ByteBuffer 介绍及 C++ 实现
Posted C语言与CPP编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ByteBuffer 介绍及 C++ 实现相关的知识,希望对你有一定的参考价值。

1. ByteBuffer 介绍
2. ByteBuffer 的成员变量
2.1 几个位置变量
2.2 缓存区
2.3 ByteBuffer 名称
3. 创建 ByteBuffer
3.1 创建指定大小的空的 ByteBuffer
3.2 从一个数组创建指定大小的 ByteBuffer
3.3 析构方法
4. 状态相关
4.1 初始状态
4.2 写入状态
4.3 读取状态
4.4 mark() && discardMark()
4.5 reset()
4.6 rewind()
4.7 compact()
4.8 状态相关方法总结
5. put 数据
5.1 扩容机制
5.2 模板方法
5.3 put 方法
6. get 数据
6.1 模板方法
6.2 get 方法
7. 其他方法
7.1 equals
7.2 duplicate
7.3 hasRemaining
7.4 remaining
7.5 printInfo
8. ByteBuffer 的缺点
ByteBuffer 介绍及 C++ 实现
之前的工作中遇到过需要打包数据然后通过 USB 发送的功能,当时写了一个简单的类用来存入各种类型的数据,然后将其 Buffer 内的数据发送,接收到数据后通过它的方法再取出各种类型的数据。后来接触到了 Java 的 ByteBuffer,发现两者功能大致相同。本文会用 C++ 实现 ByteBuffer 的大部分功能。
1. ByteBuffer 介绍
ByteBuffer类位于java.nio包下,它是一个字节缓存区,提供了一些 put 和 get 方法,可以方便的将一些数据放到缓存区或者从缓存区里读取某种类型的数据。ByteBuffer 的底层存储结构是数组,所有的操作都是基于该数组的操作。
以下内容结合 Java 版本 ByteBuffer 的原理以及 C++ 实现进行讲解。
2. ByteBuffer 的成员变量
2.1 几个位置变量
| 变量名称 | 含义 |
|---|---|
| position | 表示从写入或者读取的位置。 |
| limit | 处于写入状态时,limit 和 capacity 相等;处于读取状态时,表示数据索引的上限,也就是实际存放了多少数据。 |
| mark | 标记读取数据的起始位置,便于后续回退到该位置。 |
| capacity | 表示 ByteBuffer 的容量,也就是可以存放的最大字节数。 |
这四个变量之间的关系可以表示为:mark <= position <= limit <= capacity。
数据的存入和读取只会影响 position,不会影响 limit。
在 C++ 实现中,设置如下成员变量:
int32_t mark_;
uint32_t limit_;
uint32_t position_;
uint32_t capacity_;
提供如下三个方法分别获取 capacity、position、limit:
uint32_t capacity() const;
uint32_t position() const;
uint32_t limit() const;
提供如下两个方法可以重新设置 limit 和 position:
ByteBuffer& limit(uint32_t newLimit);
ByteBuffer& position(uint32_t newPosition);
2.2 缓存区
前面已经提到,ByteBuffer 提供一个缓存区来存储数据,在 C++ 实现中,使用一个 uint8_t 类型的数组进行数据的存储。在 ByteBuffer 类创建时申请空间,在 ByteBuffer 类销毁时释放空间。
uint8_t* p_buffer_;
2.3 ByteBuffer 名称
为了打印时的美观,为每一个 ByteBuffer 设置一个名称,该名称为 ByteBuffer 类的一个成员变量,在类创建时设置,默认为空:
std::string name_;
3. 创建 ByteBuffer
java.nio.Buffer 类是一个抽象类,不能被实例化。Buffer类的直接子类,如ByteBuffer等也是抽象类,所以也不能被实例化。但是 ByteBuffer 类提供了4个静态工厂方法来获得 ByteBuffer 的实例:
allocate(int capacity)allocateDirect(int capacity)wrap(byte[] array)wrap(byte[] array, int offset, int length)
C++ 版本做了一下简化,提供两个构造方法进行创建。
3.1 创建指定大小的空的 ByteBuffer
// Default size of the buffer
#define DEFAULT_BUFFER_SIZE 2048
ByteBuffer(uint32_t capacity = DEFAULT_BUFFER_SIZE, const char* name = "")
: mark_(-1),
limit_(capacity),
position_(0),
capacity_(capacity),
name_(name)
{
p_buffer_ = NULL;
p_buffer_ = (uint8_t*)calloc(capacity_, sizeof(uint8_t));
}
如果创建时未指定 capacity ,默认大小为 2048 字节。
3.2 从一个数组创建指定大小的 ByteBuffer
ByteBuffer(uint8_t* arr, uint32_t length, const char* name = "")
: mark_(-1),
limit_(length),
position_(0),
capacity_(length),
name_(name)
{
p_buffer_ = NULL;
p_buffer_ = (uint8_t*)calloc(capacity_, sizeof(uint8_t));
putBytes(arr, capacity_);
clear();
}
putBytes() 方法负责将一个现有数组的指定长度存到 ByteBuffer 中,后面会对该方法做介绍。
3.3 析构方法
析构方法主要作用是释放已经申请的内存:
~ByteBuffer()
{
if (p_buffer_)
{
free(p_buffer_);
p_buffer_ = NULL;
}
}
4. 状态相关
申请一个容量为 10 的 ByteBuffer bf,以下演示都基于 bf。
4.1 初始状态
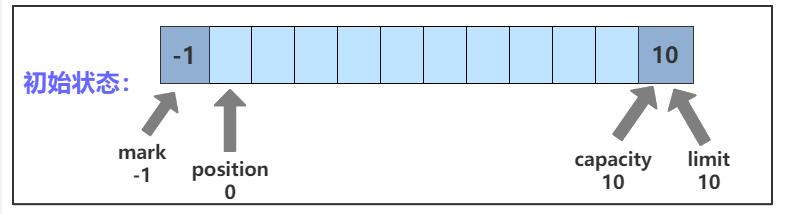
初始状态下,四个变量的值分别为:
mark:-1
position:0
limit:10
capacity:10
将 ByteBuffer 置为初始状态的方法:
ByteBuffer 创建之后调用其它方法之前就是初始状态
调用
clear()方法可以重置到初始状态。
clear() 方法的 C++ 实现如下:
ByteBuffer& clear()
{
position_ = 0;
mark_ = -1;
limit_ = capacity_;
return *this;
}
4.2 写入状态
假设向 bf 写入 hello 几个字符,此时四个变量的状态如图所示:
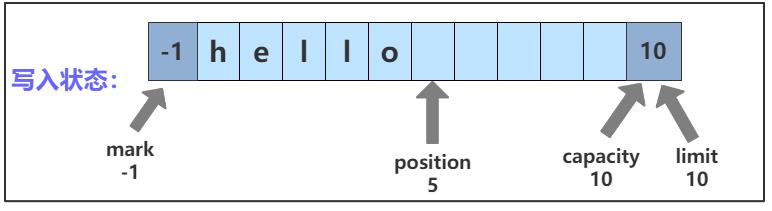
position 会随着数据的写入而后移。
将 ByteBuffer 置为写入状态的方法:
ByteBuffer 创建之后就是写入状态,可以调用一系列
put方法写入数据;
4.3 读取状态
bf 进入读取状态时四个变量的状态如图所示:
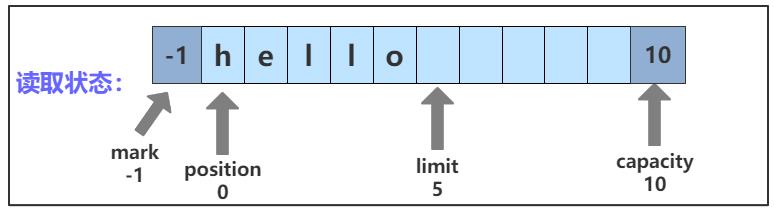
调用一系列 get 方法从 bf 中读取数据,position 随着数据的读取会向后移动,但不会超过 limit。
bf 从写入状态进入读取状态需要调用 flip() 方法,调用 flip() 方法后,limit 被设置为原 position 的值,表示已经存储数据的位置;position 被置为 0。
flip() 方法的 C++ 实现如下:
ByteBuffer& flip()
{
limit_ = position_;
position_ = 0;
mark_ = -1;
return *this;
}
4.4 mark() && discardMark()
这两个方法比较简单,mark() 方法将 mark 值设置为当前的 position ;discardMark() 方法将 mark 重置为 -1。调用 mark() 和 discardMark() 方法后 mark 位置的变化如图所示:
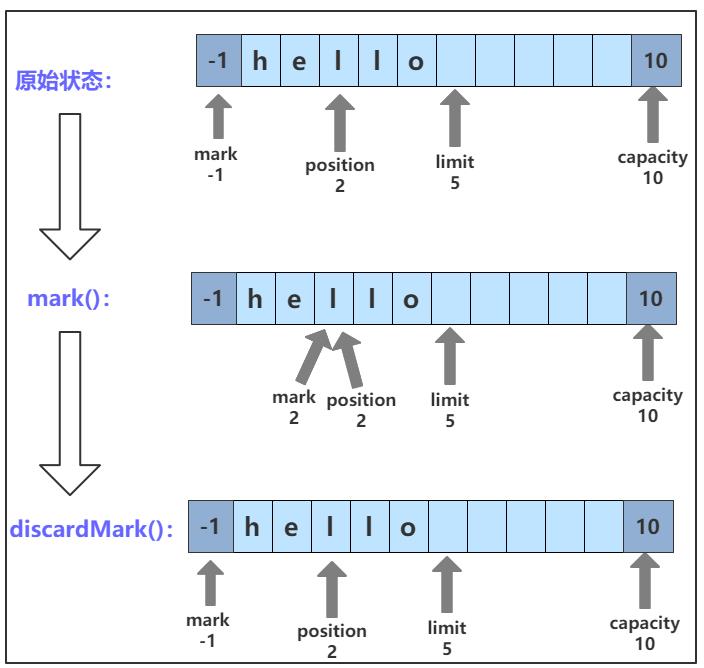
这两个方法的 C++ 代码实现如下:
ByteBuffer& mark()
{
mark_ = position_;
return *this;
}
ByteBuffer& discardMark()
{
mark_ = -1;
return *this;
}
4.5 reset()
reset() 方法将 position 恢复到 mark 的位置。调用 reset() 方法后的 position 变化如图所示:
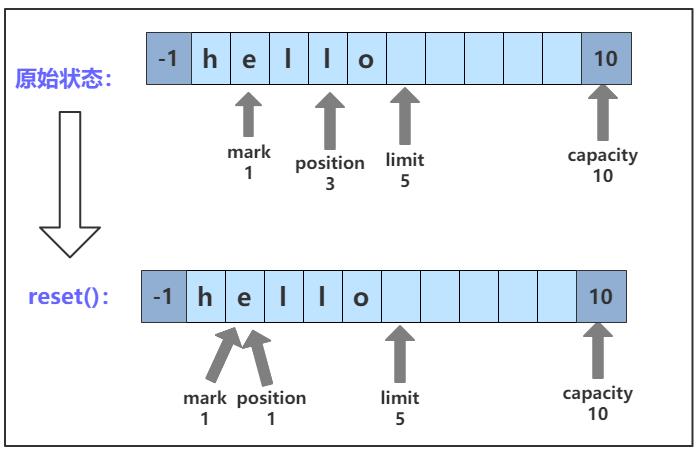
reset() 方法的 C++ 实现如下:
ByteBuffer& reset()
{
if (mark_ >= 0)
position_ = mark_;
return *this;
}
4.6 rewind()
rewind() 方法负责将 position 置为 0,将 mark 置为 -1,数据的内容不会改变,一般在把数据重写入Buffer前调用。调用 rewind() 方法后 mark 和 position 的变化如图所示:
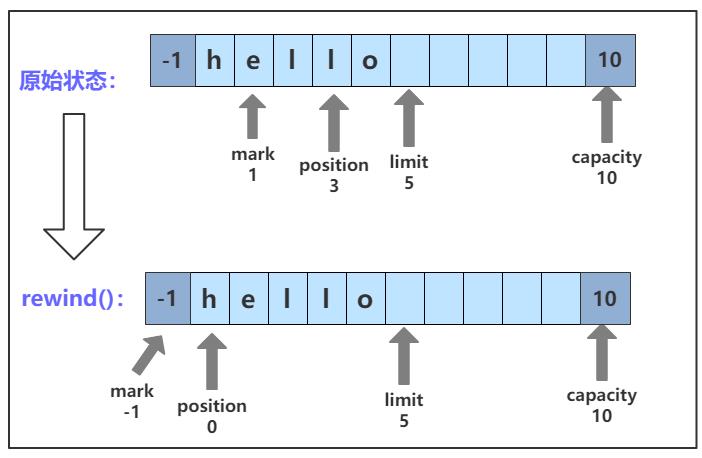
rewind() 方法的 C++ 实现如下:
ByteBuffer& rewind()
{
mark_ = -1;
position_ = 0;
return *this;
}
4.7 compact()
压缩缓存区。把缓存区当前 position 到 limit 之间的数据移动到缓存区的开头。也就是说,将索引 p=position() 处的字节复制到索引 0 处,将索引 p+1 处的字节复制到索引 1 处。以此类推,直到 limit - 1 处的字节复制到索引 n=limit-1-p 处。然后将缓存区的 position 设置为 n+1(也就是不能再读取数据了,但是可以写入数据),并将 limit 的值设置为 capacity。
调用 compact() 方法后,几个变量的位置以及数据的变化如图所示:
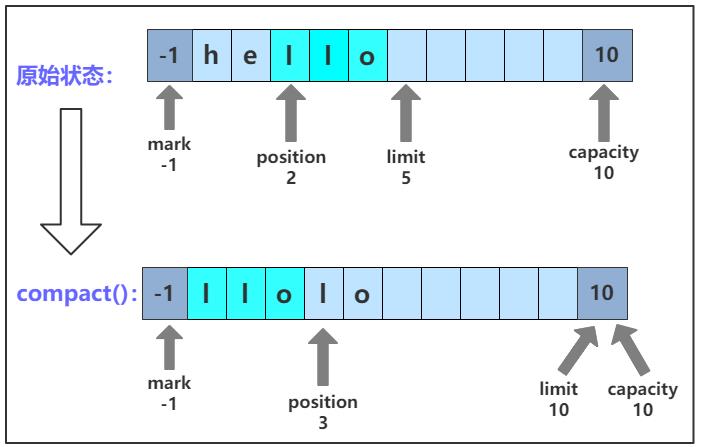
compact() 方法的 C++ 实现如下:
ByteBuffer& compact()
{
do
{
if (position_ >= limit_)
{
position_ = 0;
break;
}
for (uint32_t i = 0; i < limit_ - position_; i++)
{
p_buffer_[i] = p_buffer_[position_ + i];
}
position_ = limit_ - position_;
} while (0);
limit_ = capacity_;
return *this;
}
4.8 状态相关方法总结
| 函数名 | 描述 |
|---|---|
| flip() | 把 limit 设置为当前 position,把 position 置为 0 |
| clear() | 重置ByteBuffer的 position = 0; limit = capacity; mark = -1,数据内容无变化 |
| reset() | 将position恢复到mark处的位置 |
| rewind() | 执行后position = 0, mark = -1,数据内容不变 |
| mark() | 将mark值设置为当前的position |
| discardMark() | 将mark的位置重置为-1 |
| compact() | 删除已读过的数据,将position到limit之间的数据移动到0和limit-position处,并将mark重置为-1,position放到数据结尾,总结一下,就是可以继续写数据了,但是不能读数据 |
5. put 数据
ByteBuffer 提供一系列的 put 方法将各种类型的数据放到 buffer 中,具体的类型有 char、short、int、long、float、double、char 数组以及 Bytebuffer。
5.1 扩容机制
Java 的 ByteBuffer 在创建时容量就固定了,如果存放的数据超出容量,会抛出异常。C++ 版本的 ByteBuffer 增加了扩容机制。理论上,每次向 buffer 中写入数据都要检查空间是否足够,如果空间不够,则扩大容量。
ByteBuffer 定义成员变量 BUFFER_SIZE_INCREASE 表示扩容的步长,即每次扩大的容量都为 BUFFER_SIZE_INCREASE 的整数倍,其值为 2048 :
const uint32_t BUFFER_SIZE_INCREASE = 2048;
定义 checkSize() 方法检查容量是否足够,如果足够,不做处理;如果不够,则计算需要多少容量并扩容:
void ByteBuffer::checkSize(uint32_t index, uint32_t increase)
{
if (index + increase <= capacity_)
return;
uint32_t newSize = capacity_ + (increase + BUFFER_SIZE_INCREASE - 1) /
BUFFER_SIZE_INCREASE * BUFFER_SIZE_INCREASE;
uint8_t* pBuf = (uint8_t*)realloc(p_buffer_, newSize);
if (!pBuf)
{
std::cout << "relloc failed!" << std::endl;
exit(1);
}
p_buffer_ = pBuf;
capacity_ = newSize;
}
void ByteBuffer::checkSize(uint32_t increase)
{
checkSize(position_, increase);
}
在每个 put() 方法里首先调用 checkSize() 检查容量,然后再放入数据。
5.2 模板方法
为了简化存放数据的过程,用一个模板方法去适配各种类型:
template<typename T>
void append(T data)
{
if (!p_buffer_)
return;
uint32_t s = sizeof(data);
checkSize(s);
memcpy(&p_buffer_[position_], (uint8_t*)&data, s);
position_ += s;
}
template<typename T>
void insert(T data, uint32_t index)
{
uint32_t s = sizeof(data);
checkSize(index, s);
position_ = index;
append<T>(data);
}
append() 方法将数据写入到当前的 position_ 处,并相应增加 position_。
insert() 方法将数据写入到指定的位置,首先要将 position_ 设置为 index 然后调用 append() 方法写入数据。
5.3 put 方法
ByteBuffer 提供的所有 put 方法返回值类型都为 ByteBuffer& 便于链式操作,比如 bf.put(1).put("hello", 5).put(3.1415926),所有方法如下所示:
ByteBuffer& put(ByteBuffer* bb);
ByteBuffer& put(uint8_t value);
ByteBuffer& put(uint8_t value, uint32_t index);
ByteBuffer& putBytes(const uint8_t* buf, uint32_t len);
ByteBuffer& putBytes(const uint8_t* buf, uint32_t len, uint32_t index);
ByteBuffer& putChar(char value);
ByteBuffer& putChar(char value, uint32_t index);
ByteBuffer& putShort(uint16_t value);
ByteBuffer& putShort(uint16_t value, uint32_t index);
ByteBuffer& putInt(uint32_t value);
ByteBuffer& putInt(uint32_t value, uint32_t index);
ByteBuffer& putLong(uint64_t value);
ByteBuffer& putLong(uint64_t value, uint32_t index);
ByteBuffer& putFloat(float value);
ByteBuffer& putFloat(float value, uint32_t index);
ByteBuffer& putDouble(double value);
ByteBuffer& putDouble(double value, uint32_t index);
注意:由于 Java 采用 Unicode 编码,一个 Char 类型占两个字节,但是在 C++ 中 char 类型占一个字节,所以两个版本的 putChar() 方法有些差异。
着重讲解一下 ByteBuffer& put(ByteBuffer* bb) 方法,该方法将另一个 ByteBuffer 的内容(从 0 到 limit() 之间的数据)拷贝到当前 ByteBuffer,其实现为:
ByteBuffer& put(ByteBuffer* bb)
{
for (uint32_t i = 0; i < bb->limit(); i++)
append<uint8_t>(bb->get(i));
return *this;
}
6. get 数据
ByteBuffer 提供一系列的 get 方法将各种类型的数据放到 buffer 中。
6.1 模板方法
为了简化数据的获取,实现模板方法获取各种类型的数据。注意:带有 index 参数的 read() 方法不会改变 position 的值。
template <typename T>
T read(uint32_t index) const
{
if (!p_buffer_ || index + sizeof(T) > limit_)
return 0;
return *((T*)&p_buffer_[index]);
}
template <typename T>
T read()
{
T data = read<T>(position_);
position_ += sizeof(T);
return data;
}
6.2 get 方法
所有 get() 方法如下:
uint8_t get();
uint8_t get(uint32_t index) const;
void getBytes(uint8_t* buf, uint32_t len);
void getBytes(uint32_t index, uint8_t* buf, uint32_t len) const;
char getChar();
char getChar(uint32_t index) const;
uint16_t getShort();
uint16_t getShort(uint32_t index) const;
uint32_t getInt();
uint32_t getInt(uint32_t index) const;
uint64_t getLong();
uint64_t getLong(uint32_t index) const;
float getFloat();
float getFloat(uint32_t index) const;
double getDouble();
double getDouble(uint32_t index) const;
注意:带有 index 参数的方法不会改变 position_ 值。
看一下 void getBytes(uint32_t index, uint8_t* buf, uint32_t len) const 方法的实现:
void ByteBuffer::getBytes(uint32_t index, uint8_t* buf, uint32_t len) const
{
// 合法性检测
if (!p_buffer_ || index + len > limit_)
return;
uint32_t pos = index;
for (uint32_t i = 0; i < len; i++)
{
buf[i] = p_buffer_[pos++];
}
}
为了实现只做一次合法性检测,并没有调用 read() 模板方法。
7. 其他方法
7.1 equals
函数原型:bool equals(ByteBuffer* other);
描述:比较两个 ByteBuffer 是否相等;
实现:
bool equals(ByteBuffer* other)
{
uint32_t len = limit();
if (len != other->limit())
return false;
for (uint32_t i = 0; i < len; i++)
{
if (get(i) != other->get(i))
return false;
}
return true;
}
7.2 duplicate
函数原型:ByteBuffer* duplicate();
描述:复制一个 ByteBuffer;
实现:新的 ByteBuffer 的 mark 为 -1,不一样和原 ByteBuffer 相同。
ByteBuffer* ByteBuffer::duplicate()
{
ByteBuffer* newBuffer = new ByteBuffer(capacity_);
// copy data
newBuffer->put(this);
newBuffer->limit(limit_);
newBuffer->position(position_);
return newBuffer;
}
7.3 hasRemaining
函数原型:bool hasRemaining()
描述:表示 position 和 limit 之间是否还有数据;
实现:
bool hasRemaining()
{
return limit_ > position_;
}
7.4 remaining
函数原型:uint32_t remaining() const
描述:返回 position 和 limit 之间字节数;
实现:
uint32_t remaining() const
{
return position_ < limit_ ? limit_ - position_ : 0;
}
7.5 printInfo
函数原型:void printInfo() const
描述:打印 mark、position、limit、capacity 的值
实现:
void printInfo() const
{
std::cout << "ByteBuffer " << name_ << ":\\n"
<< "\\tmark(" << mark_ << "), "
<< "position(" << position_ << "), "
<< "limit(" << limit_ << "), "
<< "capacity(" << capacity_ << ")." << std::endl;
}
8. ByteBuffer 的缺点
ByteBuffer 缺点如下:
ByteBuffer 并不是线程安全的,如果想要在并发情况下使用,需要自己为缓存区做同步控制;
ByteBuffer 长度固定,一旦分配完成,它的容量不能动态扩展和收缩,当需要编码的对象大于 ByteBuffer 的容量时,会发生索引越界异常;
ByteBuffer 只有一个标识位的指针 position,读写的时候需要手工调用
flip()和rewind()等,使用者必须小心谨慎地处理这些 API,否则很容易导致程序处理失败;ByteBuffer 的 API 功能有限,一些高级和实用的特性它不支持,需要使用者自己编程实现。
本文的 C++ 实现只对第二点做了调整,支持了主动扩容;同样存在其它几个缺点。
ByteBuf 是 Netty 里的封装的数据缓存区,区别于 ByteBuffer 里需要 position、limit、capacity 等属性来操作 ByteBuffer 数据读写,而 ByteBuf 是通过两个指针协助完成缓存区的读写操作,后续可能实现 C++ 版本的 ByteBuf 或者对当前 C++ ByteBuffer 进行修改。
参考链接
[1]
Class ByteBuffer: https://docs.oracle.com/javase/7/docs/api/java/nio/ByteBuffer.html
[2]java.nio.Buffer 中的 flip()方法: https://blog.csdn.net/hbtj_1216/article/details/53129588
[3]ByteBuffer常用方法详解: https://blog.csdn.net/moakun/article/details/80630477
[4]ByteBuffer详解: http://bcoder.com/java/explaination-of-bytebuffer
[5]图解ByteBuffer和ByteBuf: https://www.gameboys.cn/article/193

点分享

点收藏

点点赞

点在看
以上是关于ByteBuffer 介绍及 C++ 实现的主要内容,如果未能解决你的问题,请参考以下文章
我的Android进阶之旅NDK开发之在C++代码中使用Android Log打印日志,打印出C++的函数耗时以及代码片段耗时详情