聊一聊分布式一致性算法-ZAB协议
Posted 架构漫谈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊一聊分布式一致性算法-ZAB协议相关的知识,希望对你有一定的参考价值。
技术&管理 | 作者 / 鸽子
由于业务开发只需要处理繁杂的业务逻辑,而支撑业务开发的技术难点,都已经封装成组件,开箱即用,申请即可。
大多数情况下,你只需要知道怎么使用这个工具就够了,甚至不需要知道底层实现原理,久而久之,对技术的敏感性越来越低,沦为业务开发工具人,尤其是在大厂,妥妥螺丝钉一枚。
所以,作为技术人员,在做业务开发中,要始终保持技术的敏感性,时刻保持学习的心态,锻炼自己的技术思维和逻辑思维。
从繁杂业务中剥离,梳理自己的知识框架,切换大脑左右空间,针对某一个技术点的梳理,也许会对业务开拓、团队管理、项目管理提供一些新思路。
回归今天主题,梳理下分布式一致性算法-ZAB协议的来龙去脉。
为什么需要一致性
-
数据不能存在单个节点(主机)上,否则可能出现单点故障。
-
-
分布式一致性算法包括:Paxos、Raft、ZAB、Gossip
一致性的分类
-
-
-
说明:也叫最终一致性,系统不保证改变提交以后立即改变集群的状态,但是随着时间的推移最终状态是一致的。
-
一致性算法实现举例
-
Google的Chubby分布式锁服务,采用了Paxos算法
-
-
ZooKeeper分布式应用协调服务,Chubby的开源实现,采用ZAB算法
今天来聊一聊zookeeper一致性算法实现-ZAB协议的来龙去脉。
整个zookeeper就是一个多节点分布式一致性算法的实现,底层采用的实现协议是ZAB。
ZAB协议介绍
ZAB协议全称:Zookeeper Atomic Broadcast(Zookeeper原子广播协议)。
Zookeeper 是一个为分布式应用提供高效且可靠的分布式协调服务。在解决分布式一致性方面,Zookeeper并没有使用 Paxos,而是采用了 ZAB协议,ZAB是Paxos算法的一种简化实现。
ZAB协议定义:ZAB协议是为分布式协调服务 Zookeeper专门设计的一种支持 崩溃恢复 和 原子广播 的协议。下面我们会重点讲这两个东西。
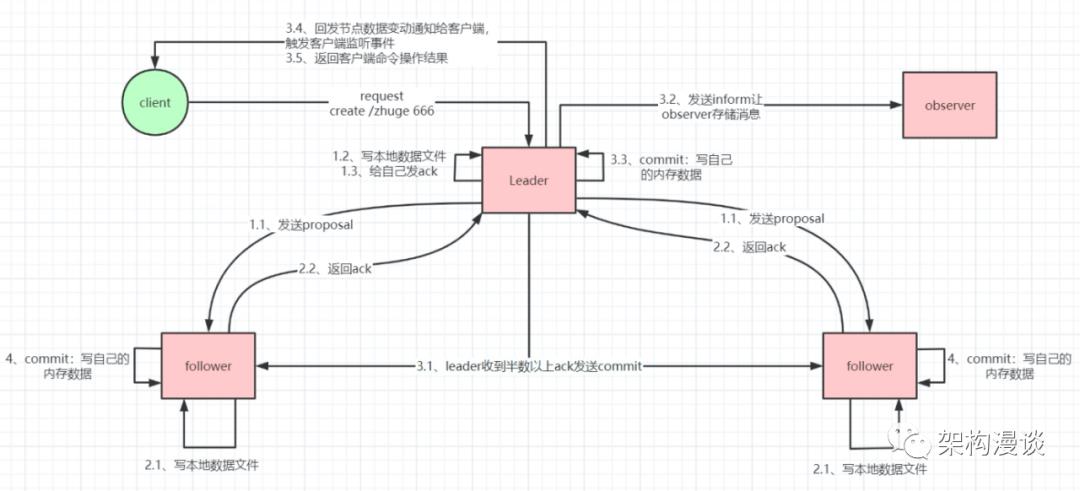
基于该协议,Zookeeper实现了一种 主备模式 的系统架构来保持集群中各个副本之间数据一致性。具体如下图所示:
上图显示了 Zookeeper如何处理集群中的数据。所有客户端写入数据都是写入到Leader节点,然后,由 Leader复制到Follower节点中,从而保证数据一致性。
那么复制过程又是如何的呢?复制过程类似两阶段提交(2PC),ZAB只需要 Follower(含leader自己的ack)有一半以上返回 Ack信息就可以执行提交,大大减小了同步阻塞。也提高了可用性。
简单介绍完,开始重点介绍 消息广播 和 崩溃恢复。整个 Zookeeper就是在这两个模式之间切换。简而言之,当Leader服务可以正常使用,就进入消息广播模式,当 Leader不可用时,则进入崩溃恢复模式。
消息广播
ZAB协议的消息广播过程使用的是一个原子广播协议,类似一个 两阶段提交过程。对于客户端发送的写请求,全部由 Leader接收,Leader将请求封装成一个事务 Proposal,将其发送给所有 Follwer,然后,根据所有 Follwer的反馈,如果超过半数(含leader自己)成功响应,则执行 commit操作。
1、Leader在收到客户端请求之后,会将这个请求封装成一个事务,并给这个事务分配一个全局递增的唯一ID,称为事务ID(ZXID),ZAB协议需要保证事务的顺序,因此必须将每一个事务按照 ZXID进行先后排序,然后处理,主要通过消息队列实现。
2、在 Leader和 Follwer之间还有一个消息队列,用来解耦他们之间的耦合,解除同步阻塞。
3、zookeeper集群中为保证任何所有进程能够有序的顺序执行,只能是 Leader服务器接受写请求,即使是Follower服务器接受到客户端的写请求,也会转发到 Leader服务器进行处理,Follower只能处理读请求。
4、ZAB协议规定了如果一个事务在一台机器上被处理(commit)成功,那么应该在所有的机器上都被处理成功,哪怕机器出现故障崩溃。
崩溃恢复
刚刚我们说消息广播过程中,Leader†崩溃怎么办?还能保证数据一致吗?
实际上,当 Leader崩溃,即进入我们开头所说的崩溃恢复模式(崩溃即:Leader失去与过半 Follwer的联系)。下面来详细讲述。
假设1:Leader在复制数据给所有 Follwer之后,还没来得及收到Follower的ack返回就崩溃,怎么办?
假设2:Leader在收到 ack并提交了自己,同时发送了部分 commit出去之后崩溃怎么办?
1、ZAB协议确保丢弃那些只在 Leader提出/复制,但没有提交的事务。
2、ZAB协议确保那些已经在 Leader提交的事务最终会被所有服务器提交。
能够确保提交已经被 Leader提交的事务,同时丢弃已经被跳过的事务。
针对这个要求,如果让 Leader选举算法能够保证新选举出来的 Leader服务器拥有集群中所有机器 ZXID最大的事务,那么就能够保证这个新选举出来的 Leader一定具有所有已经提交的提案。
而且这么做有一个好处是:可以省去 Leader服务器检查事务的提交和丢弃工作的这一步操作。
数据同步
当崩溃恢复之后,需要在正式工作之前(接收客户端请求),Leader服务器首先确认事务是否都已经被过半的Follwer提交了,即是否完成了数据同步。目的是为了保持数据一致。
当 Follwer服务器成功同步之后,Leader会将这些服务器加入到可用服务器列表中。
实际上,Leader服务器处理或丢弃事务都是依赖着 ZXID的,那么这个 ZXID如何生成呢?
答:在 ZAB协议的事务编号 ZXID设计中,ZXID是一个 64位的数字,其中低 32位可以看作是一个简单的递增的计数器,针对客户端的每一个事务请求,Leader都会产生一个新的事务 Proposal并对该计数器进行 +1操作。
而高 32†位则代表了 Leader服务器上取出本地日志中最大事务 Proposal的 ZXID,并从该 ZXID中解析出对应的epoch值(leader选举周期),当一轮新的选举结束后,会对这个值加一,并且事务id又从0开始自增。
高 32位代表了每代 Leader的唯一性,低 32代表了每代 Leader中事务的唯一性。同时,也能让 Follwer通过高32位识别不同的 Leader。简化了数据恢复流程。
基于这样的策略:当 Follower连接上 Leader之后,Leader服务器会根据自己服务器上最后被提交的 ZXID和Follower上的 ZXID进行比对,比对结果要么回滚,要么和 Leader同步。
我是鸽子,一名互联网的从业者,现任阿里巴巴集团,新零售技术事业群,技术专家,这里打个广告,如果你也有意愿想来阿里闯一下的话,不妨私信我,甩个简历过来,我们共同学习,共同进步。
邮箱:chenge.wcg@alibaba-inc.com
以上是关于聊一聊分布式一致性算法-ZAB协议的主要内容,如果未能解决你的问题,请参考以下文章
ZAB协议与Paxos算法
Zookeeper协议篇-Paxos算法与ZAB协议
Zookeeper协议篇-Paxos算法与ZAB协议
Zab协议:Zookeeper一致性协议
直观理解:Zookeeper分布式一致性协议ZAB
Paxos算法 ZAB协议