分页场景慢?MySQL的锅!
Posted 数据库开发
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分页场景慢?MySQL的锅!相关的知识,希望对你有一定的参考价值。
牛牛六年前刚工作的时候,发现分页场景下,当offset变大,mysql处理速度非常慢!具体sql如下:
select * from t_record where age > 10 offset 10000 limit 10
下表所示为表t_record结构,为了简单起见,只列了我们将讨论的字段,其余字段省略。
其中t_record是要查询的数据表,表中一共有50000条记录,age字段上有索引,且age>10的记录有20000条。
这条语句非常慢,基本达到了秒级延迟,在第二次请求有缓存之后,才变快。
在数据量这么少的情况下,走索引还这么慢,这完全不能接受,我就问我导师为什么,他反问“
索引场景,MySQL中获得第n大的数,时间复杂度是多少?
”
小白直觉作答
当时只知道MySQL索引使用的是树,瞎猜了个O(logn)
,心想二叉树找一个节点不就是O(logn)么。自然而然,导师白了一眼,让我自己去研究。
继续解答
想来想去...只能从底层结构分析了,MySQL的索引是B+树。仔细想一下,就会发现通过索引去找很别扭。因为你不知道前n个数在其他子树的分布情况,也没有标记让你能快速选择去哪个子树寻找,我们无法利用B+树分支过滤的查找特性。
这下我明白导师的用意了——
offset n,就是从第n大的数开始找
!第n大的数没法使用树分支查找,所以offset,也不能!
select * from t_record where age > 10 offset 10000 limit 10
通过二级索引age,我们只能找到对应的起始节点,但无法通过树结构过滤掉10000个节点,再获取10个节点,因为我们无法知道某个子树下有多少数据,就无法通过分支进行排除。
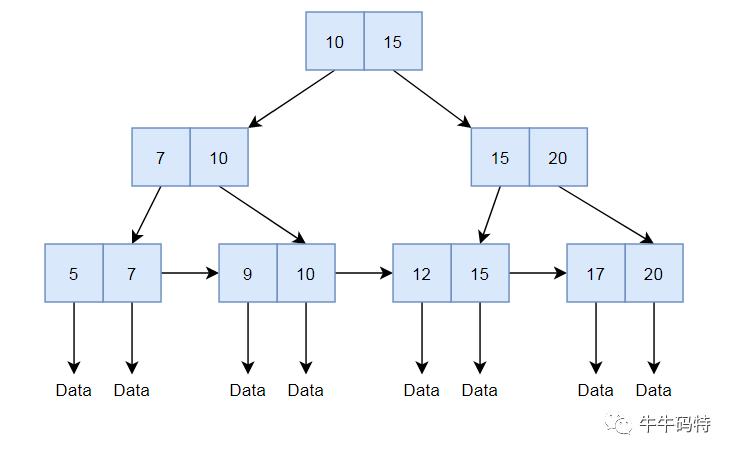
我们来仔细看下B+树的结构,它不光有常规树的分支结构,底部还有一个由叶子节点组成链表。
显而易见,最方便最快的方式,就是用树定位到起始位置,然后直接通过叶子节点组成的链表,以O(n)的复杂度找到第n大的数据。
回到我们最初的问题,总结一下:问题的本质其实就是让offset找到第n大的数,再通过链表遍历,在数据量很大的情况下,确实会慢。
但是即使是O(n),也不至于仅有几万数据就慢得令人发指。
这里推荐两本书,一本《MySQL技术内幕 InnoDB存储引擎》,通过它可以对InnoDB的底层机制,如acid、mvcc、索引实现、文件存储,有更深的理解。

第二本是《高性能MySQL》,这本书从使用层面着手,讲得比较深入,并提到了很多设计和优化的思路,对日常工作和学习都有很大的帮助。

两本书相结合,反复领会,MySQL就差不多能登堂入室了。
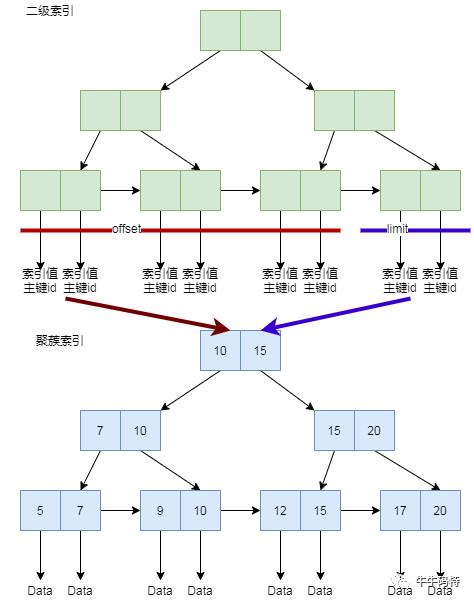
如图所示,offset会先从二级索引的链表顺序找10000个节点。
注意,即使这10000个节点会被扔掉,MySQL也会通过二级索引上的主键id,去聚簇索引上查一遍数据,这可是10000次随机IO,自然慢成哈士奇。
大家读到这里可能会提出疑问,为什么MySQL会有这种行为?
这和它的优化器有关系,也算是MySQL的一个大坑,时至今日,也没有优化。
针对分页性能问题,《高性能MySQL》中提到了两种方案,让我们一起来看看:
方案一:产品上绕过
根据业务实际需求,看能否替换为上一页、下一页的功能,这样子就可以通过和上次返回数据进行比较,搭上树分支过滤的便车。
特别在ios,android端,以前那种完全的分页是不常见的。
即转换为如下sql,第一次last_id传0即可。
select * from t_record where id > last_id limit 10
1.能利用树的分支结构,过滤掉第n个数之前的数据集;
2.直接通过主键索引查找,省略了二级索引查找过程,性能会更高。
1.使用场景其实是受限制的。比如,如果是针对age字段有条件判断,再分页,那么使用主键id查找就不满足需求;
2.把主键id暴露出去了,这个本身不应该是业务层面关心的字段。
因为我们还有age做过滤条件,此时用大于主键id的方式,虽然看起来变成顺序IO了,但由于是根据主键id排列来寻找,而不是根据需要的age索引,所以会导致MySQL去查更多的数据。虽然不符合我们案例的需求,但还是来看看优缺点:
方案二:正面刚
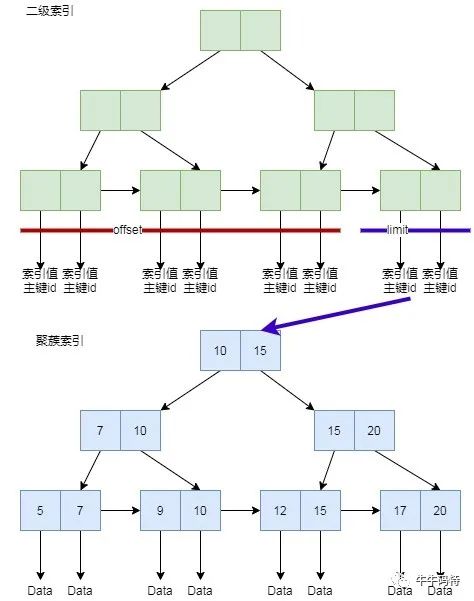
索引覆盖
:当辅助索引查询的数据只有主键id和辅助索引本身,那么就不必再去查聚簇索引。
select * from t_record id in(select id from t_record where age > 10 offset 10000 limit 10)
这句话是说,先从条件查询中,查找数据对应的数据库唯一id值,因为主键在辅助索引上就有,所以不用回归到聚簇索引的磁盘上拉取。
如此以来,offset部分均不需要去反查聚蔟索引,只有limit出来的10个主键id会去查询聚簇索引,这样只会十次随机IO。
在业务确实需要用分页的情况下,使用该方案可以大幅度提高性能。通常能满足性能要求。
1.维持了分页需求,适用所有limit offset场景,大大减少随机IO,提高了性能;
二级索引上还是会走下面的链表来遍历,这部分时间复杂度还是O(n)。
方案选型
如果产品本身的需求,是分上下页,且没用其他过滤条件,可以用方案一。
方案二更具有普适性,同时由于合理分表的大小,一般也就500w,二级索引上O(n)的查找损耗,通常也在可接受范围。
从一个小问题,往下深究,不仅可以深入理解这个问题,在面试和工作中大放异彩,同时在探索的过程中,自身的知识储备也能得到拓展,是技术的一个提升捷径。祝大家工作顺利,牛牛码特!
--- EOF ---
以上是关于分页场景慢?MySQL的锅!的主要内容,如果未能解决你的问题,请参考以下文章