缓存系统稳定性 - 架构师峰会演讲实录
Posted gocloudcoder
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了缓存系统稳定性 - 架构师峰会演讲实录相关的知识,希望对你有一定的参考价值。
前言
首先,大家可以想一想:我们在流量激增的情况下,服务端哪个部分最有可能会是第一个瓶颈?我相信大部分人遇到的都会是数据库首先扛不住,量一起来,数据库慢查询,甚至卡死。此时,上层服务有怎么强的治理能力都是无济于事的。
所以我们常说看一个系统架构设计的好不好,很多时候看看缓存设计的如何就知道了。我们曾经遇到过这样的问题,在我加入之前,我们的服务是没有缓存的,虽然当时流量还不算高,但是每天到流量高峰时间段,大家就会特别紧张,一周宕机好几回,数据库直接被打死,然后啥也干不了,只能重启;我当时还是顾问,看了看系统设计,只能救急,就让大家先加上了缓存,但是由于大家对缓存的认知不够以及老系统的混乱,每个业务开发人员都会按照自己的方式来手撕缓存。这样导致的问题就是缓存用了,但是数据七零八落,压根没有办法保证数据的一致性。这确实是一个比较痛苦的经历,应该能引起大家的共鸣和回忆。
然后我把整个系统推倒重新设计了,其中缓存部分的架构设计在其中作用非常明显,于是有了今天的分享。
我主要分为以下几个部分跟大家探讨:
-
缓存系统常见问题 -
单行查询的缓存与自动管理 -
多行查询缓存机制 -
分布式缓存系统设计 -
缓存代码自动化实践
缓存系统涉及的问题和知识点是比较多的,我分为以下几个方面来讨论:
-
稳定性 -
正确性 -
可观测性 -
规范落地和工具建设
由于篇幅太长,本文作为系列文章第一篇,主要跟大家探讨『缓存系统稳定性』
缓存系统稳定性
缓存稳定性方面,网上基本所有的缓存相关文章和分享都会讲到三个重点:
-
缓存穿透 -
缓存击穿 -
缓存雪崩
为什么首先讲缓存稳定性呢?大家可以回忆一下,我们何时会引入缓存?一般都是当DB有压力,甚至经常被打挂的情况下才会引入缓存,所以我们首先就是为了解决稳定性的问题而引入缓存系统的。
缓存穿透
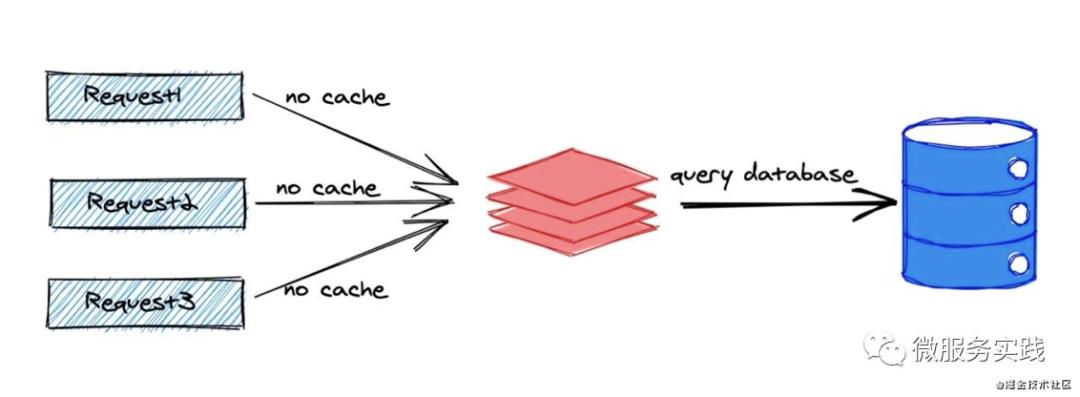
缓存穿透存在的原因是请求不存在的数据,从图中我们可以看到对同一个数据的请求1会先去访问缓存,但是因为数据不存在,所以缓存里肯定没有,那么就落到DB去了,对同一个数据的请求2、请求3也同样会透过缓存落到DB去,这样当大量请求不存在的数据时DB压力就会特别大,尤其是可能会恶意请求打垮(不怀好意的人发现一个数据不存在,然后就大量发起对这个不存在数据的请求)。
go-zero 的解决方法是:对于不存在的数据的请求我们也会在缓存里短暂(比如一分钟)存放一个占位符,这样对同一个不存在数据的DB请求数就会跟实际请求数解耦了,当然在业务侧也可以在新增数据时删除该占位符以确保新增数据可以立刻查询到。
缓存击穿
缓存击穿的原因是热点数据的过期,因为是热点数据,所以一旦过期可能就会有大量对该热点数据的请求同时过来,这时如果所有请求在缓存里都找不到数据,如果同时落到DB去的话,那么DB就会瞬间承受巨大的压力,甚至直接卡死。
go-zero 的解决方法是:对于相同的数据我们可以借助于 core/syncx/SharedCalls 来确保同一时间只有一个请求落到DB,对同一个数据的其它请求等待第一个请求返回并共享结果或错误,根据不同的并发场景,我们可以选择使用进程内的锁(并发量不是非常高),或者分布式锁(并发量很高)。如果不是特别需要,我们一般推荐进程内的锁即可,毕竟引入分布式锁会增加复杂度和成本,借鉴奥卡姆剃刀理论:如非必要,勿增实体。
我们来一起看一下上图缓存击穿防护流程,我们用不同颜色表示不同请求:
-
绿色请求首先到达,发现缓存里没有数据,就去DB查询 -
粉色请求到达,请求相同数据,发现已有请求在处理中,等待绿色请求返回,singleflight模式 -
绿色请求返回,粉色请求用绿色请求共享的结果返回 -
后续请求,比如蓝色请求就可以直接从缓存里获取数据了
缓存雪崩
缓存雪崩的原因是大量同时加载的缓存有相同的过期时间,在过期时间到达的时候出现短时间内大量缓存过期,这样就会让很多请求同时落到DB去,从而使DB压力激增,甚至卡死。
比如疫情下在线教学场景,高中、初中、小学是分几个时间段同时开课的,那么这时就会有大量数据同时加载,并且设置了相同的过期时间,在过期时间到达的时候就会对等出现一个一个的DB请求波峰,这样的压力波峰会传递到下一个周期,甚至出现叠加。
go-zero 的解决方法是:
-
使用分布式缓存,防止单点故障导致的缓存雪崩 -
在过期时间上加上5%的标准偏差,5%是假设检验里P值的经验值(有兴趣的读者可以自行查阅)
我们做个实验,如果用1万个数据,过期时间设为1小时,标准偏差设为5%,那么过期时间会比较均匀的分布在3400~3800秒之间。如果我们的默认过期时间是7天,那么就会均匀分布在以7天为中心点的16小时内。这样就可以很好的防止了缓存的雪崩问题。
未完待续
本文跟大家一起讨论了缓存系统的常见稳定性问题,下一篇我来跟大家一起分析缓存的数据一致性问题。
所有这些问题的解决方法都已包含在 go-zero 微服务框架里,如果你想要更好的了解 go-zero 项目,欢迎前往官方网站上学习具体的示例。
项目地址
https://github.com/tal-tech/go-zero
欢迎使用 go-zero 并 star 支持我们!
以上是关于缓存系统稳定性 - 架构师峰会演讲实录的主要内容,如果未能解决你的问题,请参考以下文章