Hive SQL的底层编译过程详解
Posted 五分钟学大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive SQL的底层编译过程详解相关的知识,希望对你有一定的参考价值。
本文结构采用宏观着眼,微观入手,从整体到细节的方式剖析 Hive SQL 底层原理。第一节先介绍 Hive 底层的整体执行流程,然后第二节介绍执行流程中的 SQL 编译成 MapReduce 的过程,第三节剖析 SQL 编译成 MapReduce 的具体实现原理。
Hive
本文首发于公众号【五分钟学大数据】,公众号内可免费查看!
Hive是什么?Hive 是数据仓库工具,再具体点就是一个 SQL 解析引擎,因为它即不负责存储数据,也不负责计算数据,只负责解析 SQL,记录元数据。
Hive直接访问存储在 HDFS 中或者 HBase 中的文件,通过 MapReduce、Spark 或 Tez 执行查询。
我们今天来聊的就是 Hive 底层是怎样将我们写的 SQL 转化为 MapReduce 等计算引擎可识别的程序。了解 Hive SQL 的底层编译过程有利于我们优化Hive SQL,提升我们对Hive的掌控力,同时有能力去定制一些需要的功能。
Hive 底层执行架构
我们先来看下 Hive 的底层执行架构图, Hive 的主要组件与 Hadoop 交互的过程:
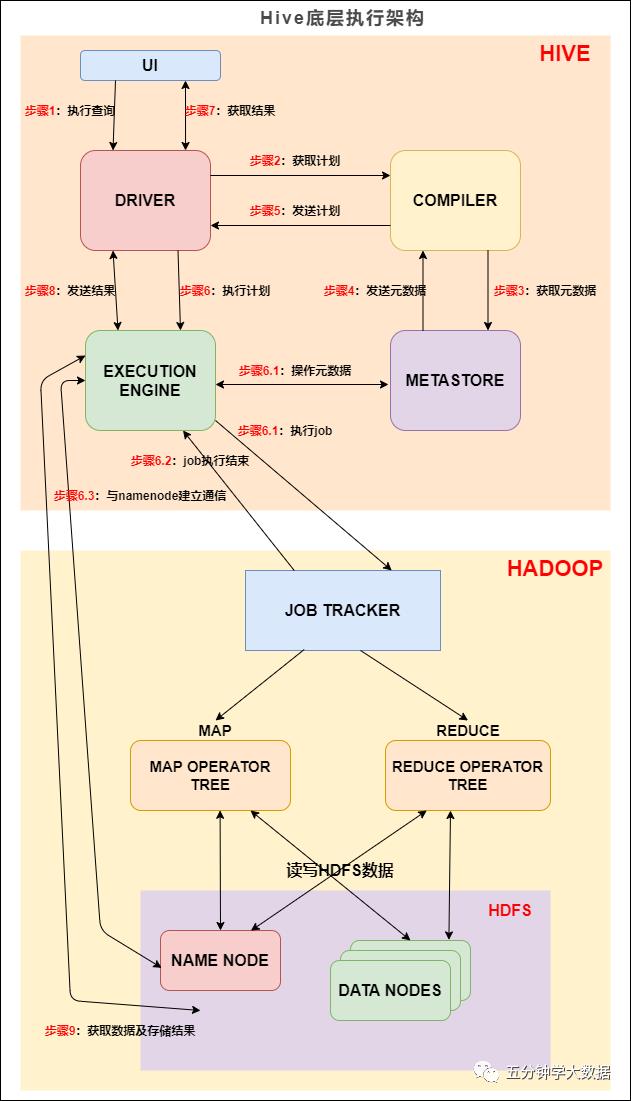
公众号【五分钟学大数据】内可免费查看此文章
以上是关于Hive SQL的底层编译过程详解的主要内容,如果未能解决你的问题,请参考以下文章