性能工具之Jmeter 后置监听器可视化数据逻辑
Posted zuozewei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了性能工具之Jmeter 后置监听器可视化数据逻辑相关的知识,希望对你有一定的参考价值。
一、前言
在 Grafana 中加上个 dashboard 等步骤。这些都有详细的说明文章。可以参考以下文章:
简单的跑起来之后,大概看到这样的监控页面:
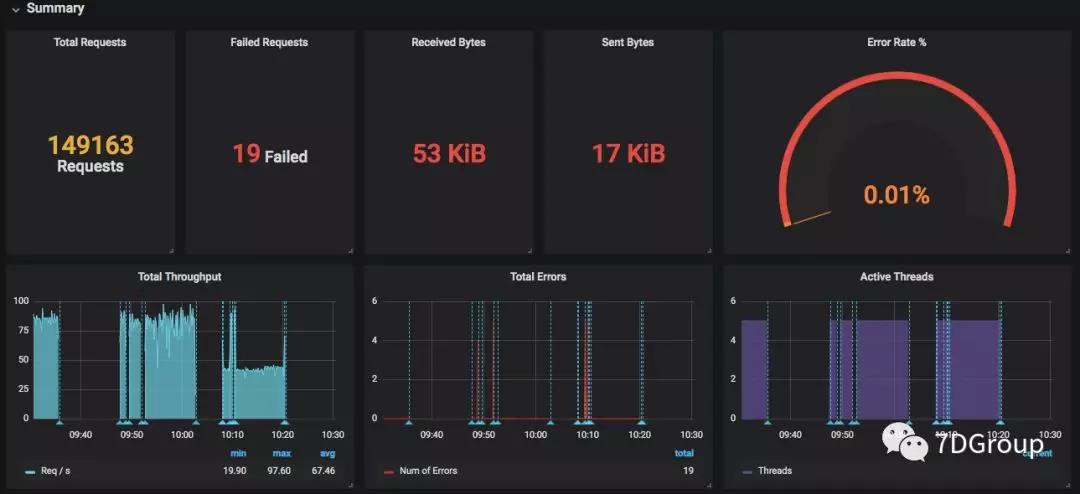
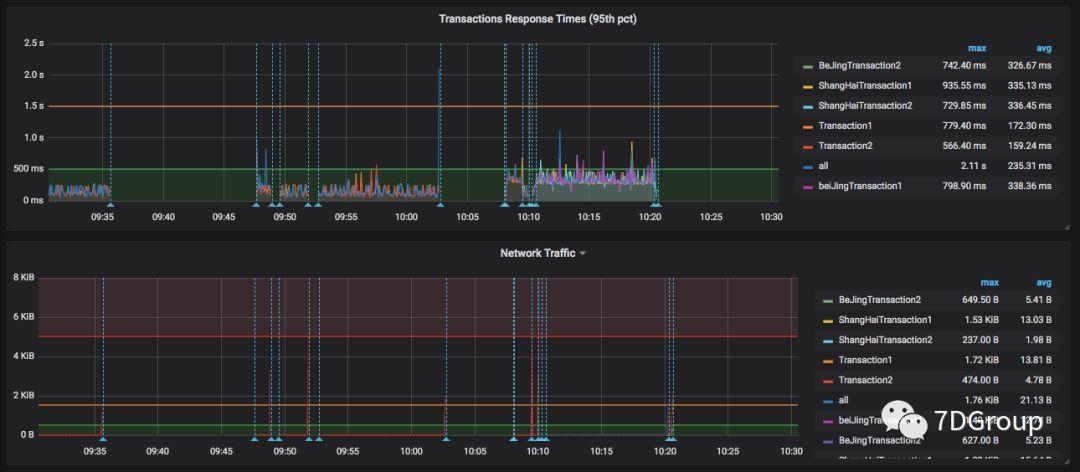
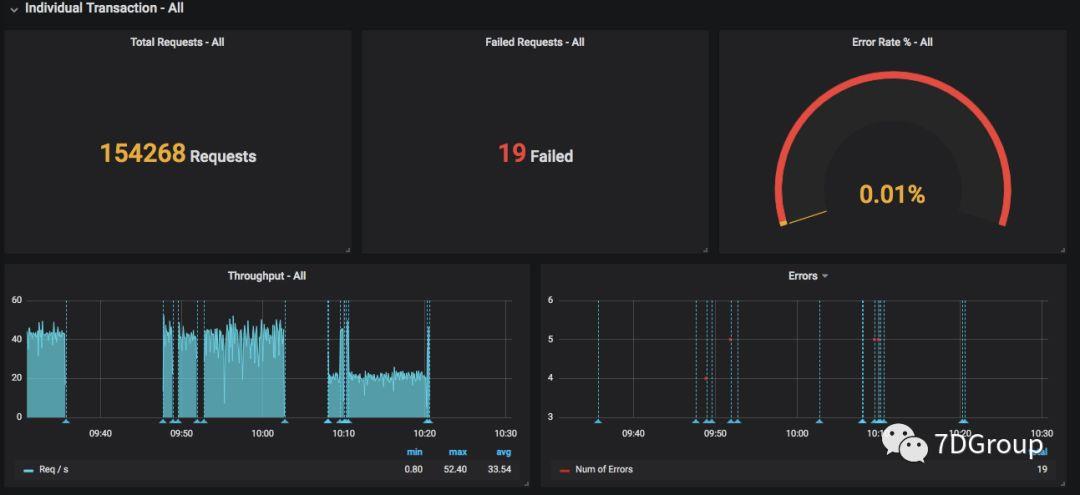
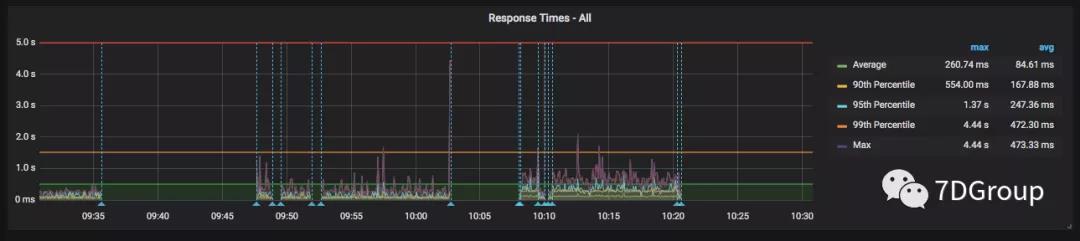
二、主要的数据逻辑
之所以要写这个文章是要说明这些数据为什么要这样展现?
这里分成两个部分,一部分是 summary 的,一部分是针对具体事务的,非常直观。
然后再看筛选器。

我们知道这些数据都来自于 backend listener。所以先来看看Backend listener 的配置。
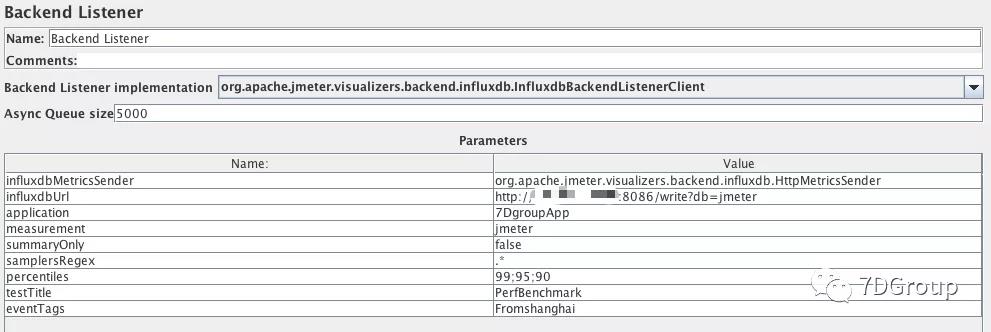
这里的 application 是对应着的,transaction 也是脚本中自己定义的。
Jmeter 要发给 influxdb,怎么发呢?有两个关键部分。如下所示:
private void addMetrics(String transaction, SamplerMetric metric) {
// FOR ALL STATUS
addMetric(transaction, metric.getTotal(), metric.getSentBytes(), metric.getReceivedBytes(), TAG_ALL, metric.getAllMean(), metric.getAllMinTime(),
metric.getAllMaxTime(), allPercentiles.values(), metric::getAllPercentile);
// FOR OK STATUS
addMetric(transaction, metric.getSuccesses(), null, null, TAG_OK, metric.getOkMean(), metric.getOkMinTime(),
metric.getOkMaxTime(), okPercentiles.values(), metric::getOkPercentile);
// FOR KO STATUS
addMetric(transaction, metric.getFailures(), null, null, TAG_KO, metric.getKoMean(), metric.getKoMinTime(),
metric.getKoMaxTime(), koPercentiles.values(), metric::getKoPercentile);
metric.getErrors().forEach((error, count) -> addErrorMetric(transaction, error.getResponseCode(),
error.getResponseMessage(), count));
}
上面是取到数据,然后通过下面这一段发给 influxdb:
protected void sendMetrics() {
synchronized (LOCK) {
for (Map.Entry<String, SamplerMetric> entry : getMetricsInfluxdbPerSampler().entrySet()) {
SamplerMetric metric = entry.getValue();
if (entry.getKey().equals(CUMULATED_METRICS)) {
addCumulatedMetrics(metric);
} else {
addMetrics(AbstractInfluxdbMetricsSender.tagToStringValue(entry.getKey()), metric);
}
// We are computing on interval basis so cleanup
metric.resetForTimeInterval();
}
}
UserMetric userMetrics = getUserMetrics();
// For JMETER context
StringBuilder tag = new StringBuilder(80);
tag.append(TAG_APPLICATION).append(application);
tag.append(TAG_TRANSACTION).append("internal");
tag.append(userTag);
StringBuilder field = new StringBuilder(80);
field.append(METRIC_MIN_ACTIVE_THREADS).append(userMetrics.getMinActiveThreads()).append(',');
field.append(METRIC_MAX_ACTIVE_THREADS).append(userMetrics.getMaxActiveThreads()).append(',');
field.append(METRIC_MEAN_ACTIVE_THREADS).append(userMetrics.getMeanActiveThreads()).append(',');
field.append(METRIC_STARTED_THREADS).append(userMetrics.getStartedThreads()).append(',');
field.append(METRIC_ENDED_THREADS).append(userMetrics.getFinishedThreads());
influxdbMetricsManager.addMetric(measurement, tag.toString(), field.toString());
influxdbMetricsManager.writeAndSendMetrics();
}
然后我们再来看 influxdb 中如何存?
> show databases
name: databases
name
----
_internal
jmeter
> use jmeter
Using database jmeter
>
> show MEASUREMENTS
name: measurements
name
----
events
jmeter
> select * from events where application='7DgroupApp'
name: events
time application tags text title
---- ----------- ---- ---- -----
1564536336377000000 7DgroupApp Round1 PerfBenchmark started ApacheJMeter
..............
> select * from jmeter where application='7DgroupApp' limit 10
name: jmeter
time application avg count countError endedT hit max maxAT meanAT min minAT pct90.0 pct95.0 pct99.0 rb responseCode responseMessage sb startedT statut transaction
---- ----------- --- ----- ---------- ------ --- --- ----- ------ --- ----- ------- ------- ------- -- ------------ --------------- -- -------- ------ -----------
1564536336387000000 7DgroupApp 5 0 0 0 5 internal
1564536341382000000 7DgroupApp 33.8 165 52 22 43.900000000000006 47.89999999999998 52 0 0 all Transaction2
1564536341382000000 7DgroupApp 38.17 332 0 996 60 22 49 52 59.93999999999997 0 0 all all
1564536341383000000 7DgroupApp 43.02 167 80 30 52 55.89999999999998 79.90999999999995 ok Transaction1
............
也就是说在 influxdb 中,创建了两个 MEASUREMENTS,events 和 Jmeter 。里面各自存了数据,我们在界面中配置的 testtile 和 eventTags 放在了 events 这个 measurement 中。
在很多模板中这个表都是不用的。我们在配置 dashboard 的时候,会有这样的选择。
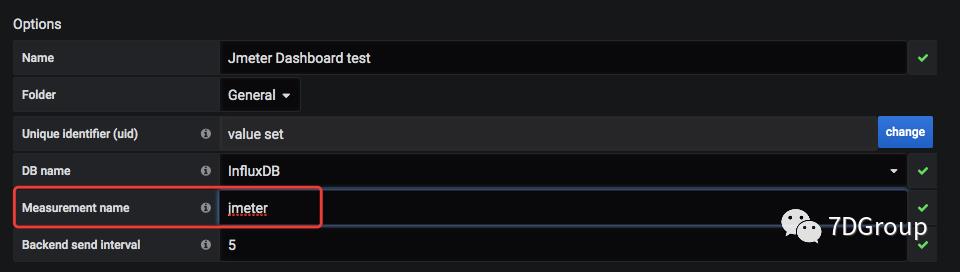
这里就写明了要从哪个 measurement 取数据。
其实在项目的具体实施的角度上来看,testtile 和 eventTags 还是有用的。一般我们都大概会用:
这样的结构来确定某个测试结果。
这里的 testtile 就可以对应到场景中去。但是现在这样的表设计并不能实现这一点。拿来主义总是有不尽如人意的地方。
还有一个 eventTags 也是可以扩展来用的。为什么会需要这样的场景呢?
因为现在的云服务器基本上,在各地都会有,在不同的城市的数据中心,如果我们有一个场景是要这样来做云架构的测试场景。
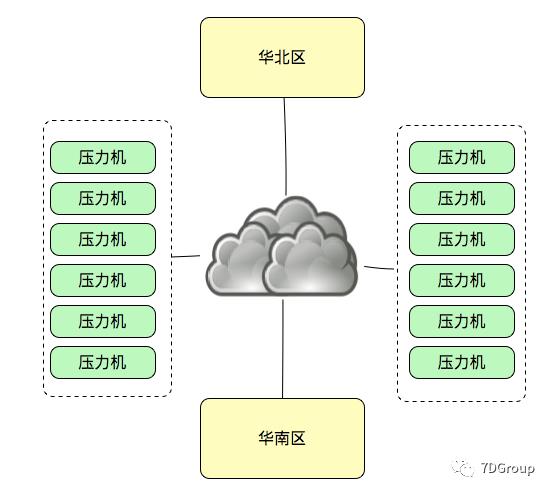
在测试结果中,我们希望能确定各压力机的区域以及所运行的相同事务在响应时间上的区分。这些过滤参数就会比较有用了。
再来说一下数据。这些数据还是比较简单和笼统的,如果要定位的更细一些。像 loadrunner 中的 webpage diagnostics 的功能。
那就要求的太多了。既然不能这样,只能通过其他的手段来做。也就是微服务中必然要做的链路监控和日志分析。
看两个重要的图中的数据 query 吧。
SELECT last("count") / $send_interval FROM "$measurement_name" WHERE ("transaction" =~ /^$transaction$/ AND "statut" = 'ok') AND $timeFilter GROUP BY time($__interval)
上面这个就是 TPS 了。在这里称为Throughput。
SELECT mean("pct95.0") FROM "$measurement_name" WHERE ("application" =~ /^$application$/) AND $timeFilter GROUP BY "transaction", time($__interval) fill(null)
这是 95 pct 的响应时间。
三、小结
后面我会把 Jmeter 做成容器,再指定 node 来运行。因为 Jmeter 做为 Java 的应用,在做 GC 的时候不可避免地影响TPS。多实例运行是必然的。
以上是关于性能工具之Jmeter 后置监听器可视化数据逻辑的主要内容,如果未能解决你的问题,请参考以下文章
性能工具之JMeter+InfluxDB+Grafana打造压测可视化实时监控
性能工具之JMeter+InfluxDB+Grafana打造压测可视化实时监控