Java集合面试经典50问
Posted <一蓑烟雨任平生>
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java集合面试经典50问相关的知识,希望对你有一定的参考价值。
目录
- (1)Arraylist与LinkedList区别
- (2)Collections.sort和Arrays.sort的实现原理
- (3)HashMap原理,java8做了什么改变
- (4)List 和 Set,Map 的区别
- (5)poll()方法和 remove()方法的区别?
- (6)HashMap,HashTable,ConcurrentHash的共同点和区别
- (7)写一段代码在遍历 ArrayList 时移除一个元素
- (8)Java中怎么打印数组?
- (9)TreeMap底层?
- (10)HashMap 的扩容过程
- (11)HashSet是如何保证不重复的
- (12)HashMap 是线程安全的吗,为什么不是线程安全的?死循环问题?
- (13)LinkedHashMap的应用,底层,原理
- (14)哪些集合类是线程安全的?哪些不安全?
- (15)ArrayList 和 Vector 的区别是什么?
- (16)Collection与Collections的区别是什么?
- (17)如何决定使用 HashMap 还是TreeMap?
- (18)如何实现数组和 List之间的转换?
- (19)迭代器 Iterator 是什么?怎么用,有什么特点?
- (20)Iterator 和 ListIterator 有什么区别?
- (21)怎么确保一个集合不能被修改?
- (22)快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
- (23)什么是Java优先级队列(Priority Queue)?
- (24)JAVA8的ConcurrentHashMap为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。
- (25)阻塞队列的实现,ArrayBlockingQueue的底层实现?
- (26)Java 中的 LinkedList是单向链表还是双向链表?
- (27)说一说ArrayList 的扩容机制吧
- (28)HashMap 的长度为什么是2的幂次方,以及其他常量定义的含义
- (29)ConcurrenHashMap 原理?1.8 中为什么要用红黑树?
- (30)ArrayList的默认大小
- (31)为何Collection不从Cloneable和Serializable接口继承?
- (32)Enumeration和Iterator接口的区别?
- (33)我们如何对一组对象进行排序?
- (34)当一个集合被作为参数传递给一个函数时,如何才可以确保函数不能修改它?
- (35)说一下HashSet的实现原理?
- (36)Array 和 ArrayList 有何区别?
- (37)为什么HashMap中String、Integer这样的包装类适合作为key?
- (38)如果想用Object作为hashMap的Key?
- (39)讲讲红黑树的特点?
- (40) Java集合类框架的最佳实践有哪些?
- (41)谈谈线程池阻塞队列吧~
- (42)HashSet和TreeSet有什么区别?
- (43)Set里的元素是不能重复的,那么用什么方法来区分重复与否呢? 是用==还是equals()?
- (44)说出ArrayList,LinkedList的存储性能和特性
- (45)HashMap在JDK1.7和JDK1.8中有哪些不同?
- (46)ArrayList集合加入1万条数据,应该怎么提高效率
- (47)如何对Object的list排序
- (48)ArrayList 和 HashMap 的默认大小是多数?
- (49)有没有有顺序的Map实现类,如果有,他们是怎么保证有序的
- (50)HashMap是怎么解决哈希冲突的
(1)Arraylist与LinkedList区别
可以从它们的底层数据结构、效率、开销进行阐述
- ArrayList是数组的数据结构,LinkedList是链表的数据结构。
- 随机访问的时候,ArrayList的效率比较高,因为LinkedList要移动指针,而ArrayList是基于索引(index)的数据结构,可以直接映射到。
- 插入、删除数据时,LinkedList的效率比较高,因为ArrayList要移动数据。
- LinkedList比ArrayList开销更大,因为LinkedList的节点除了存储数据,还需要存储引用。
(2)Collections.sort和Arrays.sort的实现原理
Collection.sort是对list进行排序,Arrays.sort是对数组进行排序。
Collections.sort底层实现
Collections.sort方法调用了list.sort方法

list.sort方法调用了Arrays.sort的方法
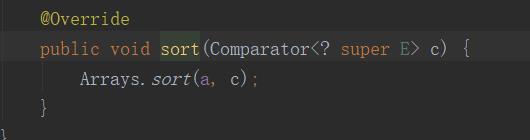
因此,Collections.sort方法底层就是调用的Array.sort方法
Arrays.sort底层实现
Arrays的sort方法,如下:
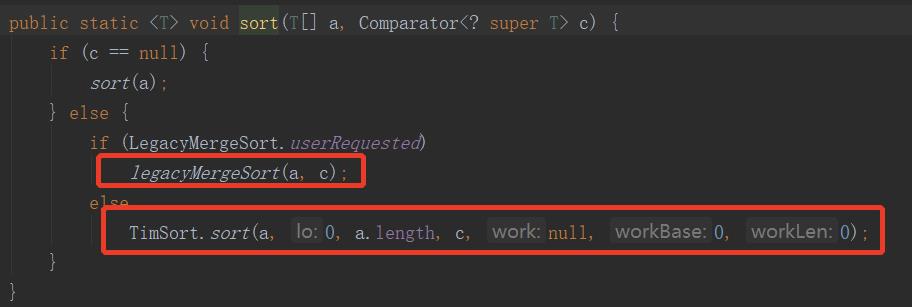
如果比较器为null,进入sort(a)方法。如下:
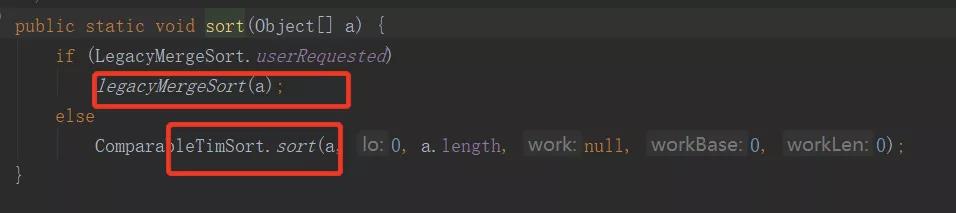
因此,Arrays的sort方法底层就是:
- legacyMergeSort(a),归并排序
- ComparableTimSort.sort():即Timsort排序。
Timesort排序
Timsort排序是结合了合并排序(merge.sort)和插入排序(insertion sort)而得出的排序方法;
1.当数组长度小于某个值,采用的是二分插入排序算法,如下:
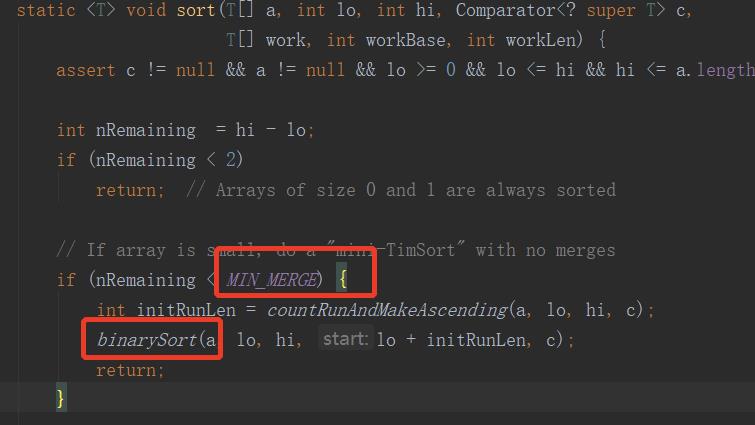
2.找到各个run,并入栈。
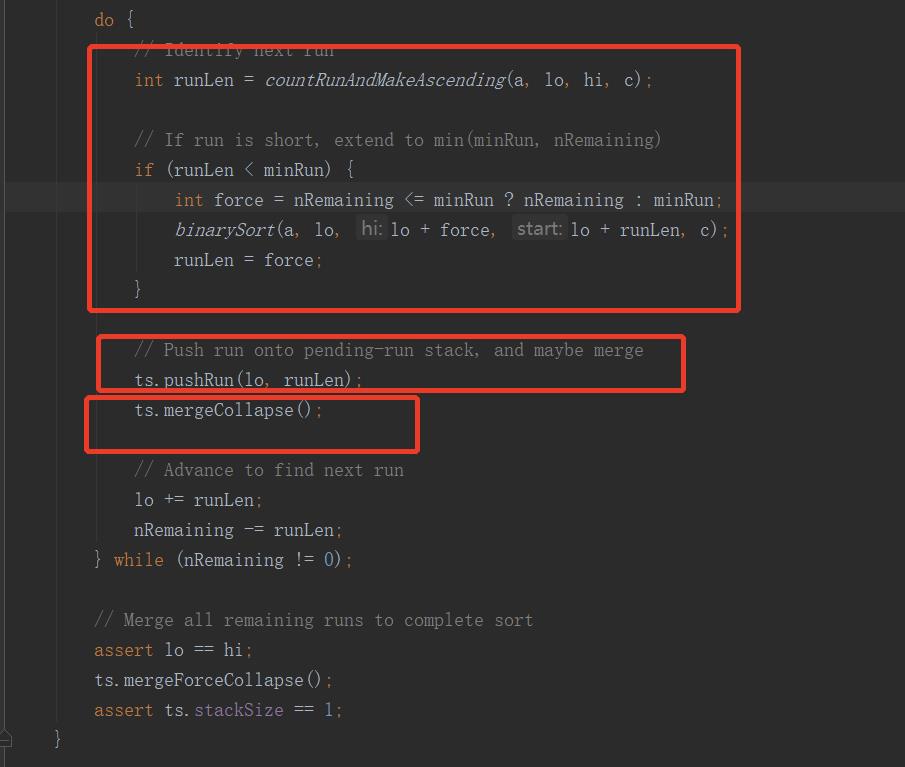
3.按规则合并run。

(3)HashMap原理,java8做了什么改变
- HashMap是以键值对存储数据的集合容器
- HashMap是非线性安全的。
- HashMap底层数据结构:数组+(链表、红黑树),jdk8之前是用数组+链表的方式实现,jdk8引进了红黑树
- HashMap数组的默认初始长度是16,key和value都允许null的存在
- HashMap的内部实现数组是Node[]数组,上面存放的是key-value键值对的节点。HashMap通过put和get方法存储和获取。
- HashMap的put方法,首先计算key的hashcode值,定位到对应的数组索引,然后再在该索引的单向链表上进行循环遍历,用equals比较key是否存在,如果存在则用新的value覆盖原值,如果没有则向后追加。
- jdk8中put方法:先判断HashMap是否为空,为空就扩容,不为空计算出key的hash值i,然后看table[i]是否为空,为空就直接插入,不为空判断当前位置的key和table[i]是否相同,相同就覆盖,不相同就查看table[i]是否是红黑树节点,如果是的话就用红黑树直接插入键值对,如果不是开始遍历链表插入,如果遇到重复值就覆盖,否则直接插入,如果链表长度大于8,转为红黑树结构,执行完成后看size是否大于阈值threshold,大于就扩容,否则直接结束。
- HashMap解决hash冲突,使用的是链地址法,即数组+链表的形式来解决。put执行首先判断table[i]位置,如果为空就直接插入,不为空判断和当前值是否相等,相等就覆盖,如果不相等的话,判断是否是红黑树节点,如果不是,就从table[i]位置开始遍历链表,相等覆盖,不相等插入。
- HashMap的get方法就是计算出要获取元素的hash值,去对应位置获取即可。
- HashMap的扩容机制,HashMap的扩容中主要进行两步,第一步把数组长度变为原来的两倍,第二步把旧数组的元素重新计算hash插入到新数组中,jdk8时,不用重新计算hash,只用看看原来的hash值新增的一位是零还是1,如果是1这个元素在新数组中的位置,是原数组的位置加原数组长度,如果是零就插入到原数组中。扩容过程第二步一个非常重要的方法是transfer方法,采用头插法,把旧数组的元素插入到新数组中。
- HashMap大小为什么是2的幂次方?效率高+空间分布均匀
(4)List 和 Set,Map 的区别
- List 以索引来存取元素,有序的,元素是允许重复的,可以插入多个null。
- Set 不能存放重复元素,无序的,只允许一个null
- Map 保存键值对映射,映射关系可以一对一、多对一
- List 有基于数组、链表实现两种方式
- Set、Map 容器有基于哈希存储和红黑树两种方式实现
- Set 基于 Map 实现,Set 里的元素值就是 Map的键值
(5)poll()方法和 remove()方法的区别?
Queue队列中,poll() 和 remove() 都是从队列中取出一个元素,在队列元素为空的情况下,remove() 方法会抛出异常,poll() 方法只会返回 null 。
/**
* Retrieves and removes the head of this queue. This method differs
* from {@link #poll poll} only in that it throws an exception if this
* queue is empty.
*
* @return the head of this queue
* @throws NoSuchElementException if this queue is empty
*/
E remove();
/**
* Retrieves and removes the head of this queue,
* or returns {@code null} if this queue is empty.
*
* @return the head of this queue, or {@code null} if this queue is empty
*/
E poll();
(6)HashMap,HashTable,ConcurrentHash的共同点和区别
HashMap
- 底层由链表+数组+红黑树实现
- 可以存储null键和null值
- 线性不安全
- 初始容量为16,扩容每次都是2的n次幂
- 加载因子为0.75,当Map中元素总数超过Entry数组的0.75,触发扩容操作.
- 并发情况下,HashMap进行put操作会引起死循环,导致CPU利用率接近100%
- HashMap是对Map接口的实现
HashTable
- HashTable的底层也是由链表+数组+红黑树实现。
- 无论key还是value都不能为null
- 它是线性安全的,使用了synchronized关键字。
- HashTable实现了Map接口和Dictionary抽象类
- Hashtable初始容量为11
ConcurrentHashMap
- ConcurrentHashMap的底层是数组+链表+红黑树
- 不能存储null键和值
- ConcurrentHashMap是线程安全的
- ConcurrentHashMap使用锁分段技术确保线性安全
- JDK8为何又放弃分段锁,是因为多个分段锁浪费内存空间,竞争同一个锁的概率非常小,分段锁反而会造成效率低。
(7)写一段代码在遍历 ArrayList 时移除一个元素
安全删除元素:
- 使用普通for循环可以删除不相同元素
- 可以使用迭代器删除元素
- 使用jdk8推出的新接口removeIf接口
不安全删除元素:
- 使用普通for循环删除相同元素会删除不干净
- 使用增强for循环删除元素会抛出并发修改异常
(8)Java中怎么打印数组?
数组是不能直接打印的,如下:
public class Test {
public static void main(String[] args) {
String[] jayArray = {"jay", "boy"};
System.out.println(jayArray);
}
}
//output
[Ljava.lang.String;@1540e19d
打印数组可以用流的方式Strem.of().foreach(),如下:
public class Test {
public static void main(String[] args) {
String[] jayArray = {"jay", "boy"};
Stream.of(jayArray).forEach(System.out::println);
}
}
//output
jay
boy
打印数组,最优雅的方式可以用这个APi,Arrays.toString()
public class Test {
public static void main(String[] args) {
String[] jayArray = {"jay", "boy"};
System.out.println(Arrays.toString(jayArray));
}
}
//output
[jay, boy]
(9)TreeMap底层?
- TreeMap实现了SotredMap接口,它是有序的集合。
- TreeMap底层数据结构是一个红黑树,每个key-value都作为一个红黑树的节点。
- 如果在调用TreeMap的构造函数时没有指定比较器,则根据key执行自然排序。
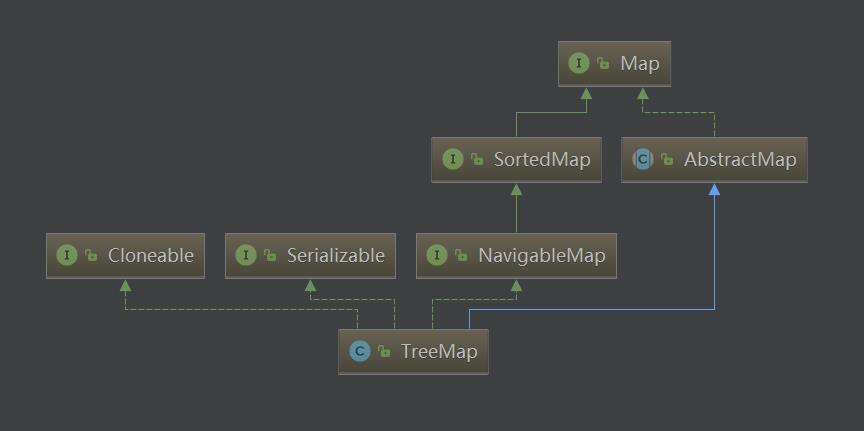
(10)HashMap 的扩容过程
Hashmap的扩容:
- 第一步把数组长度变为原来的两倍
- 第二步把旧数组的元素重新计算hash插入到新数组中。
- jdk8时,不用重新计算hash,只用看看原来的hash值新增的一位是零还是1,如果是1这个元素在新数组中的位置,是原数组的位置加原数组长度,如果是零就插入到原数组中。扩容过程第二步一个非常重要的方法是transfer方法,采用头插法,把旧数组的元素插入到新数组中。
(11)HashSet是如何保证不重复的
可以看一下HashSet的add方法,元素E作为HashMap的key,我们都知道HashMap是不允许重复的
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
(12)HashMap 是线程安全的吗,为什么不是线程安全的?死循环问题?
不是线性安全的。
并发的情况下,扩容可能导致死循环问题。
(13)LinkedHashMap的应用,底层,原理
- LinkedHashMap维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可以是插入顺序(insert-order)或者是访问顺序,其中默认的迭代访问顺序就是插入顺序,即可以按插入的顺序遍历元素,这点和HashMap有很大的不同。
- LRU算法可以用LinkedHashMap实现。
(14)哪些集合类是线程安全的?哪些不安全?
线性安全的
- Vector:比Arraylist多了个同步化机制。
- Hashtable:比Hashmap多了个线程安全。
- ConcurrentHashMap:是一种高效但是线程安全的集合。
- Stack:栈,也是线程安全的,继承于Vector。
线性不安全的
- Hashmap
- Arraylist
- LinkedList
- HashSet
- TreeSet
- TreeMap
(15)ArrayList 和 Vector 的区别是什么?
- Vector是线程安全的,ArrayList不是线程安全的。
- ArrayList在底层数组不够用时在原来的基础上扩展0.5倍,Vector是扩展1倍。
- Vector只要是关键性的操作,方法前面都加了synchronized关键字,来保证线程的安全性。
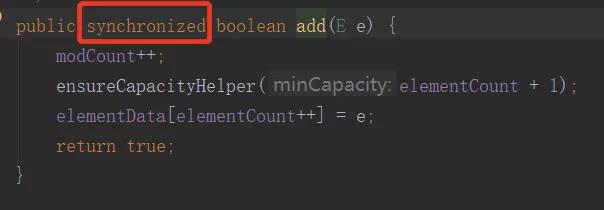
(16)Collection与Collections的区别是什么?
Collection是Java集合框架中的基本接口,如List接口也是继承于它
public interface List<E> extends Collection<E> {
Collections是Java集合框架提供的一个工具类,其中包含了大量用于操作或返回集合的静态方法。如下
public static <T extends Comparable<? super T>> void sort(List<T> list) {
list.sort(null);
}
(17)如何决定使用 HashMap 还是TreeMap?
这个点,主要考察HashMap和TreeMap的区别。
TreeMap实现SortMap接口,能够把它保存的记录根据键排序,默认是按key的升序排序,也可以指定排序的比较器。当用Iterator遍历TreeMap时,得到的记录是排过序的。
- 对于在 Map 中插入、删除、定位一个元素这类操作,选HashMap
- 要对一个 key 集合进行有序的遍历,选TreeMap
(18)如何实现数组和 List之间的转换?
List 转 Array
List 转Array,必须使用集合的 toArray(T[] array),如下:
List<String> list = new ArrayList<String>();
list.add("jay");
list.add("tianluo");
// 使用泛型,无需显式类型转换
String[] array = list.toArray(new String[list.size()]);
System.out.println(array[0]);
如果直接使用 toArray 无参方法,返回值只能是 Object[] 类,强转其他类型可能有问题,demo如下:
List<String> list = new ArrayList<String>();
list.add("jay");
list.add("tianluo");
String[] array = (String[]) list.toArray();
System.out.println(array[0]);
运行结果:
Exception in thread "main" java.lang.ClassCastException: [Ljava.lang.Object; cannot be cast to [Ljava.lang.String;
at Test.main(Test.java:14)
Array 转List
使用Arrays.asList() 把数组转换成集合时,不能使用修改集合相关的方法,如下:
String[] str = new String[] { "jay", "tianluo" };
List list = Arrays.asList(str);
list.add("boy");
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.AbstractList.add(AbstractList.java:148)
at java.util.AbstractList.add(AbstractList.java:108)
at Test.main(Test.java:13)
因为 Arrays.asList不是返回java.util.ArrayList,而是一个内部类ArrayList。
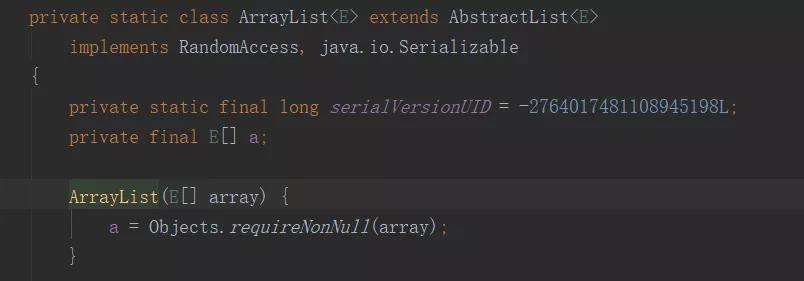
可以这样使用弥补这个缺点:
//方式一:
ArrayList< String> arrayList = new ArrayList<String>(strArray.length);
Collections.addAll(arrayList, strArray);
//方式二:
ArrayList<String> list = new ArrayList<String>(Arrays.asList(strArray)) ;
(19)迭代器 Iterator 是什么?怎么用,有什么特点?
public interface Collection<E> extends Iterable<E> {
Iterator<E> iterator();
方法如下:
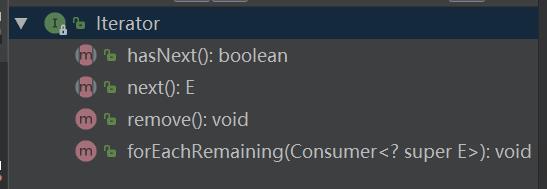
next() 方法获得集合中的下一个元素
hasNext() 检查集合中是否还有元素
remove() 方法将迭代器新返回的元素删除
forEachRemaining(Consumer<? super E> action) 方法,遍历所有元素
Iterator 主要是用来遍历集合用的,它的特点是更加安全,因为它可以确保,在当前遍历的集合元素被更改的时候,就会抛出 ConcurrentModificationException 异常。
使用demo如下:
List<String> list = new ArrayList<>();
Iterator<String> it = list. iterator();
while(it. hasNext()){
String obj = it. next();
System. out. println(obj);
}
(20)Iterator 和 ListIterator 有什么区别?
- ListIterator 比 Iterator有更多的方法。
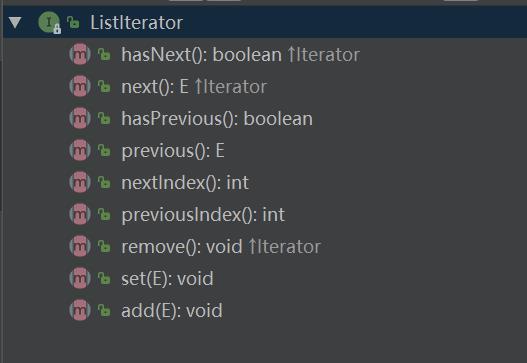
- ListIterator只能用于遍历List及其子类,Iterator可用来遍历所有集合,
- ListIterator遍历可以是逆向的,因为有previous()和hasPrevious()方法,而Iterator不可以。
- ListIterator有add()方法,可以向List添加对象,而Iterator却不能。
- ListIterator可以定位当前的索引位置,因为有nextIndex()和previousIndex()方法,而Iterator不可以。
- ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历,不能修改。
(21)怎么确保一个集合不能被修改?
- unmodifiableMap
- unmodifiableList
- unmodifiableSet
再看一下demo吧
public class Test {
private static Map<Integer, String> map = new HashMap<Integer, String>();
{
map.put(1, "jay");
map.put(2, "tianluo");
}
public static void main(String[] args) {
map = Collections.unmodifiableMap(map);
map.put(1, "boy");
System.out.println(map.get(1));
}
}
运行结果:
// 可以发现,unmodifiableMap确保集合不能修改啦,抛异常了
Exception in thread "main" java.lang.UnsupportedOperationException
at java.util.Collections$UnmodifiableMap.put(Collections.java:1457)
at Test.main(Test.java:14)
(22)快速失败(fail-fast)和安全失败(fail-safe)的区别是什么?
快速失败
在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、删除、修改),则会抛出Concurrent Modification Exception。
public class Test {
public static void main(String[] args) {
List<Integer> list = new ArrayList<>();
list.add(1);
list.add(2);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
list.add(3);
System.out.println(list.size());
}
}
}
运行结果:
1
Exception in thread "main" java.util.ConcurrentModificationException
3
at java.util.ArrayList$Itr.checkForComodification(ArrayList.java:909)
at java.util.ArrayList$Itr.next(ArrayList.java:859)
at Test.main(Test.java:12)
安全失败
采用安全失败机制的集合容器,在遍历时不是直接在集合内容上访问的,而是先复制原有集合内容,在拷贝的集合上进行遍历。
public class Test {
public static void main(String[] args) {
List<Integer> list = new CopyOnWriteArrayList<>();
list.add(1);
list.add(2);
Iterator iterator = list.iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
list.add(3);
System.out.println("list size:"+list.size());
}
}
}
运行结果:
1
list size:3
2
list size:4
其实,在java.util.concurrent 并发包的集合,如 ConcurrentHashMap, CopyOnWriteArrayList等,默认为都是安全失败的。
(23)什么是Java优先级队列(Priority Queue)?
优先队列PriorityQueue是Queue接口的实现,可以对其中元素进行排序
- 优先队列中元素默认排列顺序是升序排列
- 但对于自己定义的类来说,需要自己定义比较器
public class PriorityQueue<E> extends AbstractQueue<E>
implements java.io.Serializable {
...
private final Comparator<? super E> comparator;
方法:
peek()//返回队首元素
poll()//返回队首元素,队首元素出队列
add()//添加元素
size()//返回队列元素个数
isEmpty()//判断队列是否为空,为空返回true,不空返回false
特点:
- 基于优先级堆
- 不允许null值
- 线程不安全
- 出入队时间复杂度O(log(n))
- 调用remove()返回堆内最小值
(24)JAVA8的ConcurrentHashMap为什么放弃了分段锁,有什么问题吗,如果你来设计,你如何设计。
jdk8 放弃了分段锁而是用了Node锁,减低锁的粒度,提高性能,并使用CAS操作来确保Node的一些操作的原子性,取代了锁。
(25)阻塞队列的实现,ArrayBlockingQueue的底层实现?
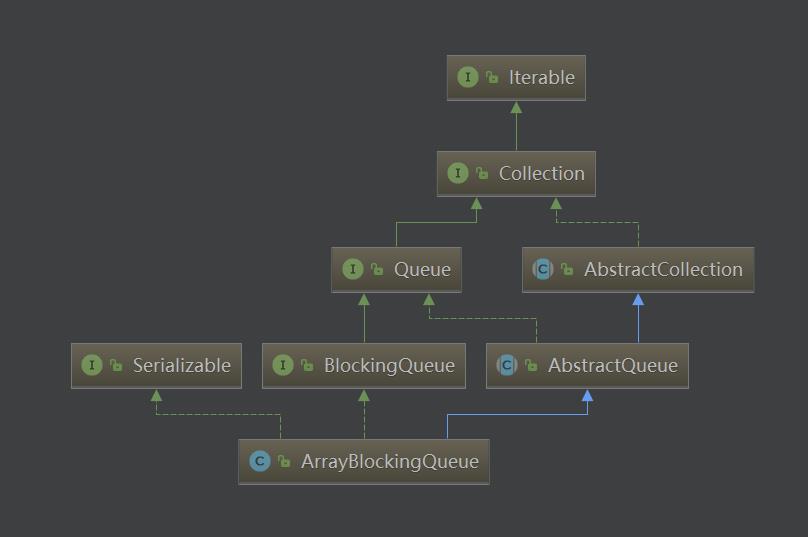
ArrayBlockingQueue是数组实现的线程安全的有界的阻塞队列,继承自AbstractBlockingQueue,间接的实现了Queue接口和Collection接口。底层以数组的形式保存数据(实际上可看作一个循环数组)。常用的操作包括 add ,offer,put,remove,poll,take,peek。
(26)Java 中的 LinkedList是单向链表还是双向链表?
是双向链表,看源码
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
(27)说一说ArrayList 的扩容机制吧
ArrayList扩容的本质就是计算出新的扩容数组的size后实例化,并将原有数组内容复制到新数组中去。
public boolean add(E e) {
//扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
private void ensureCapacityInternal(int minCapacit以上是关于Java集合面试经典50问的主要内容,如果未能解决你的问题,请参考以下文章