听说,难于上青天的云原生数据湖能开箱即用了?
Posted QcloudCommunity
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了听说,难于上青天的云原生数据湖能开箱即用了?相关的知识,希望对你有一定的参考价值。

导语 | 云原生数据湖架构以低成本优势推动客户上云,同时云上客户得以低成本撬动更多结构化和非结构化数据的价值,是一场云厂商的自我革命。本文由腾讯大数据专家工程师于华丽在 Techo TVP开发者峰会「数据的冰与火之歌——从在线数据库技术,到海量数据分析技术」的《云原生数据湖新一代数据架构》演讲分享整理而成,为大家详尽介绍云原生数据湖的价值和背景,云原生数据湖架构原则和挑战,同时分析腾讯云数据湖产品,展望腾讯云数据湖解决方案。
点击可观看精彩演讲视频
一、云原生数据湖架构的价值
今天分四个阶段来为大家介绍,第一个阶段我们先看云原生数据湖到底是什么,主要是背景、价值和挑战;第二阶段会教大家怎么去构建一个云原生数据湖,这里面其实有很多技术上的挑战,需要大家有很丰富的公有云的背景甚至大数据的知识;所以基于这个背景,腾讯云为了让大家快速地去迁移到云原生数据湖的架构,有两个产品推出;最后是基于DLC和DLF两个产品,展望在腾讯云上,数据湖的整体解决方案到底是如何做的。
我个人对云原生的理解,包括在CNCF的一些定义上,它的核心叫做弹性应用,这两个词后面的数据湖更多的是海量廉价的存储,所以我对云原生整个数据湖的架构给了一个定义:充分结合云上的弹性计算和对象存储的优势,以及大数据前沿数据湖的一些技术,构建一个高性价比、高性能的大数据平台。
为什么会诞生一种新的架构?它一定是在传统的或前一代的数据架构上有一些不能满足的问题。在今天的情况下大家对上云这件事已经比较认可,但怎么上云、怎么在云上做大数据架构,传统的做法是有一些缺陷的。传统做法简单来说是存算耦合且规模固定,它有这四大痛点:第一是成本高,体现在hdfs的规模和计算规模不匹配,因为大家越来越重视数据,所以海量数据的挖掘需要更好的存储。云主机本身成本会相对较高,hdfs维护成本高。第二是灵活性低,相当于它很难满足adhoc需求,以及backfill这种临时的、大量的计算需求,还有集群升级困难,迁移数据,都是非常大的工作量。第三是性能差,namenode的性能一直是痛点,比如小文件的性能,甚至做存算耦合之后,整个shuffle性能也是会受到磁盘影响。第四是可靠性,现在大家越来越重视数据的安全,多az设计,hdfs怎么利用多az存储去做ha,这其实都是很大的挑战。
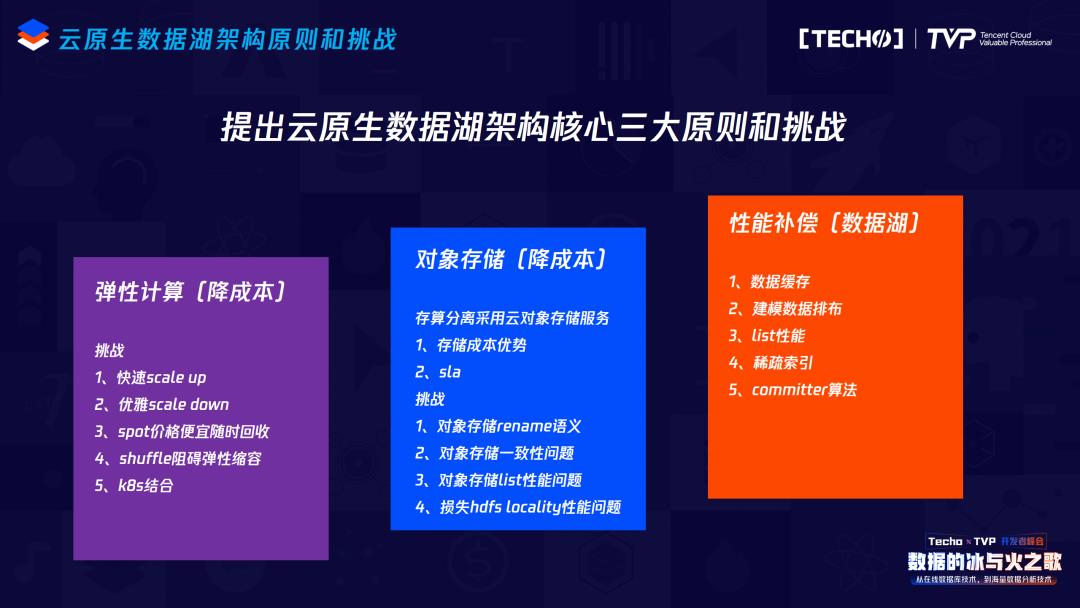
在云上应对这些挑战会有哪些机遇?核心是两个点:一个是弹性计算,第二个是对象存储。弹性计算,第一个是我们能够削峰填谷地利用计算资源,不需要的时候及时释放,以及充分利用像spot这种低价的计算资源,相比传统的大数据、云原生数据湖能够达到3-5倍的成本优势。第二个点,对象存储,首先它得益于自己的EC编码以及SaaS形式,不需要预留存储、不需要专业人员去运维,它对比hdfs有接近5-10倍的成本优势,当然它也有很好的跨az云厂商的带宽支撑,解决了小文件甚至namenode性能的问题。当然它还有更多好的特性,比如生命周期的管理、冷冻数据更可靠,以至于数据成本甚至会比10倍更低。
云原生数据湖架构只是一种架构原理,它具体的实现多种多样,基于EMR我们可以做云原生数据湖,甚至基于Flink也可以做。大家如果今天自己去构建一个云原生数据湖,都有哪些事情要做?以及做的时候会有哪些挑战?
二、手把手构建云原生数据湖
如果要利用弹性计算降低成本,会面临一些挑战。如何快速地scale up,根据用户的诉求把你的集群快速扩容?你要优雅地scale down,因为大数据是有状态的,怎么让这个shuffe的状态减少scale down的时候对用户作业产生的影响?都是很重要的问题。像spot这种机器很便宜,但会随时被回收,这种情况下,怎么利用它而你的quarry不至于被回收机器打断,这里一定要做一些工作。刚刚说shuffe会阻碍弹性,大家解决问题的时候会发现真正要做到比较好的弹性,都要结合像k8s这种云原生的容器管理,这里面会有很多的背景知识,需要大家自己去掌握。
关于对象存储,它有它的好处,比如刚刚说的成本5-10倍的优势,以及它有自己很好的sla。但它其实也并不是那么美好:对象存储没有rename语义,会带来什么问题?比如ETL任务本身1个小时能完成,但没有rename语义,可能就需要5个小时。对象存储一般都是最终一致性的,这会带来数据质量的问题,任务会频繁失败。对象存储的list性能一般都不够好,当然这涉及到对象存储的整个的设计,因为它是一个网络存储,失去了传统做大数据用hdfs locality性能的优势,就会导致计算变得更慢。
结合前面两个问题,架构下一步要做的事情是做很多的性能补偿。比如我们要做一些数据的缓存,因为本身是一个网络的存储对象存储,本地如果有一些很小的缓存能够满足大量的查询需求,肯定对性能上会有很大的提升。我们在建模数据上一定有更好的排布,不能像传统一样只把数据摆在那儿,其他的数仓都会做一些类似于稀疏索引,把这个数据做更好的排布之后,性能才能得到更好的提升,list性能、committer算法肯定也要去管理。
三、腾讯云原生数据湖产品:
数据湖计算+数据湖构建
要做一个云原生数据湖架构,这一系列问题大家都会面临,按照我自己的经验,做一个比较初步的、粗浅的云原生数据湖,大概需要20个人的团队做两年时间,整体来说构建成本还是很高的。基于云原生数据湖这么好,但是它又这么难构建,腾讯云数据湖推出了两款大数据数据湖的产品,一个是数据湖计算DLC,已经在公测阶段。另一个是数据湖构建DLF,在6月份左右会推出。DLC的产品定位更多聚焦于分析、联邦计算,当然我们也在迭代像数仓Spark的建设、构建服务。DLF更多是统一的元数据管理,高效的数据入湖。

简单介绍一下DLC和DLF数据湖的统一架构,它没有区分两个产品,一个是产品形态,我们的后端其实是一套架构,分为三个主要的核心部分,第一个是基于容器服务的统一计算,容器服务就是腾讯云的k8s,有标准统一的SQL入口,有多引擎的支持,像Presto、Spark、Hive、腾讯TEG的supersql引擎,以及联邦分析的功能。第二块是容纳海量元数据的统一元数据服务,当然也是基于社区的Hive MetaStore扩展,但因为要支持海量的租户,所以它不会像开源的Hive MetaStore只能支持几个亿的元数据,而是海量的。最后很重要的一个部分是基于对象存储,数据湖Table Format的数据湖存储,这是对象存储很重要的一部分。基于这三个架构,弹性在统一计算里解决,存储问题在数据湖存储解决,至于统一元数据,这个问题的核心是首先要有元数据,我们会展望腾讯云上所有的大数据产品怎么合力,之后会有统一元数据的设计。
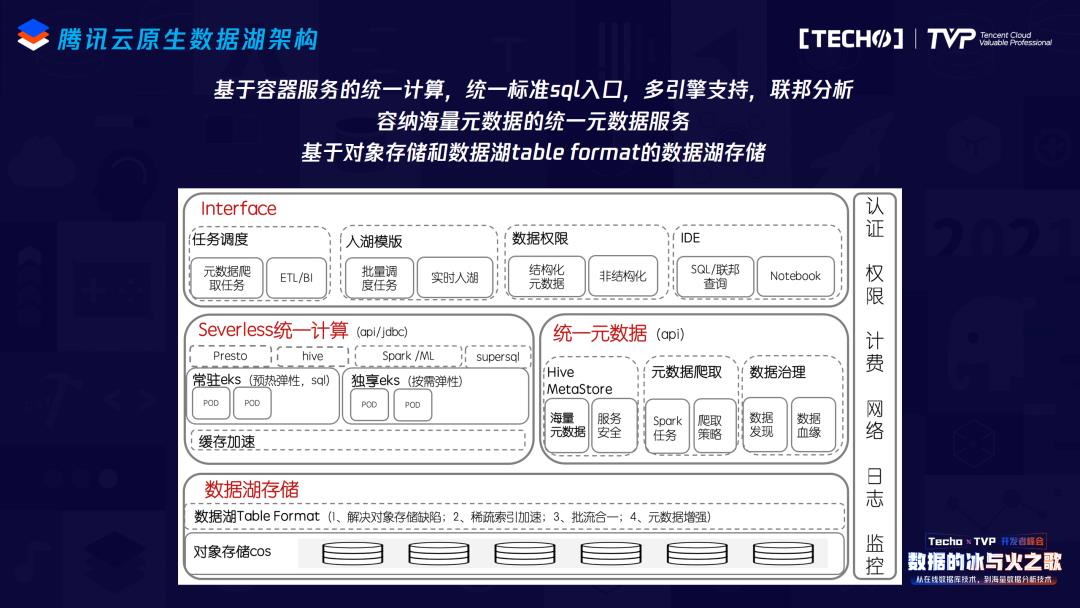
技术上今天就稍微展开讲一个点。腾讯云原生数据湖相对比较核心的一个技术是iceberg,iceberg的诞生经历了十年之久,2008年开始上云,当然它没有提出“云原生数据湖架构”这个名词,但很早就基于S3做存储,基于EMR的弹性做它的弹性计算。Iceberg核心到底在解决什么问题?一言以蔽之,它就是为了解决在对象存储方面刚刚我提出的那些问题。首先,对象存储是没有rename语义的,大数据所有的任务在commit的时候都需要先写一个temporary目录,再把它rename出来,最后是commit,这会导致S3上的任务或者对象存储上的任务时间成倍。这个事情他们也做了很多年:刚开始前几年会提出比如commit v1有两次rename,v2就只有一次rename,少了一次rename也会多一些风险。还做过像directoutput的,一次rename也没有,这个问题就更大。过了十年最终提出iceberg就是为了解决这个问题,怎么解决?不需要rename,通过表操作的事务性来解决rename的问题。
List性能差是第二个大问题,比如要提一个新的查询任务,你会发现还没有开始捞数据但任务已经跑了十几分钟,iceberg本身记了list对象存储上的文件列表,所以也不需要COS再从元数据存储里一条一条反馈回来,它本身就是一个文件,所以这个问题自然而然就解决了。
存算分离,失去Locality优势的问题,iceberg其实可以引入一种稀疏索引,构建起来稍微有点复杂,可以利用每个列的值,加上建模的时候做一些事情,以及做谓词下推,一起来完成稀疏索引的排列,性能会非常好。
对象存储最终一致性,简单来说是你写进去一个文件马上去读,读不到。当然这个设计肯定是因为对象存储对本身定位的一些设计,包括要跨az去复制,所以它都是最终一致性的。最近几年云厂商也有一些尝试,都会做对象存储强一致的升级。
Iceberg里因为没有了rename的操作,最终一致性几乎影响不大,有commit的时候写一个文件可能马上就要rename出来,马上rename的时候是读不到的。以及iceberg文件有列表,所以也不会出现list少文件的情况,写10个文件,去读的时候只读出9个,这其实是很严重的事情,但很少能发现。有了iceberg之后,因为存了列表,10个文件就是10个,不会再少。腾讯在hadoop on cos上面还做了一点点优化,如果是hadoop on cos来的请求,我们会打一个单独的,这样这个请求就不会再走缓存,而直接去读强一致的存储。
四、数据湖解决方案
提了传统的不足,我们总结一下现在腾讯云大数据云原生数据湖产品的优势。第一是成本低,这当然是很吸引人的地方,一个是极致弹性计算,有3-5倍的成本优势;另一个是对象存储5-10倍,成本低。第二是性能高,对象存储解决一些小文件的问题,以及缓存加速、稀疏索引、shuffle性能、commit性能,性能高。第三是免运维,DLC和DLF都是用户看不到机器的Serverless形态,只要提SQL、Spark、大数据计算任务就可以,这样减少了很多的运维负担。最后一个点是统一和开放,统一是统一的数据湖存储,不光是DLC、DLF可以用这个数据,EMR、Flink也可以用。统一的数据能给大家带来很多好处,比如成本的下降以及一致性维护的工作也会更少,包括统一元数据是一样的。开放体现在两个点上,叫做联邦分析,我们不需要做入湖,能对TP的一些数据做快速的分析,开放的第二个点更多的是数据湖解决方案。
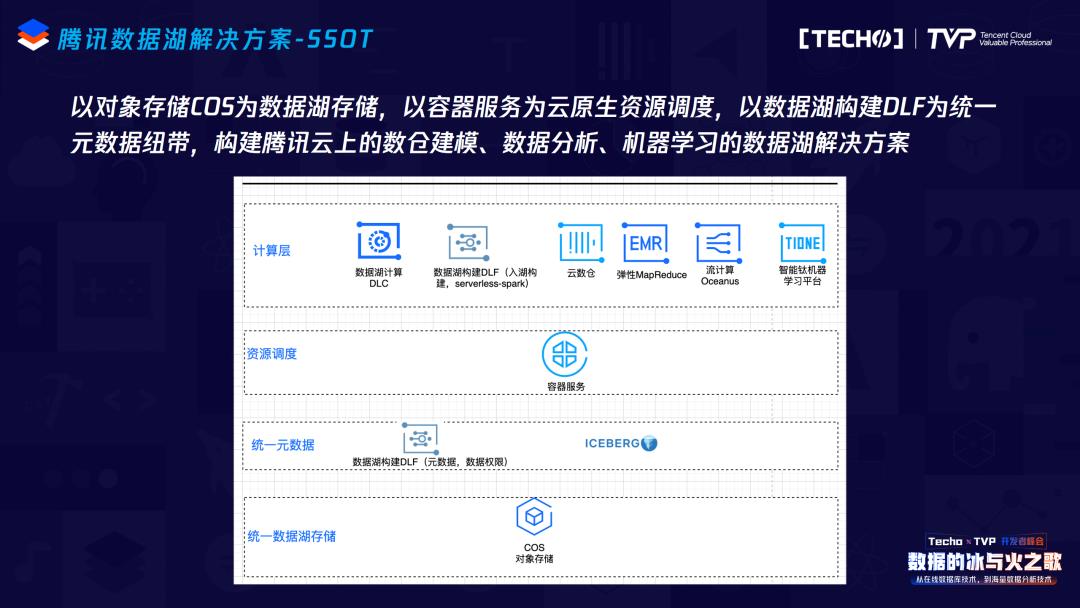
数据湖解决方案核心的架构理念是SSOT,只有一份数据来解决所有问题。这个数据首先是COS上的数据,对象存储上以COS为数据湖存储的数据,大家都可以用,不管是EMR、DLC还是DLF。第二个是DLF统一的元数据也是一份数据,不管是EMR、DLC、DLF。这两个核心的点,加上以容器服务为云原生资源调度的架构,我们满足了数仓建模、数据分析甚至机器学习的整个数据湖的解决方案。
讲师简介

于华丽
腾讯大数据专家工程师
腾讯大数据专家工程师,腾讯云原生数据湖内核研发负责人,负责腾讯云原生数据湖内核架构研发。毕业于复旦大学数学系,有着丰富的公有云大数据经验,打造业界领先的云原生数据湖平台,在数据湖存储、Severless计算、统一元数据方面有丰富落地经验。
点击观看峰会的精彩总结视频????
关注云加社区,回复关键词:“数据”,可获取峰会当天全程回顾视频链接
6月5日,Techo TVP 开发者峰会 ServerlessDays China 2021,即将重磅来袭!
扫码立即参会赢好礼????


以上是关于听说,难于上青天的云原生数据湖能开箱即用了?的主要内容,如果未能解决你的问题,请参考以下文章
数仓架构的持续演进与发展 — 云原生湖仓一体离线实时一体SaaS模式