fs/bpf/bpf_redir
当 BPF 文件系统中某个文件的 reference count 为零时,该就会自动从 BPF 文件系统中删除。
同理,从 cgroups 中 detach 第一段 BPF 程序,并将其从 BPF 文件系统中 unpin:
$ sudo bpftool cgroup detach /sys/fs/cgroup/unified/ sock_ops pinned /sys/fs/bpf/bpf_sockops
$ sudo rm /sys/fs/bpf/bpf_sockops
最后删除 sockmaps:
$ sudo rm /sys/fs/bpf/sock_ops_map
结束语
本文展示了如何利用 sockmap/cgroups BPF 程序加速两端都在同一台机器的 socket 的通 信。下一篇 会给出一些性能测试,有兴趣可以前往查看。
本文翻译自 2020 年的一篇英文博客《 How to use eBPF for accelerating Cloud Native applications 》:
https://cyral.com/blog/how-to-ebpf-accelerating-cloud-native/。
译文链接:
http://arthurchiao.art/blog/socket-acceleration-with-ebpf-zh/
以上是关于利用 eBPF redirection 提升socket性能的主要内容,如果未能解决你的问题,请参考以下文章