Elasticsearch:理解 Elastic Maps 中的 geohash 及其聚合
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:理解 Elastic Maps 中的 geohash 及其聚合相关的知识,希望对你有一定的参考价值。
在我们使用 Elastic Maps 时,经常会遇到 geohash。通常当我们描述一个位置的时候,我们很习惯使用经纬度来描述一个位置。在 Elasticsearch 中,有一个叫做 geo_point 的数据类型。例如,我们可以定义如下的一个索引:
PUT my-index-000001
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}在上面,我们创建一个叫做 my-index-000001 的索引。在它的 mapping 中,我们定义了一个叫做 location 的字段。它的类型为 geo_point。针对 location,我们有各种各样的方式来对它写入,比如:
PUT my-index-000001/_doc/1
{
"text": "Geo-point as an object",
"location": {
"lat": 41.12,
"lon": -71.34
}
}在上面,我们定义 location 为一个 object。我们也可以使用如下的方式来定义一个 geo_point:
PUT my-index-000001/_doc/2
{
"text": "Geo-point as a string",
"location": "41.42, -71.34"
}在上面,我们使用一个字符串来定义 location。这里需要注意的是维度在前,经度在后。否则导入的数据会有错误。我们还可以使用如下的形式来定义:
PUT my-index-000001/_doc/3
{
"text": "Geo-point as an array",
"location": [-71.34, 41.12]
}在上面,我们使用一个数组来定义 location。必须指出的是,在这种情况下,经度在前面,维度在后面。我们也可以使用如下的格式来定义:
PUT my-index-000001/_doc/4
{
"text": "Geo-point as a WKT POINT primitive",
"location": "POINT(-71.34 41.12)"
}在上面,我们使用 POINT 来定义一个 location。
最后,我们甚至可以使用 geohash 来定义一个位置:
PUT my-index-000001/_doc/5
{
"text": "Geo-point as a geohash",
"location": "drm3btev3e86"
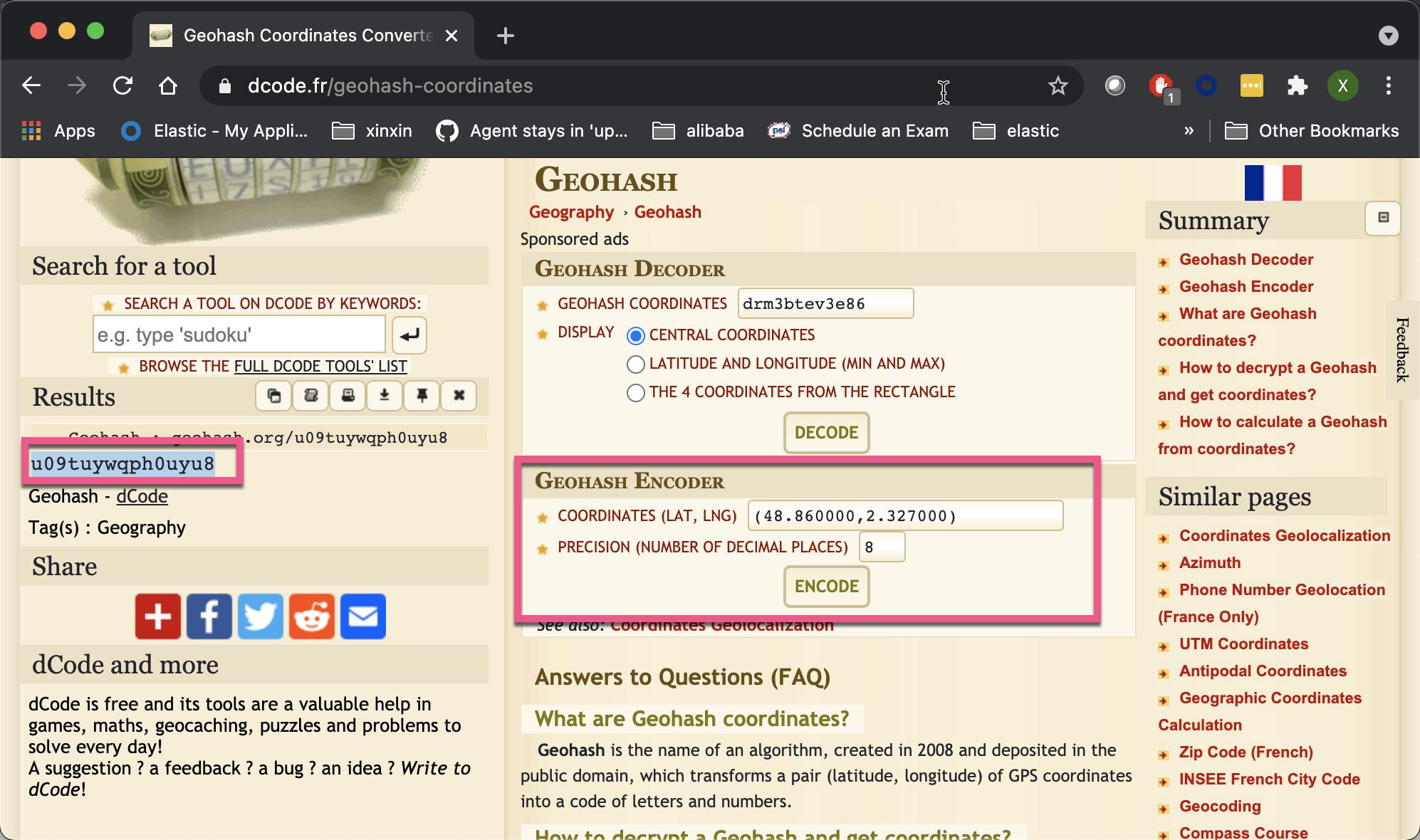
}到这里,肯定有些开发者开始懵圈了。geohash 这到底是啥东东啊?我们可以打开网站 https://www.dcode.fr/geohash-coordinates。我们把上面的 geohash 代码输入到页面中,并求出相应的经纬度:
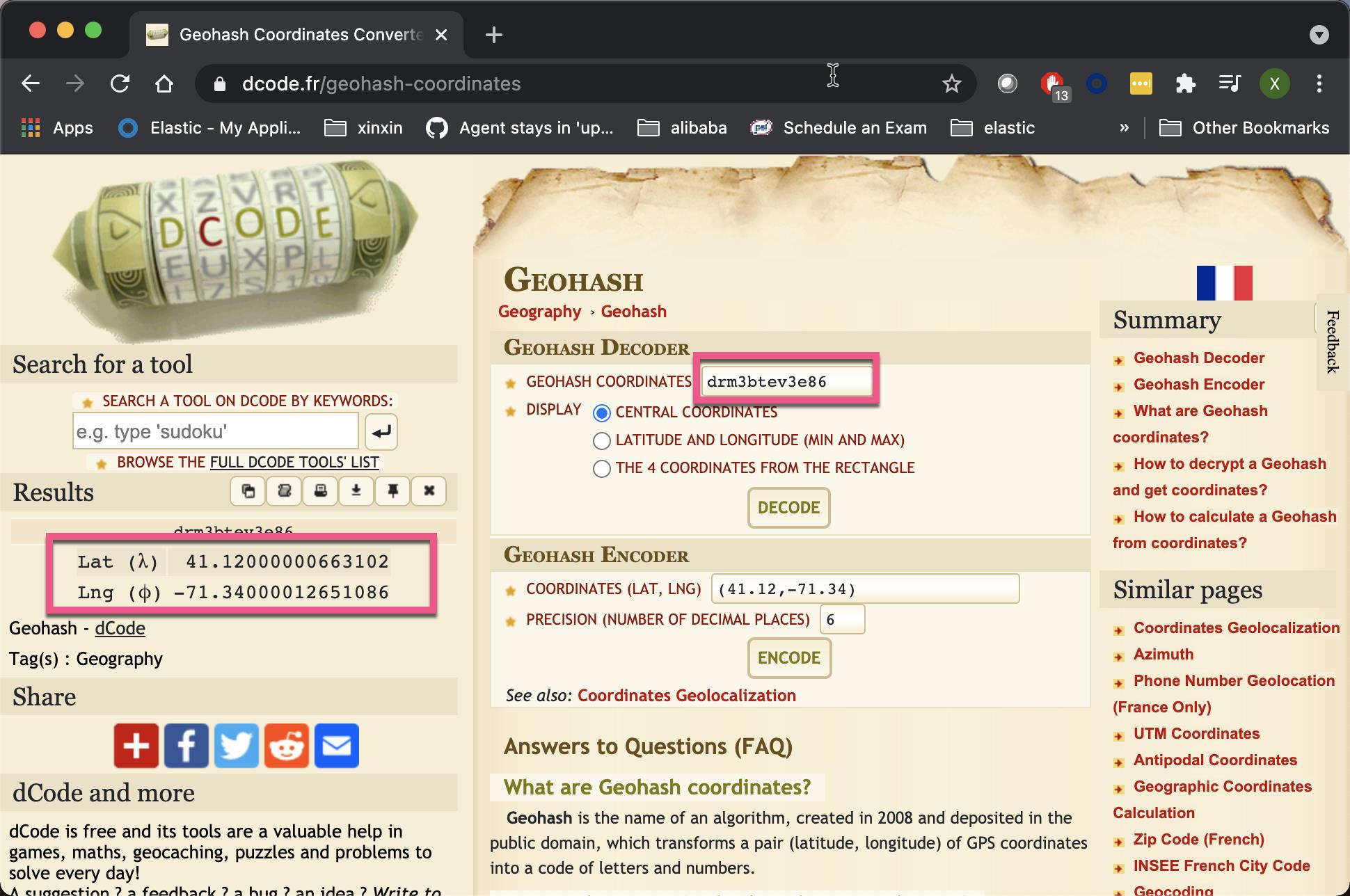
当然,我们也可以把经纬度信息写入,并求出相应的 geohash 代码:

显然这个 geohash 代表的就是我们上面所见到的(41.12,-71.34)经纬度坐标。
我们甚至可以到地址 https://www.movable-type.co.uk/scripts/geohash.html 输入我们的经纬度,并查出相应的位置信息:
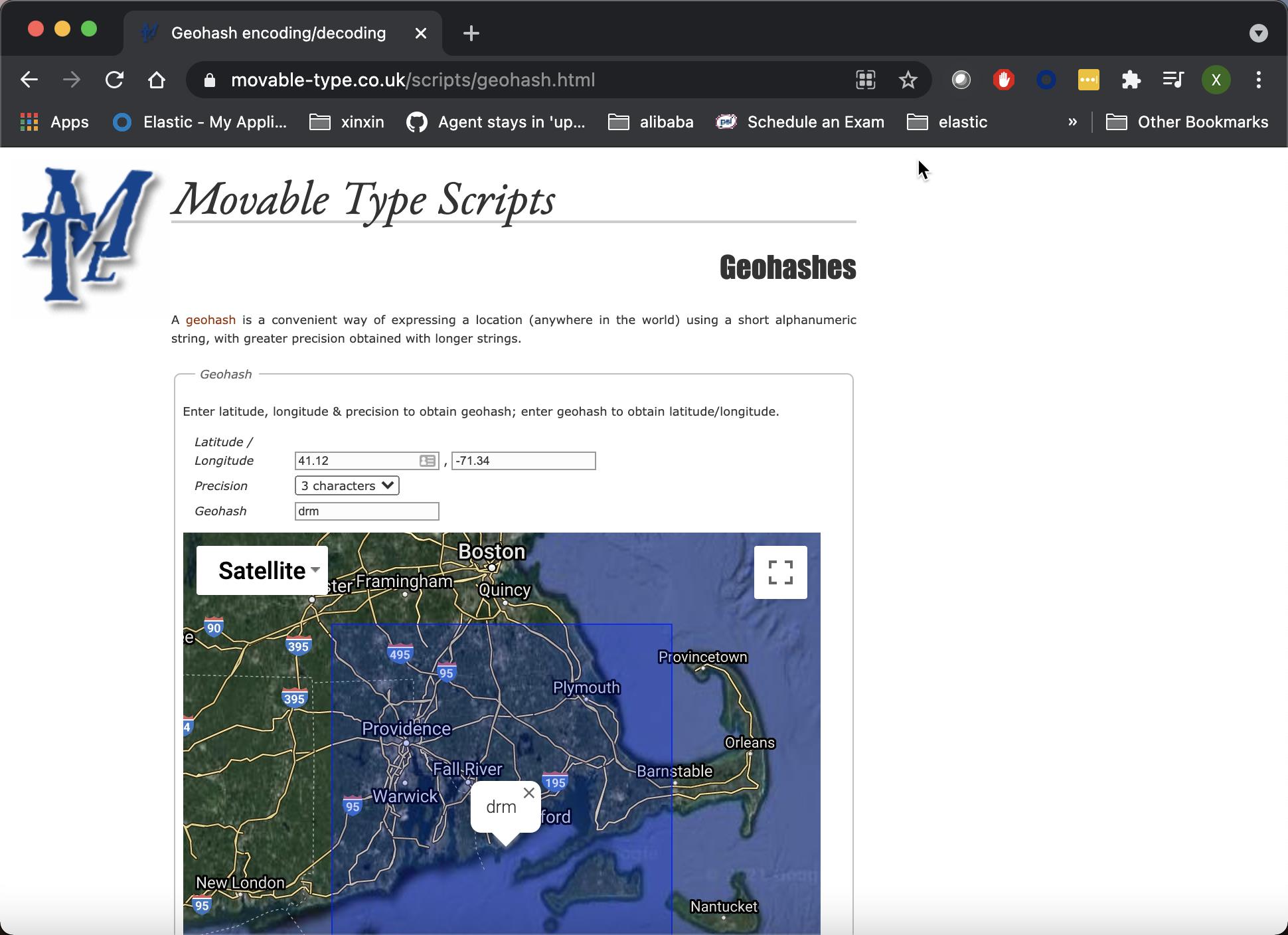
那么 geohash 代码到底是怎么形成的呢?
Geohash 到底是什么?
Geohashing 是一种地理编码方法,用于将地理坐标(纬度和经度)编码为一小段数字和字母,以不同的分辨率在地图上划定一个区域(称为像元)。 字符串中的字符越多,位置越精确。Geohash 是 Gustavo Niemeyer在构建 geohash.org 时发明的系统,如下图所示:

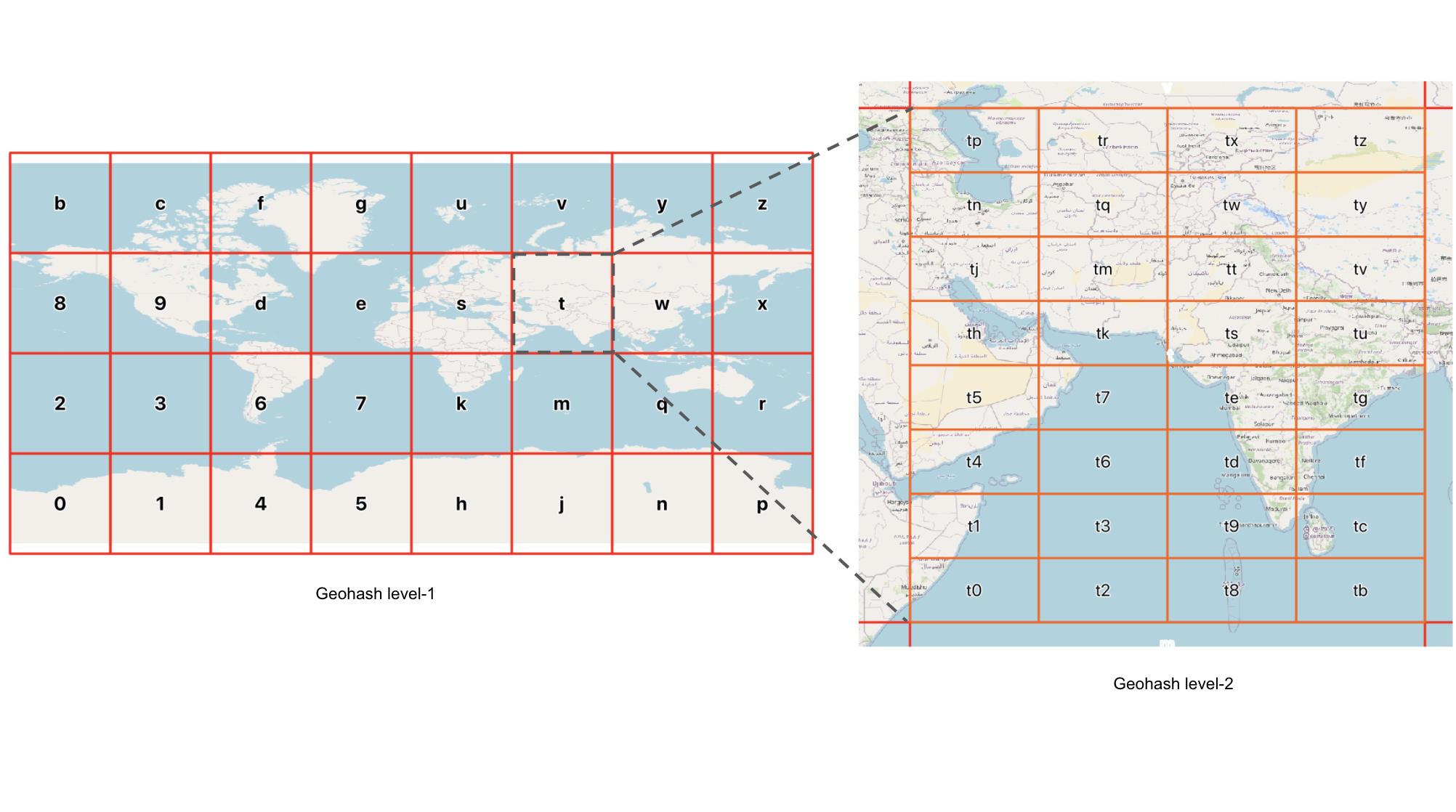
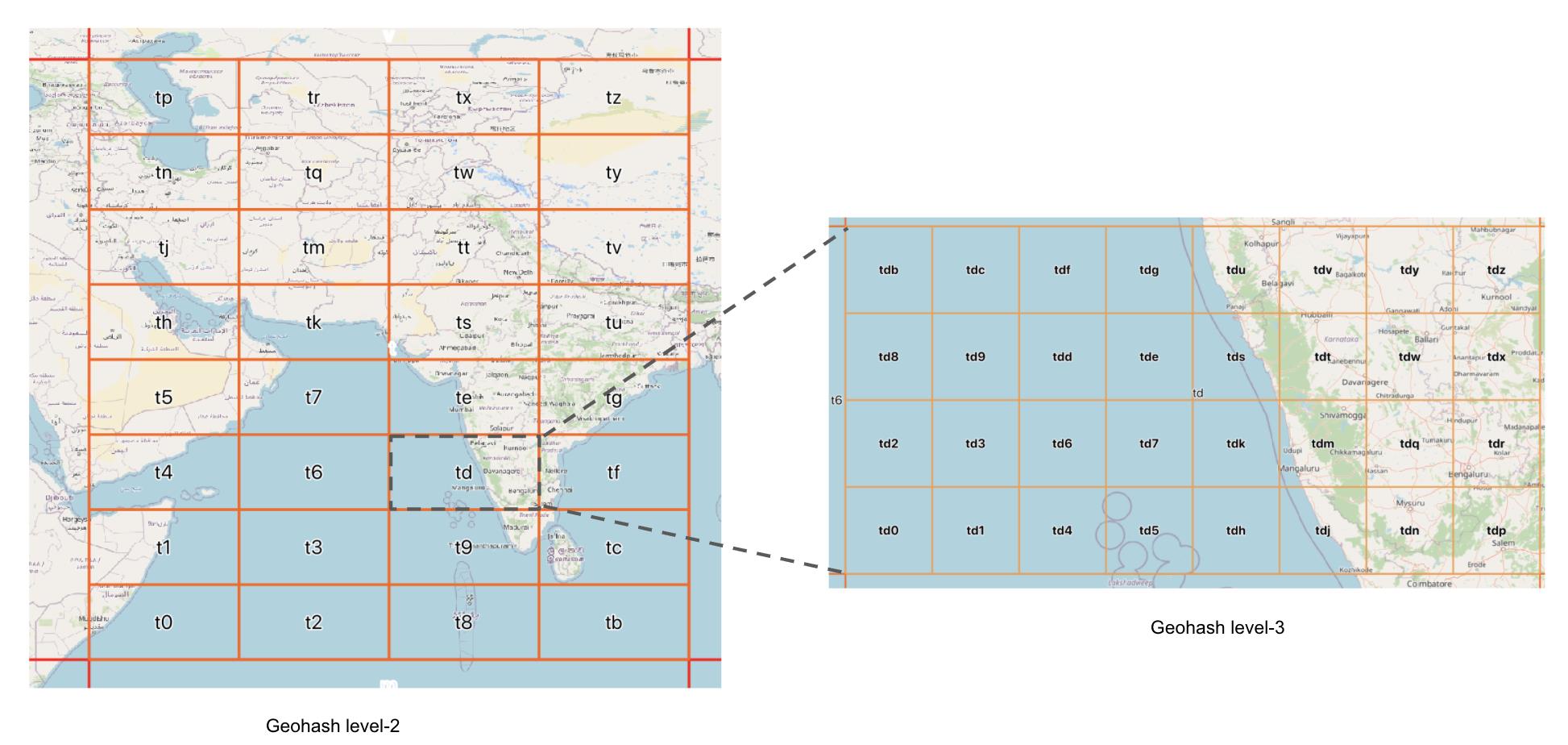
地球分为32个矩形/单元。 每个单元格均由字母数字字符(其哈希)标识。 然后,可以将每个矩形(例如 d)进一步分为自己的32个矩形,生成 d0,d1,依此类推。 你几乎可以永远重复该过程,生成越来越小的矩形,而其相应的哈希值也越来越长。
Geohashing 是如何工作的?
Geohashes 使用 BASE-32 字母编码(字符可以是0到9和 A 到 Z,不包括 “A”,“I”,“L”和 “O”)。想象世界被划分成32个网格。一个 geohash 的第一个字符定义了它处于32个单元中的哪一个。该单元也将包含32个单元,以及这些的每一个单元将包含另外32个单元(等反复)。添加字符到 geohash 更加细分一个小单元,从而得到更加详细的位置信息。
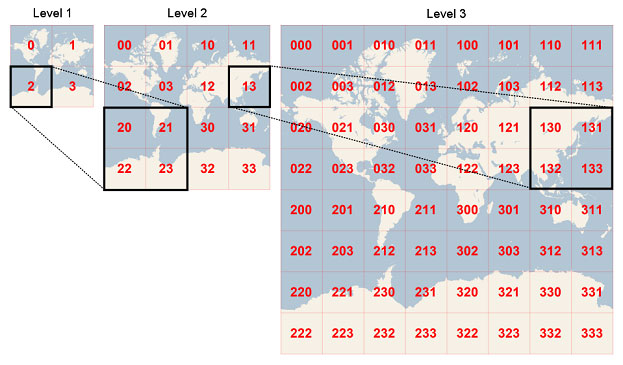
精度因子决定了单元的大小。 例如,精度因子为1时将创建一个 5,000km 高和 5,000km 宽 的单元,精度因子为6时将创建一个 0.61km 高和 1.22km 宽的单元,而精度因子为9时将创建 4.77m 高和 4.77m 宽(单元格并不总是正方形)。

好了,今天的文章介绍就到这里。希望你对 geohash 有一个比较深入的了解。我们可以利用 geohash 来对位置进行搜索。更多详细的信息,请参照 Elastic 官方文档 Geo grid aggregation 。
Geohash grid aggregation
一种多桶聚合,将 geo_point 和 geo_shape 值分组到代表网格的桶中。 生成的网格可能是稀疏的,并且仅包含具有匹配数据的单元。 每个单元格都使用用户可以定义的精度的geohash 进行标记。
- 高精度的 geohash 具有较长的字符串长度,代表仅覆盖较小区域的单元。
- 低精度的 geohash 具有较短的字符串长度,代表每个单元都覆盖大面积的单元。
一下聚合中使用的 geohash 可以在1到12之间选择精度。
警告:长度为12的最高精度的 geohash 产生的单元覆盖不到一平方米的土地,因此就 RAM 和结果大小而言,高精度的请求可能会非常昂贵。 请参阅以下示例,了解如何在请求高精度详细信息之前首先将聚合过滤到较小的地理区域。
简单的低精度请求
首先我们来创建一个如下的索引:
PUT /museums
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}为了说明问题的方便,我在索引里添加了一个叫做 geohash 的字段。它的值可以通过网址 https://www.dcode.fr/geohash-coordinates。我们输入索引中的经纬度,从而得出 geohash 值。在这里,我采用了精度为8:
我们使用 bulk 命令导入数据:
POST /museums/_bulk?refresh
{"index":{"_id":1}}
{"location": "52.374081,4.912350", "geohash": "u173zy3j4h3dsdk", "name": "NEMO Science Museum"}
{"index":{"_id":2}}
{"location": "52.369219,4.901618", "geohash": "u173zt90zczr95s", "name": "Museum Het Rembrandthuis"}
{"index":{"_id":3}}
{"location": "52.371667,4.914722", "geohash": "u173zvfz1666db0", "name": "Nederlands Scheepvaartmuseum"}
{"index":{"_id":4}}
{"location": "51.222900,4.405200", "geohash": "u155khzg08ehqm9", "name": "Letterenhuis"}
{"index":{"_id":5}}
{"location": "48.861111,2.336389", "geohash": "u09tvnvk9g3bm03", "name": "Musée du Louvre"}
{"index":{"_id":6}}
{"location": "48.860000,2.327000", "geohash": "u09tuywqph0uyu8", "name": "Musée d'Orsay"}这样我们的 museums 有6个数据。我们可以使用如下的命令来进行聚合:
POST /museums/_search?size=0
{
"aggregations": {
"large-grid": {
"geohash_grid": {
"field": "location",
"precision": 3
}
}
}
}从我们上面的索引中,我们从 geohash 中可以看出来:u173 开始的有3个文档;u09 开头的有2个文档;u15 开头的有一个文档。上面聚合返回的结果为:
{
"took" : 7,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"large-grid" : {
"buckets" : [
{
"key" : "u17",
"doc_count" : 3
},
{
"key" : "u09",
"doc_count" : 2
},
{
"key" : "u15",
"doc_count" : 1
}
]
}
}
}
高精度请求
当请求详细的存储桶(通常用于显示“放大”的地图)时,应用诸如 geo_bounding_box 之类的过滤器来缩小主题范围,否则可能会创建并返回数百万个存储桶。
POST /museums/_search?size=0
{
"aggregations": {
"zoomed-in": {
"filter": {
"geo_bounding_box": {
"location": {
"top_left": "52.4, 4.9",
"bottom_right": "52.3, 5.0"
}
}
},
"aggregations": {
"zoom1": {
"geohash_grid": {
"field": "location",
"precision": 8
}
}
}
}
}
}我们使用了精度为8的聚合。上面搜索的结果是:
{
"took" : 12,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"zoomed-in" : {
"doc_count" : 3,
"zoom1" : {
"buckets" : [
{
"key" : "u173zy3j",
"doc_count" : 1
},
{
"key" : "u173zvfz",
"doc_count" : 1
},
{
"key" : "u173zt90",
"doc_count" : 1
}
]
}
}
}
}geohash_grid 聚合返回的 geohhes 也可以用于放大。 要放大上一示例中返回的第一个 geohash u17,应将其同时指定为 top_left 和 bottom_right 角:
POST /museums/_search?size=0
{
"aggregations": {
"zoomed-in": {
"filter": {
"geo_bounding_box": {
"location": {
"top_left": "u17",
"bottom_right": "u17"
}
}
},
"aggregations": {
"zoom1": {
"geohash_grid": {
"field": "location",
"precision": 8
}
}
}
}
}
}上面返回的结果为:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 6,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"zoomed-in" : {
"doc_count" : 3,
"zoom1" : {
"buckets" : [
{
"key" : "u173zy3j",
"doc_count" : 1
},
{
"key" : "u173zvfz",
"doc_count" : 1
},
{
"key" : "u173zt90",
"doc_count" : 1
}
]
}
}
}
}
以上是关于Elasticsearch:理解 Elastic Maps 中的 geohash 及其聚合的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:理解 Elastic Maps 中的 geohash 及其聚合