JNI字符编码
Posted 不会写代码的丝丽
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JNI字符编码相关的知识,希望对你有一定的参考价值。
前言
这段时间看MMKV的时候突然忘了JNI字符编码的= =,于是乎测试了下并记录笔记.
首先要明白的概念:
在JVM内存中字符串是UTF-16编码.
具体可以看参考3
其中部分描述如下:
In the Java SE API documentation, Unicode code point is used for character values in the range between U+0000 and U+10FFFF, and Unicode code unit is used for 16-bit char values that are code units of the UTF-16 encoding.
举个例子:
//采用的utf-16存储jvm内存中
String str = "中";
默认字节输出
String msg = "中";
//在默认情况下返回字节码的编码为Charset.defaultCharset()
//你可以通过-Dfile.encoding=GB2312去定义默认的编码规则
msg.getBytes();
我们首先输出一下中的各种编码
public static void main(String[] args) throws InterruptedException, UnsupportedEncodingException {
String msg = "中";
printSpecifyCharset(Charset.forName("utf-8"),msg);
//utf-16小端编码 如果你传入utf-16那么会多一个字节用于标识是大端还是小端
printSpecifyCharset(Charset.forName("utf-16le"),msg);
//小端编码
printSpecifyCharset(Charset.forName("utf-32le"),msg);
printSpecifyCharset(Charset.forName("gbk"),msg);
}
static void printSpecifyCharset(Charset charset,String msg){
byte[] bytes = msg.getBytes(charset);
printBytes(charset.displayName(),bytes);
}
static void printBytes(String charset, byte[] print) {
System.out.println("当前字节编码为:[" + charset + "] 字节长度为:[" + print.length + "]");
for (byte wbyte : print) {
//为操作主要是用来截断为8位输出
System.out.printf("二进制:[" + Integer.toBinaryString(wbyte & 255 | 256).substring(1) + "] 16进制:[%x]\\n",wbyte);
}
}
当前字节编码为:[UTF-8] 字节长度为:[3]
二进制:[11100100] 16进制:[e4]
二进制:[10111000] 16进制:[b8]
二进制:[10101101] 16进制:[ad]
当前字节编码为:[UTF-16LE] 字节长度为:[2]
二进制:[00101101] 16进制:[2d]
二进制:[01001110] 16进制:[4e]
当前字节编码为:[UTF-32] 字节长度为:[4]
二进制:[00000000] 16进制:[0]
二进制:[00000000] 16进制:[0]
二进制:[01001110] 16进制:[4e]
二进制:[00101101] 16进制:[2d]
当前字节编码为:[GBK] 字节长度为:[2]
二进制:[11010110] 16进制:[d6]
二进制:[11010000] 16进制:[d0]
这里我们顺带查询一下对应中的unicode编码
unicode编码查询网址

中的unicode编码为:4E2D
我们顺带看一下c语言平台的字符编码:
const char * ch = "中";请问这个编码在c++中是以什么编码?
这个答案是要根据平台来回答。
在Win32平台为GBK,在android为UTF-8
我们在c++打印下对应的编码
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <tchar.h>
#include <string>
using namespace std;
int main()
{
const char * ch = "中";
int i = 0;
char out[100] = {};
while (ch[i]!='\\u0000')
{
sprintf(out, "%x\\n", ch[i] & 255 | 256);
string myOut(out);
string subMsg = myOut.substr(1);
printf("当前字节%s\\n", subMsg.c_str());
i++;
}
return 0;
}
在WINDOWS下的输出:
当前字节d6
当前字节d0
可见在WIN32平台采用的是GBK编码。
我们看下Android下执行类似的代码
#include <jni.h>
#include <string>
#include <stdio.h>
#include <cwchar>
#include <string>
#include <android/log.h>
using namespace std;
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv* env,
jobject /* this */) {
const char * ch = "中";
int i = 0;
while (ch[i]!='\\u0000')
{
char out[100] = {};
sprintf(out, "%x\\n", ch[i] & 255 | 256);
string myOut(out);
string subMsg = myOut.substr(1);
__android_log_print(ANDROID_LOG_ERROR,"ANDROID_JNI","当前字节%s\\n", subMsg.c_str());
i++;
}
std::string hello = "Hello from C++";
return env->NewStringUTF(hello.c_str());
}
输出
E/ANDROID_JNI: 当前字节e4
E/ANDROID_JNI: 当前字节b8
E/ANDROID_JNI: 当前字节ad
可见Android平台为UTF-8编码
wchar_t实验
wchar_t用来存储宽字符,默认情况等于unicode编码,但是在win32和linux这两个是有差别的,在win32中wchar_t是2字节,linux是4字节。可见在win32对于超过2字节的unicode存在问题。
我们首先看两个Android 实验
using namespace std;
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */) {
const wchar_t *ch2 = L"中";
const char *ch = reinterpret_cast<const char *>(ch2);
int i = 0;
__android_log_print(ANDROID_LOG_ERROR, "ANDROID_JNI", "字符串长度 %d\\n", wcslen(ch2));
__android_log_print(ANDROID_LOG_ERROR, "ANDROID_JNI", "sizeof wchar_t %d\\n", sizeof(wchar_t ));
while (ch[i] != '\\u0000') {
char out[100] = {};
sprintf(out, "%x\\n", ch[i] & 255 | 256);
string myOut(out);
string subMsg = myOut.substr(1);
__android_log_print(ANDROID_LOG_ERROR, "ANDROID_JNI", "当前字节%s\\n", subMsg.c_str());
i++;
}
std::string hello = "Hello from C++";
return env->NewStringUTF(hello.c_str());
}
输出:
E/ANDROID_JNI: 字符串长度 1
E/ANDROID_JNI: sizeof wchar_t 4
E/ANDROID_JNI: 当前字节2d
E/ANDROID_JNI: 当前字节4e
非常标准的unicode编码。
我们在测试一个特殊的汉字𪚥
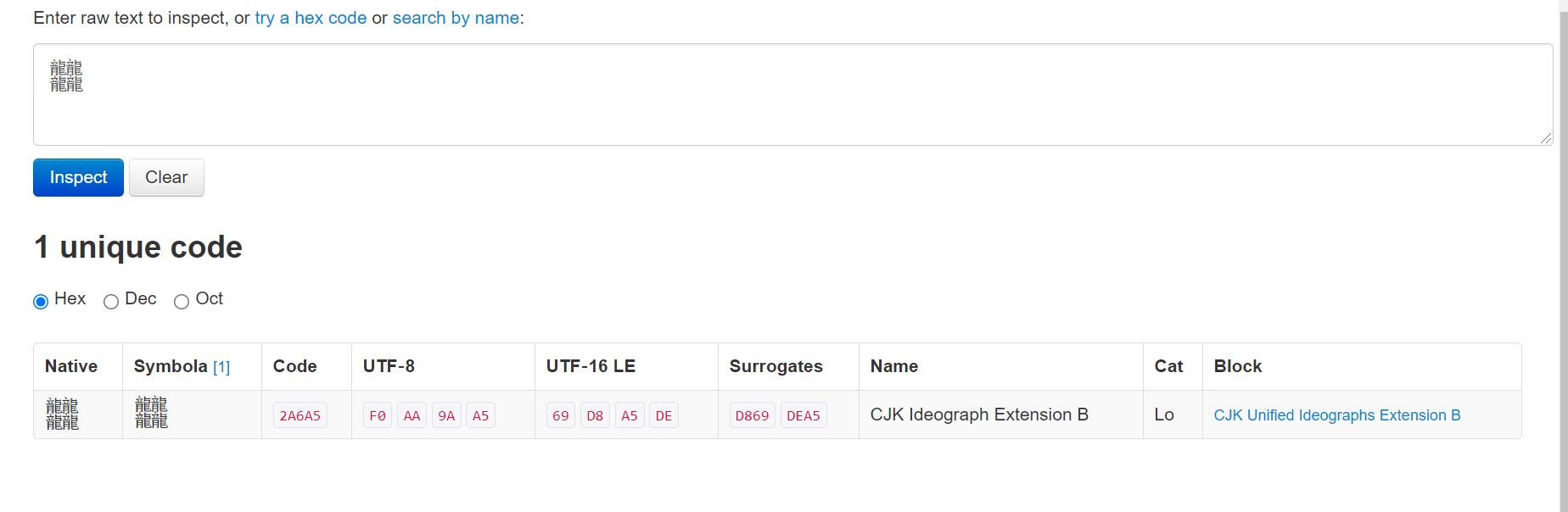
这个汉字需要三个字节去存储,我们看看这个字符串在Android的输出
using namespace std;
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */) {
const wchar_t *ch2 = L"𪚥";
//..略 代码同上
}
E/ANDROID_JNI: 字符串长度 1
E/ANDROID_JNI: sizeof wchar_t 4
//汉字标准的unicode编码为:2 A6 A5
E/ANDROID_JNI: 当前字节a5
E/ANDROID_JNI: 当前字节a6
E/ANDROID_JNI: 当前字节02
可见wchar_t可以得到标准的unicode编码
我们看看windows下的的代码测试
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <tchar.h>
#include <string>
using namespace std;
int main()
{
const wchar_t *lwc = L"𪚥";
const char * ch = (char *)lwc;
printf("sizeof wchar_t %d\\n", sizeof(wchar_t));
printf("字符串长度 %d\\n", wcslen(lwc));
int i = 0;
char out[100] = {};
while (ch[i]!='\\u0000')
{
sprintf(out, "%x\\n", ch[i] & 255 | 256);
string myOut(out);
string subMsg = myOut.substr(1);
printf("当前字节%s\\n", subMsg.c_str());
i++;
}
return 0;
}
输出:
sizeof wchar_t 2
字符串长度 2
当前字节69
当前字节d8
当前字节a5
当前字节de
sizeof返回2证明wchar_t在win32为2字节.
wcslen输出2很明显是一个错误的答案。
后面四个字节是正确的,证明win32支持unicode3字节的编号,这里也证明win32使用utf-16le编码.(超过2字节unicode编码采用surrogate pare来编码)
jni编码
我们来看两个常见的API
struct JNIEnv_ {
jstring NewString(const jchar *unicode, jsize len)
jstring NewStringUTF(const char *utf)
}
上面两个API说明:
//构造一个jstring对象,unicode参数为utf16编码,官方文档说为unicode个人感觉是错误的
jstring NewString(const jchar *unicode, jsize len)
//传入一个 mutf-8的字符串构造一个jstring,注意这里是mutf-8不是utf-8
jstring NewStringUTF(const char *utf)
关于utf-8和mutf-8主要区别在于对\\u0000编码的的处理
在utf-8中\\0000就是0000 0000 0000 0000.而在mutf-8为 1100 0000 1000 0000(0xC080)
具体可参阅Oracle文档JNI Types and Data Structures
之所以java采用mutf-8是为了防止以\\0000作为字符串结束的语言在跟java通信的时候出现障碍.java能够识别一个字符串包含\\0000,而c++却把它作为结束标志。
- NewStringUTF实验
使用NewStringUTF需要特别注意下面的代码
class MainActivity : AppCompatActivity() {
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
//得到jni返回字符串
val stringFromJNI = stringFromJNI()
var msg= "l\\u0000ove"
Log.e("jni","jni 返回的字符串$stringFromJNI")
Log.e("jni","jni 返回的字符串是否java相等 ${msg==stringFromJNI}")
}
external fun stringFromJNI(): String
companion object {
// Used to load the 'native-lib' library on application startup.
init {
System.loadLibrary("native-lib")
}
}
}
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */) {
//android 是utf-8编码
std::string hello = "l\\u0000ove";
return env->NewStringUTF(hello.c_str());
}
输出:
E/jni: jni 返回的字符串l
E/jni: jni 返回的字符串是否java相等 false
解决方式:
转码\\0000,让c++环境不认识它,在把它透传到java
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */) {
//android 是utf-8编码
//假设网络传入了一个字符串包含\\0000
std::string hello = "l";
hello+=0xc0;
hello+=0x80;
hello+="ove";
return env->NewStringUTF(hello.c_str());
}
NewStringUTF在Android环境如果不考虑\\0000是可以直接跟java交换字符串。
在win32环境我们知道char是GBK编码的自然会出现问题
//win32环境
extern "C"
JNIEXPORT jstring JNICALL Java_MyJavaMainClass_hello
(JNIEnv * env, jclass) {
const char * ch = "中";
//return env->NewString((jchar *)ch2, wcslen(ch2));
return env->NewStringUTF(ch);
}
//win32环境
public class MyJavaMainClass {
public static void main(String[] args) {
System.out.printf(hello());
}
native static String hello();
static {
System.load("C:/Users/fmy/source/repos/Project10/x64/Debug/Project10.dll");
}
}
输出:
ÖÐ
解决办法,gbk转utf8:
这里我们直接返回utf8字符串数组即可,您可以自己寻找合适的转码库
extern "C"
JNIEXPORT jstring JNICALL Java_MyJavaMainClass_hello
(JNIEnv * env, jclass) {
string name = "";
name += 0xe4;
name += 0xb8;
name += 0xad;
return env->NewStringUTF(name.c_str());
}
- NewString实验
//构造一个jstring对象,unicode参数为utf16编码,官方文档说为unicode个人感觉是错误的
//len 存在多少个2字节。这个可能需要代理对的知识,比如三字节的unicode编码,那么在utf-16需要四个字节来编码。假设一个传入的字符串是一个3字节的unicode编码,那么len传入2(4字节除以2)
jstring NewString(const jchar *unicode, jsize len)
我们在win32直接使用wchar_t就是utf16编码
//win32 可以正确返回 且被java识别
extern "C"
JNIEXPORT jstring JNICALL Java_MyJavaMainClass_hello
(JNIEnv * env, jclass) {
const wchar_t * ch2 = L"𪚥";
return env->NewString((jchar *)ch2, wcslen(ch2));
}
上面的3字节unicode编码可以在win32的java正确的显示.
我们看下在android平台下(这里使用kotlin语言)
//stringFromJNI从native获取字符串
val stringFromJNI = stringFromJNI()
var msg="𪚥"
Log.e("jni","jni 返回的字符串$stringFromJNI")
Log.e("jni","jni 返回的字符串是否java相等 ${msg==stringFromJNI}")
//android 平台输出
jni 返回的字符串ꚥ
jni 返回的字符串是否java相等 false
这里将NewString第二个参数改为2也是同样的返回乱码。原因是编码不为utf-16,这里是unicode编码。
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */) {
//android 平台存储的是标准的unicode编码。而不是utf-16
const wchar_t *ch2 = L"𪚥";
//特意修改长度为2
return env->NewString((jchar*)ch2,2);
}
//android 平台输出
jni 返回的字符串ꚥ
jni 返回的字符串是否java相等 false
在Android平台你可以按如下操作:
using namespace std;
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */) {
// 69 D8 A5 DE 是对应的utf16编码
string name;
name+=0x69;
name+=0xD8;
name+=0xA5;
name+=0xDE;
char *pname= const_cast<char *>(name.c_str());
//strlen(pname)/2是因为utf-16超出2字节的使用 代理对(surrogate paire)来处理
//
return env->NewString((jchar*)pname,strlen(pname)/2);
}
综上你应该清楚的理解乱码的问题所在了把?你可以在c++库放入一个转码库,或者jni反射调用java层string函数来得到对应编码字节数组。
其他注意点
GetStringChars获取jchar为utf16编码,且末尾不会补\\u0000
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */, jstring msg) {
const jchar * pjchar=env->GetStringChars(msg,NULL);
const char *ch = reinterpret_cast<const char *>(pjchar);
int i=0;
while (ch[i] != '\\u0000') {
char out[100] = {};
sprintf(out, "%x\\n", ch[i] & 255 | 256);
string myOut(out);
string subMsg = myOut.substr(1);
__android_log_print(ANDROID_LOG_ERROR, "ANDROID_JNI", "当前字节%s\\n", subMsg.c_str());
i++;
}
//略
}
假设我们传入
val stringFromJNI = stringFromJNI("𪚥")
输出
//下面的四个字节是正确utf-16
当前字节69
当前字节d8
当前字节a5
当前字节de
//后面的字节是内存其他区域
当前字节48
当前字节65
当前字节ac
//...略一直找到0编码
使用时需要注意字节长度的问题。
GetStringUTFChars返回MUTF-8编码,末尾自动补上0
假设我们传入
val stringFromJNI = stringFromJNI("𪚥")
using namespace std;
extern "C" JNIEXPORT jstring JNICALL
Java_com_example_myapplication_MainActivity_stringFromJNI(
JNIEnv *env,
jobject /* this */, jstring msg) {
const char * ch=env->GetStringUTFChars(msg,NULL);
int i=0;
while (ch[i] != '\\u0000') {
char out[100]