2021年大数据Hadoop:HDFS的元数据辅助管理
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据Hadoop:HDFS的元数据辅助管理相关的知识,希望对你有一定的参考价值。
目录
HDFS的元数据辅助管理
当 Hadoop 的集群当中, NameNode的所有元数据信息都保存在了 FsImage 与 Eidts 文件当中, 这两个文件就记录了所有的数据的元数据信息, 元数据信息的保存目录配置在了 hdfs-site.xml 当中
<property>
<name>dfs.namenode.name.dir</name>
<value>
file:///export/servers/hadoop2.7.5/hadoopDatas/namenodeDatas</value>
</property>
<property>
<name>dfs.namenode.edits.dir</name>
<value>file:///export/servers/hadoop-2.7.5/hadoopDatas/nn/edits</value>
</property>>一、FsImage和Edits
edits:
edits 是在NameNode启动时对整个文件系统的快照存放了客户端最近一段时间的操作日志
客户端对 HDFS 进行写文件时会首先被记录在 edits 文件中
edits 修改时元数据也会更新
fsimage:
fsimage是在NameNode启动时对整个文件系统的快照
NameNode 中关于元数据的镜像, 一般称为检查点, fsimage 存放了一份比较完整的元数据信息
因为 fsimage 是 NameNode 的完整的镜像, 如果每次都加载到内存生成树状拓扑结构,这是非常耗内存和CPU, 所以一般开始时对 NameNode 的操作都放在 edits 中
随着edits 内容增大, 就需要在一定时间点和 fsimage 合并
二、SecondaryNameNode的作用
SecondaryNameNode的作用是合并fsimage和edits文件。
NameNode的存储目录树的信息,而目录树的信息则存放在fsimage文件中,当NameNode启动的时候会首先读取整个fsimage文件,将信息装载到内存中。
Edits文件存储日志信息,在NameNode上所有对目录的最新操作,增加,删除,修改等都会保存到edits文件中,并不会同步到fsimage中,当NameNode关闭的时候,也不会将fsimage和edits进行合并。
所以当NameNode启动的时候,首先装载fsimage文件,然后按照edits中的记录执行一遍所有记录的操作,最后把信息的目录树写入fsimage中,并删掉edits文件,重新启用新的edits文件。
但是如果NameNode执行了很多操作的话,就会导致edits文件会很大,那么在下一次启动的过程中,就会导致NameNode的启动速度很慢,慢到几个小时也不是不可能,所以出现了SecondNameNode。
三、SecondaryNameNode唤醒合并的规则
SecondaryNameNode 会按照一定的规则被唤醒,进行fsimage和edits的合并,防止文件过大。
合并的过程是,将NameNode的fsimage和edits下载到SecondryNameNode 所在的节点的数据目录,然后合并到fsimage文件,最后上传到NameNode节点。合并的过程中不影响NameNode节点的操作
SecondaryNameNode被唤醒的条件可以在core-site.xml中配置:
fs.checkpoint.period:单位秒,默认值3600(1小时),检查点的间隔时间,当距离上次检查点执行超过该时间后启动检查点
fs.checkpoint.size:单位字节,默认值67108864(64M),当edits文件超过该大小后,启动检查点
[core-site.xml]
<!-- 多久记录一次 HDFS 镜像, 默认 1小时 -->
<property>
<name>fs.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一次记录多大, 默认 64M -->
<property>
<name>fs.checkpoint.size</name>
<value>67108864</value>
</property>SecondaryNameNode一般处于休眠状态,当两个检查点满足一个,即唤醒SecondaryNameNode执行合并过程。
四、SecondaryNameNode工作过程
第一步:将hdfs更新记录写入一个新的文件——edits.new。
第二步:将fsimage和editlog通过http协议发送至secondary namenode。
第三步:将fsimage与editlog合并,生成一个新的文件——fsimage.ckpt。这步之所以要在secondary namenode中进行,是因为比较耗时,如果在namenode中进行,或导致整个系统卡顿。
第四步:将生成的fsimage.ckpt通过http协议发送至namenode。
第五步:重命名fsimage.ckpt为fsimage,edits.new为edits。
第六步:等待下一次checkpoint触发SecondaryNameNode进行工作,一直这样循环操作。
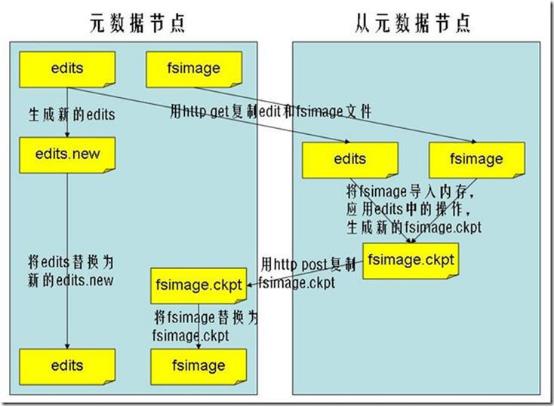
注意:SecondaryNameNode 在合并 edits 和 fsimage 时需要消耗的内存和 NameNode 差不多, 所以一般把 NameNode 和 SecondaryNameNode 放在不同的机器上
五、fsimage 中的文件信息查看
使用命令 hdfs oiv
cd /export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas/current
hdfs oiv -i fsimage_0000000000000000138 -p XML -o hello.xml六、edits中的文件信息查看
使用命令 hdfs oev
cd /export/server/hadoop-2.7.5/hadoopDatas/nn/edits/current
hdfs oev -i edits_0000000000000000865-0000000000000000866 -p XML -o myedit.xml
七、NameNode元数据恢复
当NameNode发生故障时,我们可以通过将SecondaryNameNode中数据拷贝到NameNode存储数据的目录的方式来恢复NameNode的数据
操作步骤:
1、杀死NameNode进程
kill -9 NameNode进程号2、删除NameNode存储的数据
rm /export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas/* -fr3、在node2主机上,拷贝SecondaryNameNode中数据到原NameNode存储数据目录
cd /export/server/hadoop-2.7.5/hadoopDatas/snn/name/
scp -r current/ node1:/export/server/hadoop-2.7.5/hadoopDatas/namenodeDatas4、重新启动NameNode
hadoop-daemon.sh start namenode
以上是关于2021年大数据Hadoop:HDFS的元数据辅助管理的主要内容,如果未能解决你的问题,请参考以下文章