深度学习:蒸馏Distill
Posted -柚子皮-
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习:蒸馏Distill相关的知识,希望对你有一定的参考价值。
Distilling the knowledge in a neural network
Hinton 在论文中提出方法很简单,就是让学生模型的预测分布,来拟合老师模型(可以是集成模型)的预测分布,其中可通过用 logits 除以 temperature 来调节分布平滑程度,还避免一些极端情况影响。

蒸馏时的softmax
对于一个分类问题,定义soft label为模型的输出(即不同label的概率), hard label为最终正确的label(也就是ground truth),通常是通过最大化正确label的概率来进行学习的,但是不正确趋近于0的label也是有大有小的,这被称为"暗知识(Dark Knowledge)", 这也反应了模型的泛化能力。但因为过于趋紧0不利于student模型学习,为了让student也容易学习tearcher的输出,引入了带温度T的softmax概率为

比之前的softmax多了一个参数T(temperature),T越大产生的概率分布越平滑。
[Distilling the knowledge in a neural network]
蒸馏自由度还是很大的,并不需要一定按照 Hinton 最初论文里一样只对最后输出进行拟合,只要能让学生模型从老师模型中学习到东西就行。
DistilBert

DistillBert的做法相比bert-pkd就比较简单直接,还是保证模型的宽度不变,模型深度减为一半。主要在初始化和损失函数上下了功夫:
- 损失函数:采用知识蒸馏损失、Masked Language Model损失和cosine embedding损失加起来的值。
- 初始化:用Teacher模型的参数进行初始化,不过是从每两层中找一层出来。
Student architecture
和BERT类似,只是layer的数量减半
Student initialization
因为Student模型和Teacher模型每层的layer一样,因此每两层保留一层,利用相关的参数
Distillation
采用了RoBERTa的优化策略,动态mask,增大batch size,取消NSP任务的损失函数,
Training Loss
The final training objective is a linear combination of the distillation loss L_{ce} with the supervised training loss, in our case the masked language modeling loss L_{mlm} We found it beneficial to add a cosine embedding loss ( L_{cos} ) which will tend to align the directions of the student and teacher hidden states vectors.
最终的loss由三部分构成
1 蒸馏损失,即 L_ce = ∑ t i ∗ log ( s_i ), 其中 s_i 是student输出的概率, t_i 是teacher输出的概率,当BERT预测的 t_i越高,而DistilBERT预测s_i越低,得到的Loss就会越高
2 Mask language model loss,参考BERT,这部分也就是为hard loss
3 Cosine Embedding Loss,利于让student学习和teacher一样的hidden state vector
[DistilBERT, a distilled version of BERT: smaller,faster, cheaper and lighter]
[模型训练损失值不变_Bert与模型蒸馏: PKD和DistillBert]
BERT-PKD (Patient Knowledge Distillation)

在hinton提到两个损失之上,再加上一个loss:L_PT。
![]()
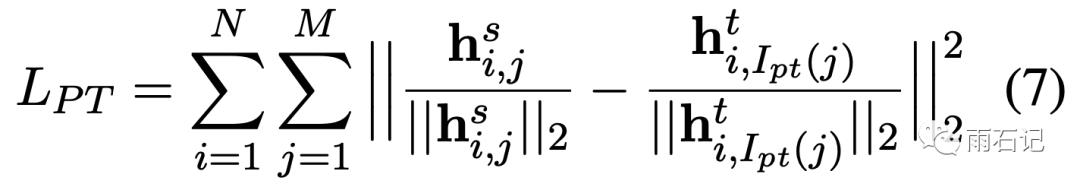
PKD论文中做了对比,减少模型宽度和减少模型深度,得到的结论是减少宽度带来的efficiency提高不如减少深度来的更大。
论文所提出的多层蒸馏,即Student模型除了学习Teacher模型的概率输出之外,还要学习一些中间层的输出。论文提出了两种方法,第一种是Skip模式,即每隔几层去学习一个中间层,第二种是Last模式,即学习teacher模型的最后几层。如果是完全的去学习中间层的话,那么计算量很大。为了避免这个问题,我们注意到Bert模型中有个特殊字段[CLS],因为其在 BERT 分类任务中的重要性,在蒸馏过程中,让student模型去学习[CLS]的中间的输出,计算过程是先归一化,然后直接 均方差MSE 求损失。
Note:
1 至于学生模型中间层如何与老师模型中间层对应,论文中发现最佳策略是直接按倍数取老师模型对应层就行,比如1对2,2对4这样。
2 初始化的话就采用Teacher模型的前几层来做初始化。
3 更好的teacher模型会带来增长么?答案是不会的,可以看上图,把12层的Bert模型换成了24层的Bert模型,反而导致效果变差。究其原因,可能是因为在实验中,我们使用Teacher模型的前N层来初始化Student模型,对于24层模型来说,前N层更容易导致不匹配。而更好的方法则是Student模型先训练好,再去学Teacher模型。
[Patient Knowledge Distillation for BERT Model Compression]
TinyBERT
华为的 TinyBERT,比起上面的 PKD 只是对中间层 [CLS] 进行拟合,它更深入了一步。对 BERT 全范围进行拟合,词向量层,中间隐层,中间注意力矩阵,最后预测层。
在BERT 预训练阶段 和 Fine-tune阶段 分别做蒸馏,如下所示:

其中Transformer Distillation 在预训练和 fine-tune 阶段都是一样的,分为三个部分:
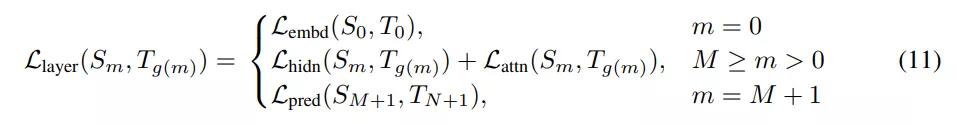

Note: 式11分别是所有token的 embedding、hidden layer outputs 和 attention matrix的MSE loss,L_pred 是 hinton 的dark knowledge。
在 预训练阶段 和 Fine-tune阶段 都仅使用了蒸馏的loss,而没有使用 MLM loss 和 分类 CE loss。
[TinyBERT:模型小7倍,速度快8倍,华中科大、华为出品]
[TinyBERT: Distilling BERT for Natural Language Understanding, Xiaoqi Jiao et al. EMNLP(findings), 2020 [code]]
from: -柚子皮-
ref: [BERT 瘦身之路:Distillation,Quantization,Pruning]
以上是关于深度学习:蒸馏Distill的主要内容,如果未能解决你的问题,请参考以下文章