阅读 Git 代码,提升你的编程技能
Posted freeCodeCamp
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阅读 Git 代码,提升你的编程技能相关的知识,希望对你有一定的参考价值。
现今有很多时新的方法可以帮你提升编程知识和技能,比如:
-
参加一个免费或付费的在线编程课程 -
读一本编程书 -
选择一个个人项目,通过编写代码来动手学习 -
跟随一个在线教程项目去学 -
多关注一些编程博客的最新动态并保持同步
每一种方法都会吸引不同的人,并且每种方法里都有些东西肯定会使你成为一个更好的程序员。如果你是一个中级或高级程序员,那几乎可以肯定这里的每种方法你已经尝试了至少一次。
但是,绝大多数开发人员都忽略了另一种方法,我认为这很可惜,因为它可以学到很多东西。这种方法就是通过阅读、分析和理解现有的高质量代码库来学习!
我们很幸运地生活在这样一个经常可以通过高质量、免费和开源(FOSS)项目免费访问优质代码的时代, 而且从 GitHub 或 BitBucket 之类的网站上将这些代码库的副本克隆到我们的本地计算机上,只需不到一分钟的时间。
此外,像 Git 这样的现代版本控制系统让我们可以查看软件开发历史中任意节点的代码。显然,我们眼前能看到大量丰富的信息!
在本文中,我们将讨论 Git 代码的原始版本,以分析如何通过阅读现有代码帮助提升你的编程技能。
我们将介绍为什么有关 Git 的代码值得学习,如何访问 Git 的代码以及回顾一些相关的 C 语言编程概念。
我们将概述 Git 的原始代码库结构,并学习如何在代码中实现 Git 的核心功能。
最后,我们将为好奇的开发人员推荐一些后续步骤,以便他们继续从 Git 的代码和其他项目中学习。
为什么要学习关于 Git 的代码呢?
对于中级开发人员来说,Git 的代码库是用来进一步提高他们的编程知识和技能的一个极好资源。以下是 Git 代码值得深入研究的 7 个原因:
-
Git 可能是当今使用的最受欢迎的软件开发工具。简而言之,如果你是开发人员,则可能会使用 Git。学习 Git 的代码如何工作将使你对每天使用的基本工具有更深入的了解。
-
Git 很有趣!Git 是一种多功能工具,可以解决许多有趣的问题,能帮助开发人员在代码上进行协作。作为一个好奇的人,我非常喜欢学习更多有关它的知识。
-
Git 的代码是用 C 语言编写的,这给开发人员提供了一个很好的机会,使他们可以了解一种以前可能很少使用的重要语言。
-
Git 利用了许多重要的编程概念,包括 内容寻址数据库、文件压缩/解压缩、哈希函数、缓存 和 简单数据模型 。Git 的代码说明了如何在实际项目中实现这些概念。
-
Git 的代码和设计非常优雅。这是一个功能强大的极简代码库的一个很好的示例,它可以清晰有效地实现其目标。
-
Git 的初始提交代码很小,它仅由 10 个文件组成,总共包含少于 1,000 行代码。与大多数其他项目相比这是非常小的,并且理解起来不会花费很多时间。
-
Git 的初始提交代码可以成功编译和执行。这意味着你可以使用并测试 Git 代码的原始版本,以了解其工作原理。
现在,让我们看一看要如何访问 Git 代码的原始版本。
如何查看 Git 的初始提交代码呢?
Git 代码库的正式副本托管在 GitHub 公开仓库中。但是,我创建了 Git 代码库的一个分支,并在源码中添加了大量的行内注释以帮助开发人员轻松地逐行阅读它。
由于这是我 Git 历史上的第一次提交,所以我把项目命名为 Baby Git。Baby Git 的代码库托管在 BitBucket 公开仓库 中。
我建议通过在终端中运行以下命令将 Baby Git 代码库克隆到你的本地计算机:
git clone https://bitbucket.org/jacobstopak/baby-git.git
如果你想坚持使用 Git 的原始代码库(即无需我所添加的大量注释),请改用以下命令:
git clone https://github.com/git/git.git
通过运行命令 cd git 跳转到新生成的 git 目录,随意浏览下里面的文件夹和文件。
你会很快注意到,在工作目录检出的 Git 当前版本代码中,有大量的文件并且包含许多非常长看起来很复杂的代码。
显然当前的 Git 版本代码库太大了,很难让单个开发人员在短时间内熟悉它。
让我们使用以下命令检出 Git 的初始提交代码来简化这事情:
git log --reverse
列表逆序(即与最新日期在前相反)显示了从 Git 第一次提交代码到现在的提交日志。列表里第一次提交的 ID 是 e83c5163316f89bfbde7d9ab23ca2e25604af290。
通过运行命令以下命令把第一次提交的内容检出到你的工作目录:
git checkout e83c5163316f89bfbde7d9ab23ca2e25604af290
这会让 Git 进入 分离头指针状态 ,并把 Git 的源代码检出到你的工作目录。
现在运行 ls 命令列出所有文件,注意里面只有 10 个文件真正包含代码(第 11 个只是 README)。中级开发人员完全可以理解这些文件中的代码。
注意: 如果你使用的是 Baby Git 仓库,则需要运行命令 git checkout master 来放弃分离的头部,然后移回 master 分支。这将使你能够查看所有描述 Git 的代码如何逐行工作的行内注释!
一些重要的 C 语言概念将帮助你理解 Git 的代码
在深入研究 Git 的代码之前,重新了解整个代码库中出现的一些 C 语言编程概念会对你有所帮助。
C 语言头文件
C 语言头文件是一个扩展名为 .h 的代码文件。头文件用于存储开发人员希望使用 #include "headerFile.h" 指令将其包括在多个 .c 源代码文件中的变量,函数和其他 C 语言对象。
如果你熟悉用 Python 或 Java 导入文件,那么这是一个类似的过程。
C 语言函数原型(或函数签名)
一个函数原型或签名告诉 C 语言编译器有关函数定义的信息 —— 函数名称、参数数量、参数类型和返回值类型,但无需提供函数体。它们帮助 C 语言编译器在有函数体的情况下调用函数识别函数属性。
下面是一个关于函数原型的例子:
int multiplyNumbers(int a, int b);
C 语言的宏
C 语言中的宏本质上是一个基本变量,在 C 语言程序中的代码编译之前先进行处理。宏是使用 #define 指令创建的,例如:
#define TESTMACRO asdf
这将创建一个名为 TESTMACRO 的宏,其值为 asdf。在代码中使用占位符 TESTMACRO 的任何地方,它将被预处理器(在代码编译之前)替换为值 asdf。
宏通常在以下几种情况使用:
-
作为一个 true/false 的开关检查宏是否定义 -
替换在代码中的多个位置出现的简单整数或字符串值 -
替换在代码中的多个位置出现的简单(通常为单行)代码段
宏是方便的工具,因为它们使开发人员可以更新一行代码影响代码在多个位置的行为。
C 语言结构体
C 语言中的结构体是一组属性的集合组成的单个对象。
你可能熟悉 Java 和 Python 等语言中的类,结构体其实就是类的前身,它可以被看作是一个不包含方法的原始类。
struct person {
int person_id;
char *first_name;
char *last_name;
};
上面这个结构体代表一个由 ID 属性、名字属性、姓氏属性组成的人,可以通过以下方式实例化和初始化一个变量:
struct person jacob = { 1, "Jacob", "Stopak" };
结构体属性取值通过 . 操作完成:
jacob.person_id
jacob.first_name
jacob.last_name
C 语言中的指针
可以使用 & 符号获取指向现有变量的指针,并将其存储在以 * 符号声明的指针变量中:
int age = 21;
int* age_pointer = &age;
int new_age = *age_pointer + 10;
现在我们对 C 语言的简单回顾就完成了,让我们回到 Git 的代码吧!
Git 代码库结构概述
Git 初次提交的代码由 10 个相关的代码文件组成,让我们简要从下面两个文件开始讨论:
-
Makefile -
cache.h
我们首先讨论 Makefile 和 cache.h,因为它们有一点点特殊。
Makefile 是一个构建文件,其中包含一组用于将其他源代码文件构建为可执行文件的命令。
当你从命令行运行 make all 命令时,这个 Makefile 文件将会编译源代码并生成 Git 命令的相关可执行文件。如果你感兴趣,我写了一份 深入了解 Git 构建的指南。
注意 如果你确实像我推荐的那样想在本地编译 Git 的源码,那么你需要使用上面我提到的版本 Baby Git,因为我做了一些调整让 Git 的源代码可以在现代操作系统上编译。
接下来是 cache.h 文件,这是 Baby Git 唯一的头文件。如上所述,头文件定义了剩下 .c 源代码文件中使用的许多函数签名、结构体、宏以及其他设置。如果你感到好奇,我写了一篇 深入了解 Git 头文件的指南。
其余 8 个代码文件都是 .c 源代码文件:
-
init-db.c -
update-cache.c -
read-cache.c -
write-tree.c -
commit-tree.c -
read-tree.c -
cat-file.c -
show-diff.c
每个文件(read-cache.c 除外)均以包含该代码的 Git 命令命名,你可能对其中的某些文件很熟悉。比如 init-db.c 文件包含用于初始化新 Git 仓库的 init-db 命令的代码。你可能已经猜到了,这是 git init 命令的前身。
实际上每个 .c 文件(read-cache.c 除外)都包含原始的 8 个 Git 命令之一的代码,构建过程将编译每个文件并为每个文件创建一个可执行文件(具有匹配的名称)。将这些可执行文件添加到文件系统路径后,即可像执行任何现代 Git 命令一样执行它们。
因此使用 make all 命令编译代码后,将生成以下可执行文件:
-
init-db:初始化一个新的 Git 仓库,相当于git init -
update-cache:添加一个新文件到暂存区,相当于git add -
write-tree:根据当前索引内容在 Git 仓库中创建树对象(即目录结构) -
commit-tree:在 Git 仓库中创建一个新的提交对象。相当于git commit -
read-tree:从 Git 仓库中打印出树(即目录结构)的内容 -
cat-file:从 Git 仓库中检索对象的内容,并将其存储在当前目录中的临时文件中。相当于git show -
show-diff:显示索引中暂存的文件与文件系统中存在的这些文件的当前版本之间的差异。相当于git diff。
这些命令按顺序分别执行,类似于现代 Git 命令作为标准开发工作流程的一部分执行的方式。
我们尚未讨论的一个文件是 read-cache.c。该文件包含一组其他 .c 源代码文件用于从 Git 仓库中检索信息的辅助函数。
现在我们已经接触到了 Git 最初提交中的每个重要文件,让我们讨论一些让 Git 起作用的核心编程概念。
Git 核心概念的实现
在这部分中,我们将讨论 Git 用于实现其魔力的以下编程概念,以及它们在 Git 的原始代码中是如何实现的:
-
文件压缩 -
哈希函数 -
Git 对象 -
当前目录缓存(暂存区) -
内容寻址数据库(对象数据库)
文件压缩
文件压缩(也称为缩放)用于 Git 中的存储和提高性能。当 Git 需要通过网络传输这些文件时,这会减小 Git 存储在磁盘上文件的大小并提高数据检索的速度。
这很重要,因为 Git 的本地和网络操作需要尽可能快。作为数据检索过程的一部分,Git 对文件进行解压缩或扩展以获取其内容。
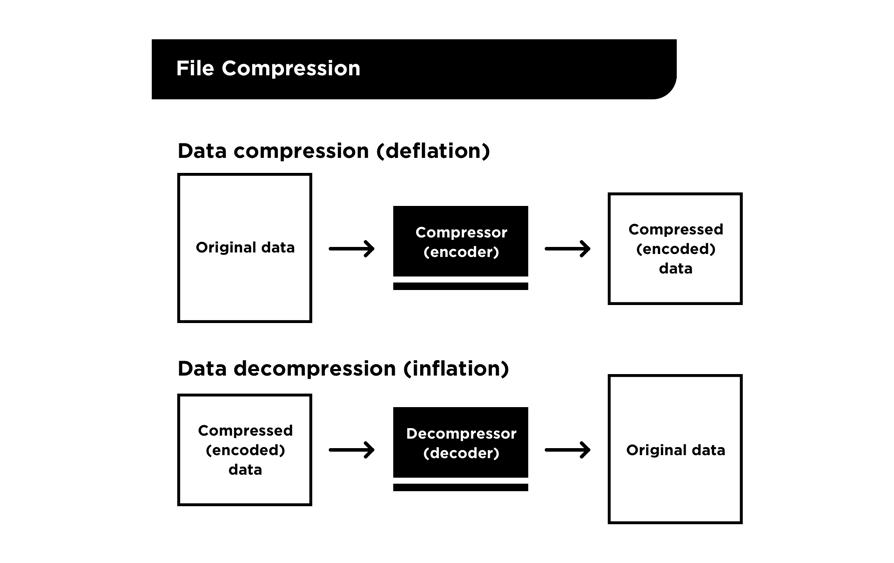
Source: https://initialcommit.com/blog/Learn-Git-Guidebook-For-Developers-Chapter-2
在 Git 的原始代码中使用流行的 zlib.h C 语言库实现了文件压缩和解压缩,该库包含用于压缩和解压缩内容的函数、结构体和属性。具体来说,Zlib 库定义了一个结构体 z_stream 用于保存要压缩或扩展的内容。
下面的 zlib 库函数用于初始化一个流以进行压缩和解压缩,它们分别是:
/*
* Initializes the internal `z_stream` state
* for compression at `level`, which indicates
* scale of speed versuss compression on a
* scale from 0-9. Sourced from <zlib.h>.
*/
deflateInit(z_stream, level);
/*
* Initializes the internal `z_stream` state for
* decompression. Sourced from <zlib.h>.
*/
inflateInit(z_stream);
下面的 zlib 库函数用于执行实际的压缩和解压缩操作
/*
* Compresses as much data as possible and stops
* when the input buffer becomes empty or the
* output buffer becomes full. Sourced from <zlib.h>.
*/
deflate(z_stream, flush);
/*
* Decompresses as much data as possible and stops
* when the input buffer becomes empty or the
* output buffer becomes full. Sourced from <zlib.h>.
*/
inflate(z_stream, flush);
实际的压缩、解压缩过程要比这复杂得多,并且涉及设置压缩流的几个参数,但是我们在这里不做更多详细介绍。
接下来,我们将讨论哈希函数的概念以及如何在 Git 的源代码中实现它们。
哈希函数
哈希函数是一种可以轻松将输入转换为唯一输出但反转该操作非常困难或不可能的函数。换句话说,它是一种 单向函数,在当今的技术下不可能使用哈希函数的输出来推断用于生成该输出的输入。
Git 使用哈希函数,特别是用 SHA-1 哈希函数为我们让 Git 跟踪的文件生成唯一标识符。
作为开发人员,我们使用文本编辑器对正在使用的代码库中的代码文件进行更改,并在某些时候告诉 Git 跟踪这些更改。此时,Git 使用这些文件更改信息作为哈希函数的输入。
哈希函数的输出称为一个 哈希值。哈希值是一个长度为 40 个字符的十六进制值数,例如 47a013e660d408619d894b20806b1d5086aab03b。
Source: https://initialcommit.com/blog/Learn-Git-Guidebook-For-Developers-Chapter-2
Git 将这些哈希值用于各种目的,我们将在以下各节中看到它们。
Git 对象
Git 使用简单数据模型(一个结构化的相关对象集)来实现其功能。这些对象是信息块,这些信息块使 Git 能够跟踪对代码库文件的更改。Git 使用的三种对象类型是:
-
数据对象 -
树对象 -
提交对象
让我们按顺序逐个讨论。
Blob
数据对象
Blob 是 Binary Large OBject(数据对象)的缩写形式,当使用 update-cache <filename.ext> 命令(git add 的前身)告诉 Git 跟踪文件时,Git 使用该文件的压缩内容创建一个新的数据对象。
Git 获取文件的内容并使用我们上面描述的 zlib 函数对其进行压缩,再将此压缩后的内容用作 SHA-1 哈希函数的输入,这会创建一个 40 个字符的哈希,Git 会使用该哈希来识别相关的数据对象。
最后,Git 将数据对象作为二进制文件保存在名为 对象数据库 的特殊文件夹中(稍后会详细介绍)。数据对象文件的名称是生成的哈希,数据对象文件的内容是使用 update-cache 命令添加的压缩文件内容。
树对象
树对象用于把多个数据对象在添加到 Git 的时候就组织到一起,它们还用于将数据对象与文件名(以及其他文件元数据,如权限)相关联,因为数据对象除了提供哈希和压缩的二进制文件内容外不提供任何信息。
比如说,如果使用 update-cache 命令添加了两个更改的文件,则将创建一棵包含这些文件的哈希值以及每个数据对象所对应的文件名的树。
Git 接下来要做的事情非常有趣,因此请注意, Git 使用 树本身的内容 作为 SHA-1 哈希函数的输入生成 40 个字符的哈希。该哈希用于标识树对象,Git 将其保存在与保存数据对象相同的特殊文件夹,即我们将在稍后讨论的对象数据库中。
提交对象
比起数据对象和树对象,你可能对提交对象更熟悉。一个提交对象表示由 Git 保存的一组文件更改,以及有关更改的描述性信息,例如提交消息,作者的姓名和提交的时间戳。
在 Git 的源代码中,提交对象是运行 commit-tree <tree-hash> 命令的结果,生成的提交对象包括指定的树对象(记住,该树对象表示通过映射到其文件名的一个或多个数据对象表示文件更改的集合),以及上一段中提到的描述性信息。
像数据对象和树对象一样, Git 通过使用 SHA-1 哈希函数对提交的内容进行哈希处理并将其保存在对象数据库中。重要的是,每个提交对象还包含其父提交的哈希。这样提交就形成了一条链,Git 可以使用它来表示项目的历史记录。
当前目录缓存(暂存区)
你可能知道 Git 的暂存区就是使用 git add 命令后更改文件等待使用 git commit 提交所在的位置,但是暂存区到底是什么呢?
在 Git 的原始版本中,暂存区被称为 当前目录缓存,当前目录缓存只是一个存储在资源库中的二进制文件,路径为 .dircache/index。
如上一节所述,在使用 update-cache (git add) 命令将更改的文件添加到 Git 之后,Git 会计算与这些更改关联的数据对象和树对象,然后将与暂存文件关联的生成的树对象添加到 index 文件中。
之所以称为 缓存,是因为它只是保留已进行的更改在提交之前的临时存储位置,当用户通过运行commit-tree命令进行提交时,当前目录缓存可以提供对应的树,和其他提交信息,比如用于 Git 创建新提交对象的提交消息。
这时候,只是删除了 index 文件,为新更改暂存腾出空间。
内容寻址数据库(对象数据库)
对象数据库是 Git 的主要存储位置,我们上面讨论的所有对象(数据对象,树对象和提交对象)都存储在对象数据库中。在 Git 的原始版本中,对象数据库只是一个目录,路径是 .dircache/objects/。
当 Git 通过诸如 update-cache,write-tree 和 commit-tree(git add 和 git commit 的前身)之类的操作创建对象时,这些对象将被压缩,再进行哈希,然后存储在对象数据库中。
每个对象的名称都是其内容的哈希值,这也是对象数据库为什么也叫作 内容寻址数据库 的原因。每块内容(数据对象、树对象或者提交对象)都基于从内容本身生成的标识符进行存储和检索。
现代版本的 Git 的工作方式几乎相同。不同之处在于现代版本的 Git 通过使用更有效的方法(尤其是与通过网络进行数据传输有关的方法)已经对存储格式进行了优化,但是基本原理是相同的。
总结
在本文中我们讨论了 Git 代码的原始版本,以突出显示如何阅读现有代码可以帮助提高你的编码技能。
我们介绍了以这种方式学习为什么 Git 是一个的好项目的原因,以及如何访问 Git 的代码,并回顾了一些相关的 C 语言编程概念。最后,我们提供了 Git 原始代码库结构的概述,并深入探讨了 Git 代码所依赖的一些概念。
下一步
如果你有兴趣了解有关 Git 代码的更多信息,我们编写了一本指南,你可以在此处查看。这本书详细介绍了 Git 的原始 C 语言代码,并直接说明了该代码是怎么工作的。
我鼓励所有开发人员探索开源社区去尝试找到你感兴趣的高质量项目,这些项目的代码库你可以在几分钟内克隆完。
花一些时间来探究一下代码,你可能会学到一些从未想到的东西。
原文链接:https://www.freecodecamp.org/news/boost-programming-skills-read-git-code/
译者:Lai Weiqing
以上是关于阅读 Git 代码,提升你的编程技能的主要内容,如果未能解决你的问题,请参考以下文章