C/C++ 语言 零碎知识点的总结干货
Posted ~晨曦静竹~
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了C/C++ 语言 零碎知识点的总结干货相关的知识,希望对你有一定的参考价值。
C/C++ 语言 零碎知识点的总结(2)
在大三的有限时间中对自己所遇到过的C/C++知识点做学习记录,以便在自己遗忘之时回顾。
若有朋友想了解其他知识点,传送门:C/C++ 语言 零碎知识点的总结 (1)
首先,来观察下面一段简单的代码:
# include<stdio.h>
int main( int argc,char *argv[] ) {
printf("%d",(unsigned char)-1);
return 0;
}
博主就开门见山了,运行结果:255
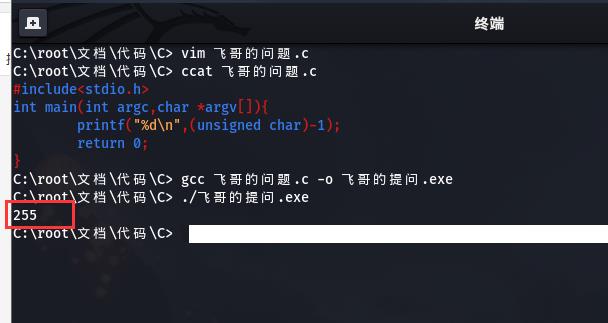
或许会有朋友迷糊了,答案不应该是“-1”么?别急,博主这就为你慢慢解答。
为了具体而又明确的解答该问题,我们需要引入概念: 对C/C++中 char类型数据 做一个新的学习和了解。
C/C++语言中的char类型数据
美国国家标准协会(ANSI)对char的定义是unsigned类型,而不像int/long/short等类型的数据即使不指定signed/unsigned时默认也为signed,这也使得char在C/C++的整型数据中显得最为独特的一个。
ANSI C 提供了3种字符类型: char、signed char、unsigned char,三者均占1个字节(1字节8bit)。
unsigned char,char类型变量的大小通常为1个字节(1字节=8个位),且属于整型。整型的每一种都有无符号(unsigned)和有符号(signed)两种类型(float和double总是带符号的),在默认情况下声明的整型变量都是有符号的类型(char有点特别),如果需要声明无符号类型时就用unsigned关键字对其声明。无符号版本和有符号版本的区别就是无符号类型能保存2倍于有符号类型的数据,比如 16位系统中一个int能存储的数据的范围为-32768~32767,而unsigned能存储的数据范围则是0~65535。
char类型一般为1个字节即8个bit(无论32位或 64位操作系统),所以能存储的数据范围为-128~127,而 unsigned char则是0~255,字符型所存储的数据是用来表示字符的,例如ASCⅡ或Unicode 。
另外,char在标准上虽然被定义为unsigned,但具体有无符号是由编译器所决定的,VC编译器、x86char定义为signed char,而ARM-linux-gcc却把char定义为 unsigned char。
存储:
数据在计算机中是以二进制补码形式储存的,但为了更好的与人交流,编译器通常会以十六进制形式对其处理。
例如,-1在内存中实际上是以“11111111111111111111111111111111”的方式存储的,但编译器会在运算时处理为:0xFFFFFFFF(十六进制)
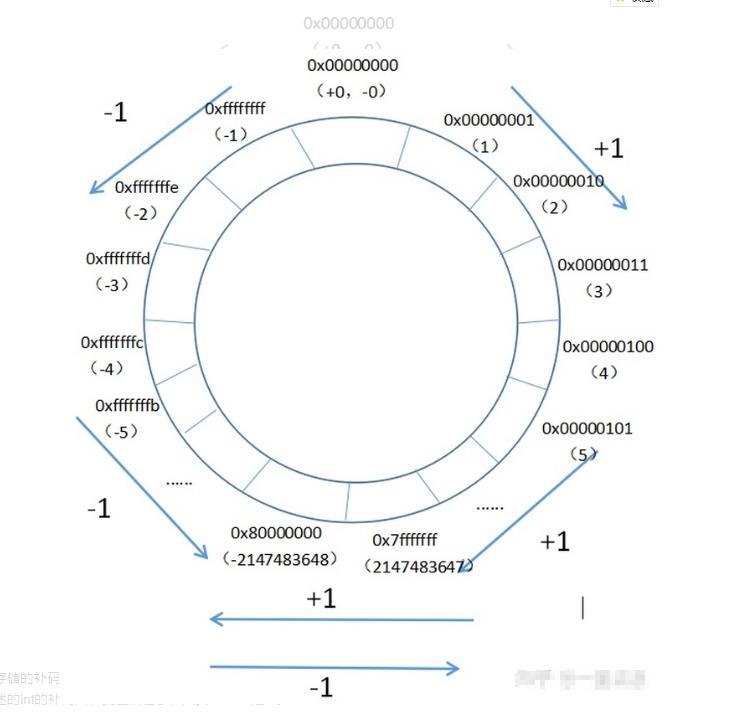
计算机 补码存储顺序 简图
类型转换:
int/unsigned int变量赋值给 unsigned char变量 是会发生字节截断(9位和高于9位的将被程序自动丢弃)。
unsigned int a = 0xFFFFFFF7;
unsigned char b = (unsigned char)a;
此时b的值为 0xF7。
解答:
printf("%d",(unsigned char)-1);
通过简单讲解,我们就清楚了,在前面的代码中 -1 是以 “ 0xFFFFFFFF ” 的形式参与运算的,在被 unsigned char 强制转换后,发生了字节截断 的现象,变成 “0xFF” 的十六进制数,再按“%d”十进制输出时,就是255了,也就是char所能表示的最大范围数,你明白了么?
(Signed)char与unsigned char的区别
我们先来看如下实例代码:
# include <stdio.h>
void f(unsigned char v) {/* 若函数修改写为void f(char v){...}时,
运行效果是一样的,
因为,在普通的赋值,读写文件和网络字节字节流时char和unsigned char是没有区别的,都一个字节8个bit。*/
char c=v;
unsigned char uc = v;
unsigned int a =c,b=uc;
int i=c, j=uc;
printf("--------------\\n");
printf("%%c:%c,%c\\n",c,uc);
printf("%%X:%X,%X\\n",c,uc);
printf("%%u:%u,%u\\n",a,b);
printf("%%d:%d,%d\\n",i,j);
}
int main(){
f(0x61);
f(0x7F);
f(0x80);
return 0;
}
执行结果:
--------------
%c:a,a
%X:61,61
%u:97,97
%d:97,97
--------------
%c:,
%X:7F,7F
%u:127,127
%d:127,127
--------------
%c:�,�
%X:FFFFFF80,80
%u:4294967168,128
%d:-128,128
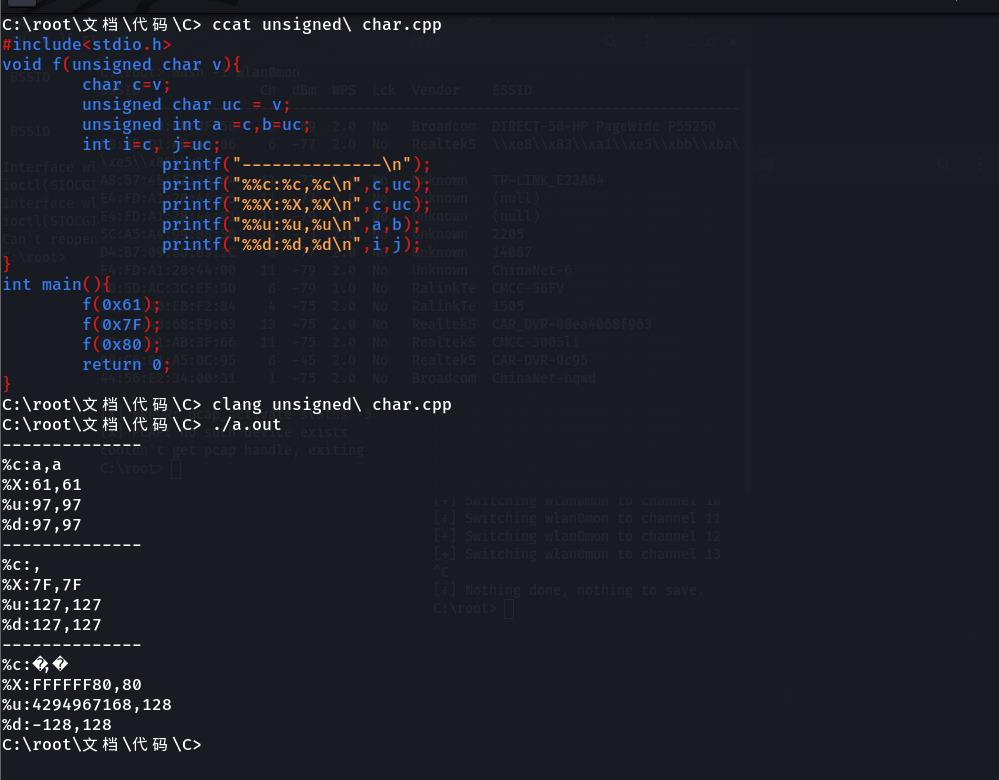
做为初学者,可能会对该代码的运行结果感到困惑,为什么会有如此结果呢?别急,帅气又友善的博主正在为你解答,哈哈哈。
首先明确,在C语言中char是整数类型(integer type),因为在内存中char是整数二进制补码存储的。计算机用特定整数编码来表示特定的字符,其中最能代表的便是ASCLL码值,ASCLL码的取值范围为:0~127, 也就是说 char在0~127范围内为ACSLL码字符。
注意: 这里0~127是指十进制 。
而作为在0~127的数值范围内的字符时,char和unsigontned char是无区别的 !! 这也就很好的理解了,为什么在上述代码中,当传参为 “0x61” 或 “0x7F” 时char和unsigned的运行结果均一样:
0x61的运行结果:
%c:a,a
%X:61,61
%u:97,97
%d:97,97
0x7F的运行结果:
%c:,
%X:7F,7F
%u:127,127
%d:127,127
由于所给字符数值均在ASCLL码的范围内,所以char和unsigned char是没有区别的,char或unsigned char无论赋值给谁,都为ACSLL码表所对应的值:
unsigned int a =c,b=uc;
int i=c, j=uc;
所以此时char或unsigned char无论赋值给int或是unsigned int,效果都是一样的,都为ASCLL码。
不管用何种格式的输出:
printf("%%c:%c,%c\\n",c,uc);
printf("%%X:%X,%X\\n",c,uc);
printf("%%u:%u,%u\\n",a,b);
printf("%%d:%d,%d\\n",i,j);
都对应下图表中:



查询ASCLL码值表,可以看到"0x61" 和 “0x7F” 分别是 字符 ‘a’ 和删除字符DEL,且0x7F是字符所能表示的最大值。
若char的值超出ASCLL码的范围时:
给函数 f 传入参数 "0x80" ,函数实际上变成了:
char c='0x80';
unsigned char uc = '0x80';
unsigned int a =c,b=uc;
int i=c, j=uc;
printf("--------------\\n");
printf("%%c:%c,%c\\n",c,uc);
printf("%%X:%X,%X\\n",c,uc);
printf("%%u:%u,%u\\n",a,b);
printf("%%d:%d,%d\\n",i,j);
结果:
①
--------------
%c:�,�
由于 "0x80" 超出了ascll码所能表示的最大字符,所以出现了未定义字符:“�” 。
②
%X:FFFFFF80,80
%u:4294967168,128
第二、三条输出结果的原因:因为char为signed有符号型字符占1个字节数据,而unsigned int和int是四个字节,当有符号(signed) char低字节的数据给高字节的数unsigned int和int赋值时,会对高位拓展,又因为编译器和系统的预先处理(会以十六进制存储),所以,有符号的char在%X格式输出时会原样输出:FFFFFF80,而十六进制数0xFFFFFF80的十进制为:4294967168,
也就是%u格式输出数。
注意: 变量a是unsigned类型的int,所以无论是%u无符号十进制输出还是%d十进制输出,都会是4294967168 。
不同的是无符型unsigned char在给高字节数据赋值时,无论何种数据,都不会拓展。
总结:
1. char和unsigned char在ASCLL码范围内是一致的,但当超出ASCLL码值就会发生高位扩展,且均以F填补 。
2. 普通的赋值,读写文件和网络字节字节流时char和unsigned char是没有区别的,均是一个字节8个bit
③
%d:-128,128
为什么变量 i 的 “%d” 输出会是-128呢?相信你已理解前文中存储一块的相关介绍了。由于数据是以十六进制存储的,而十六进制凡以F开头的数,均为负数,也就是说char在高位拓展时就已转成了负数,且int是有符型数据,所以,int i无论以何种进制输出,int i均为负。
感谢各位路过的小可爱们能和博主共同学习进步,今天是周天,博主也在教室中对C/C++中char的知识点断断续续的总结完毕了,期待下次跟大家学习分享。
以上是关于C/C++ 语言 零碎知识点的总结干货的主要内容,如果未能解决你的问题,请参考以下文章