《EfficientNetV2:Smaller Models and Faster Training》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《EfficientNetV2:Smaller Models and Faster Training》论文笔记相关的知识,希望对你有一定的参考价值。
参考代码:EfficientNetV2
1. 概述
导读:这篇文章是在EfficientNet基础(借鉴了其中一些既有结论)上进行改进优化来的,其主要的优化点有:
1)通过加入training-aware的网络搜索(也就是将网络性能/训练时间/网络参数量组合起来作为NAS的优化目标)去优化网络的训练速度和参数的效率(参数量与最后换得性能的比例);
2)在深度可分离卷积组成的MBConv基础上在浅层的stage上引入Fused-MBConv增加网络的性能与加快训练时间;
3)直觉上增加图像的size会提升网络的性能,而实际上网络采用的正则化机制并没有随着输入图像size的变化而变化,反而导致网络性能的下降,对此文章提出了progressive learning策略去弥补这个gap;
经过上述的改进新版的EfficientNetV2在ImageNet数据集上获得了87.3%的准确率(pretrain on ImageNet21K),并且训练的速度快了很多。
这里将EfficientNetV2的训练速度与其它网络进行对比:
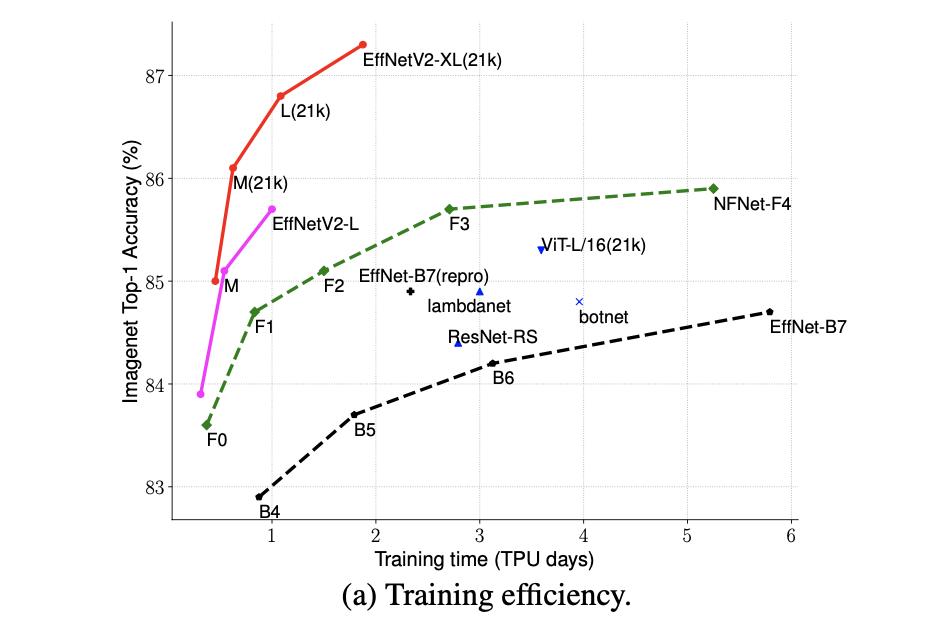
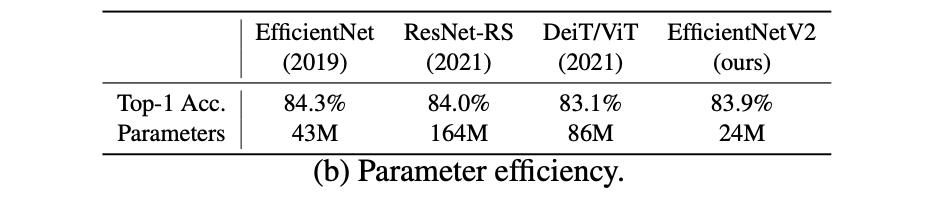
将EfficientNetV2的参数效率与其它网络进行对比:
2. 方法设计
2.1 由EfficientNet带来的思考
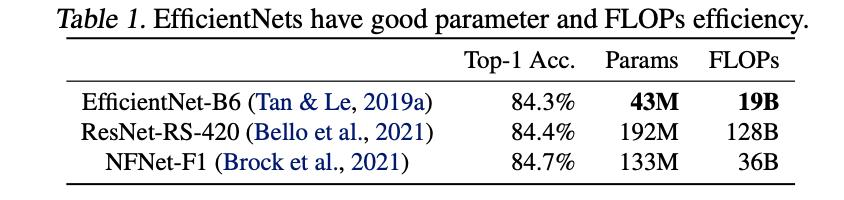
EfficientNet是前几年提出的一个高效网络结构,通过NAS搜索出一个基准网络B0,之后在该基础上通过scale up得到多个不同体量的模型,该类模型在参数量/计算量与最后性能上拥有较好的平衡,将其与其它模型在参数效率上做比较,见下表所示:
文中对EfficientNet进行了深入分析,对其中训练效率的影响因子进行了分析,可以归纳为如下的几个部分。
大尺寸的训练图片拖慢训练:
这与直觉上的认知一致,更大的图片需要占用更多的显存,进而会缩小每次batch的size,使得训练的时间变长,在EfficientNet-B6上进行实验也证实了这样的认知。

浅层的深度可分离卷积拖慢训练:
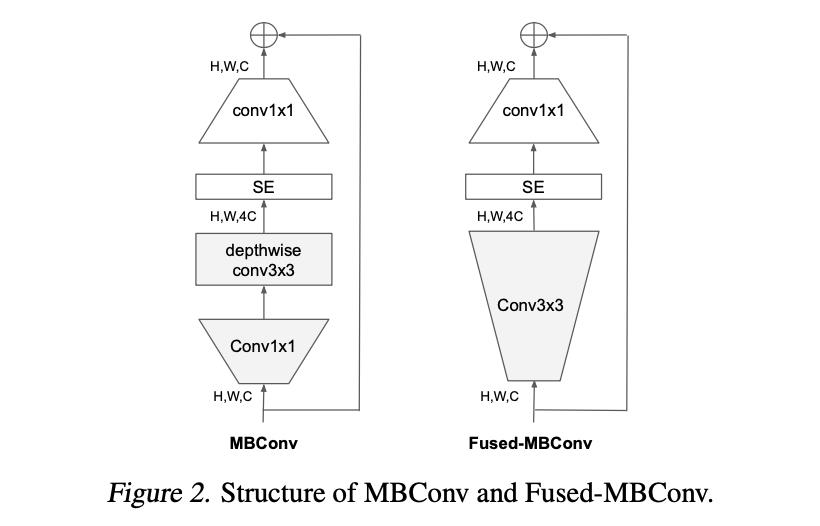
深度可分离卷积是一种轻量化的卷积,通过在channel上split来减少计算量,但是该种结构对于现有的硬件计算框架确是不够友好,这就使得无法很好利用现有的硬件实现速度极致化,对此文章将EfficientNet中的MBConv(带深度可分离卷积)在浅层种替换为了Fused-MBConv(其中使用传统卷积去替换深度可分离卷积),它们之间的对比见下图所示:
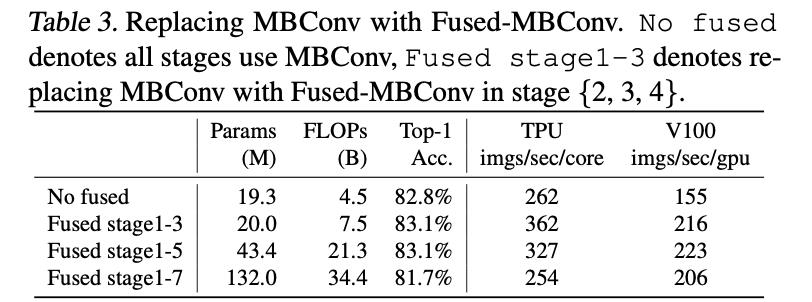
此外,文章进行的实验也显示了使用Fused-MBConv在浅层上对之前的MBConv进行替换会带来速度的提升(同是也会带来一定的计算量和参数量的提升),不同的替换比例得到的结果见下表所示:
EfficientNet种均匀scale策略并不是最优:
在EfficientNet中scale up会在网络stage上从各个维度(channel数量/layer数量/输入尺寸等)进行加倍,但是这样的操作在不同stage上对于最后网络性能提升的贡献却是不均匀的。因而那种均匀scale up的方法是次优的,因而在EfficientNetV2中需要采用一种非均匀的scale up方法。
2.2 Training-aware属性的NAS与网络缩放
NAS网络搜索:
这里进行网络搜索的单元是stage,其中的搜索空间包括:卷积模块的类型(MBConv或Fused-MBConv),stage中layer的数量,卷积kernel的大小3或5,膨胀系数[1,4,6]。此外为了缩小搜索空间文章借鉴了EfficientNet中的一些明了的先验知识(文章的V2版本本来也是基于EfficientNet):
- 1)移除了诸如pooling skip这类非必要的op,因为这类op在EfficientNet中就没有存在;
- 2)重用EfficientNet中搜索的到的channel数;
通过上面的几点操作可以减少搜索空间使得搜索拥有更多layer的网络。最后的代价函数文章将其描述为(综合考虑了精度
A
A
A/训练时长
S
S
S/参数量
P
P
P):
c
o
s
t
=
A
⋅
S
w
⋅
P
w
cost=A\\cdot S^w\\cdot P^w
cost=A⋅Sw⋅Pw
其中,
w
=
−
0.07
,
v
=
−
0.05
w=-0.07,v=-0.05
w=−0.07,v=−0.05。
EfficientNetV2的结构:
最后搜索出来的EfficientNetV2-S的结构见下表所示:
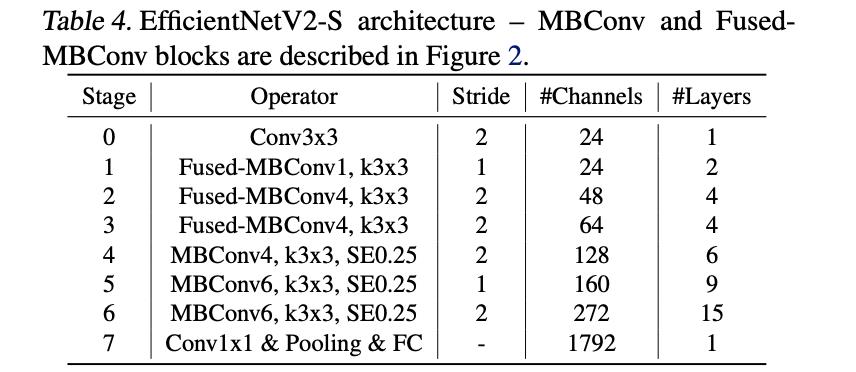
它与EfficientNet的区别主要体现为如下几点:
- 1)V2版本不仅仅是用MBConv,而且在浅层中使用Fused-MBConv,加快训练速度与提升性能;
- 2)V2版本中趋向于选择更小的膨胀系数,从而减少内存的访问量;
- 3)V2版本趋向于选择kernel大小为3的卷积核,但是会增加多个卷积用以提升感受野;
- 4)V2版本移除了最后一个stride为1的stage,从而减少部分参数和内存访问;
EfficientNetV2网络的scale up:
在上述的内容中通过搜索的到EfficientNetV2-S,之后通过scale up对网络进行放大的到更大尺寸的EfficientNetV2-M/L,但是这里做了几点约束:
- 1)限制了输入最大图像尺寸为480,避免大尺寸图片对资源的消耗和加快速度;
- 2)通过在网路的尾部添加layer从而在尽量少的开销情况下增加网络容量;
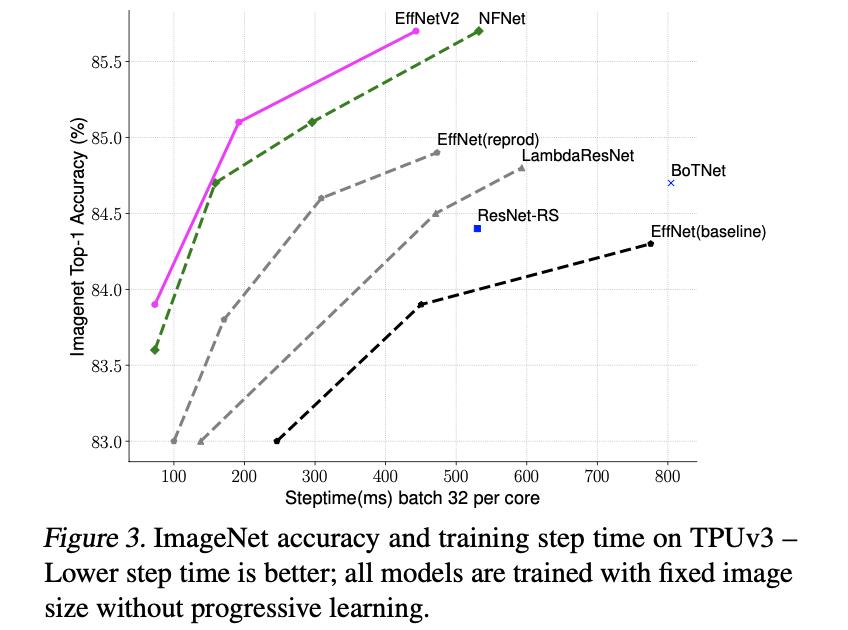
将文章的V2-S/M/L于其它网络进行比较训练时间对比见下图所示:
2.3 progressive learning策略
出发点:
输入图片的size会对最后的结果产生影响,一般意义上这个影响是正向的,但是再增大到一定范围之后却是“负向”的。对此文章给出的解释是随着图像尺寸和网络容量的增加对应的正则化却没有改变,维持着最小时候的设置,这就会导致缺乏有效正则而过拟合的风险,对此文章做了对应的实验,发现在训练的过程中随着图像尺寸的增加也对应增加正则化的力度(这里使用的是不同的图像预处理程度),从而可以得到更好的结果,见下表所示:

具体机制与策略:
从上面的内容中总结出正则化的力度应该随着图像尺寸和网络容量的变化而变化。因此文章设计了一种随网络输入图像尺寸变化正则化力度的策略。这里假设整体的训练step数为
N
N
N,整个的train stage有
M
M
M个,那么在每个对应的stage上对应图像输入尺寸为
S
i
S_i
Si,对应的正则化力度为
Φ
i
=
{
ϕ
i
k
}
\\Phi_i=\\{\\phi_i^k\\}
Φi={ϕik}。那么整体正则化力度与训练stage的变换线性关系可以被描述为下面的算法:

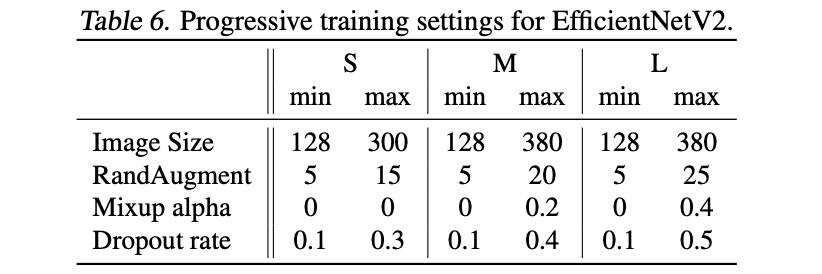
这里在不同stage上正则化力度的选择见下表:
3. 实验结果
文章方法与其它方法的性能比较:
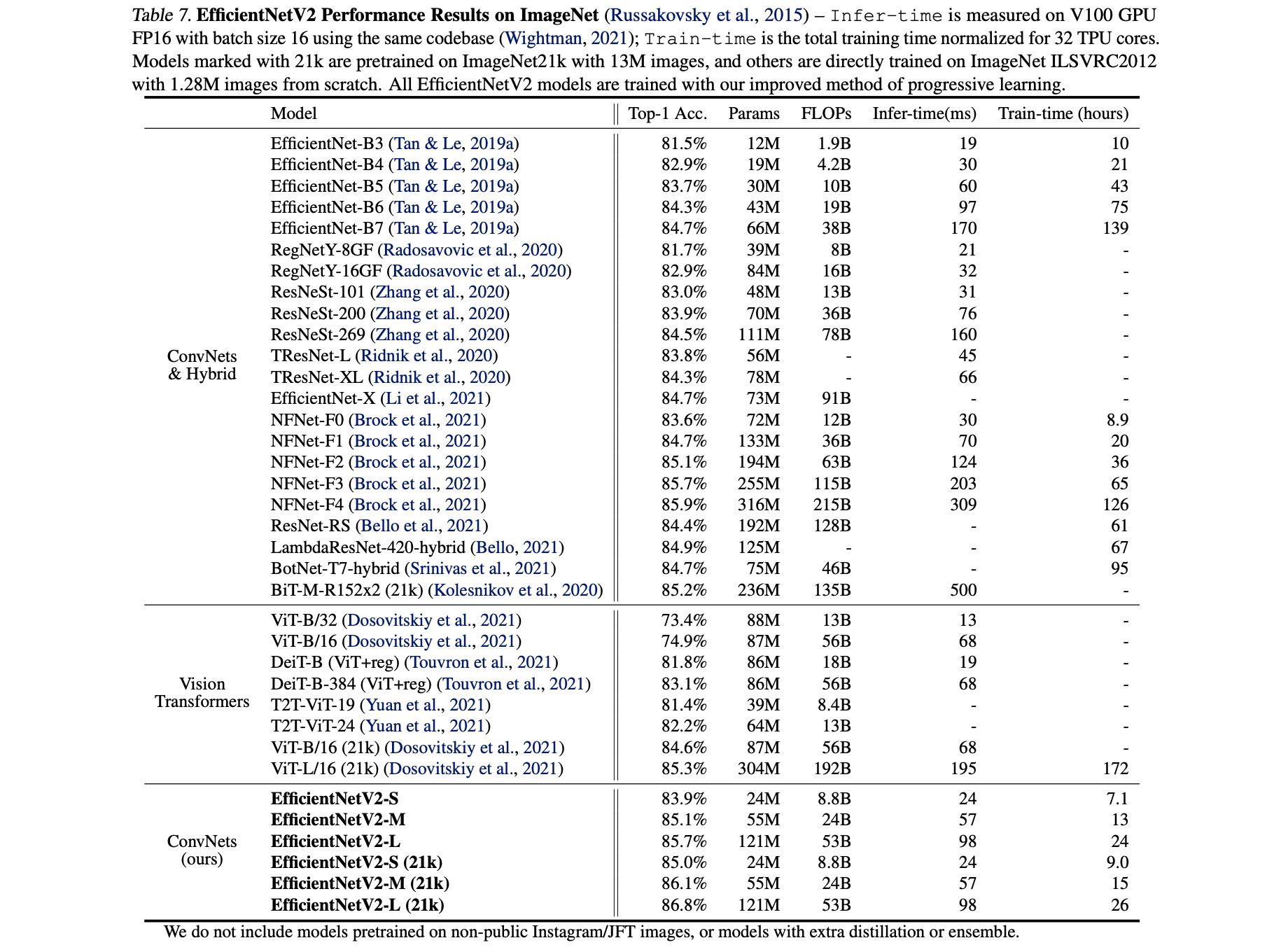
以上是关于《EfficientNetV2:Smaller Models and Faster Training》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章