linux-deepin-GPU-CudaFFT从入门到使用三天
Posted 不知名的小咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux-deepin-GPU-CudaFFT从入门到使用三天相关的知识,希望对你有一定的参考价值。
GPU简介
- 图形处理器(英语:graphics processing unit,缩写:GPU),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
-我曾经也一度的认为GPU只是针对图像处理的,直到现在,某次课提到了一下,我尝试学习了它,才发现它的处理思维逻辑有点像FPGA(Field Programmable Gate Array),只不过GPU可以进行浮点运算。GPU的主频也还是蛮高的。其他具体的介绍度娘都可以为你解答,耐心看就行。
-废话不多说,我也不是很了解GPU,这篇文章也只是一个初步探索,谈不上精通,有一点当年用FPGA并行的舒爽吧。这里主要是从两个例子来介绍,第一个则是,cuda程序并行计算,另一个个是cuda加速的cufft与fftw相比。毕竟我的目的是尽可能的使得SDR可以实时。
硬件参数
做实验,不说硬件配置都是流氓呀
CPU: AMD Ryzen 7 3700X 8-Core Processor @ 5.35781GHz
内存:16GB
操作系统:deepin20.02 社区版
显卡:Getforce RTX2060
自打买了这电脑以来,还没用过显卡,可不能浪费啦
软件参数
这里主要是说一下我安装的显卡驱动什么的, 默认已经装好显卡驱动和cuda啦,我不做神经网络,所以不装cudann。
终端输入
nvidia-smi
结果如下: 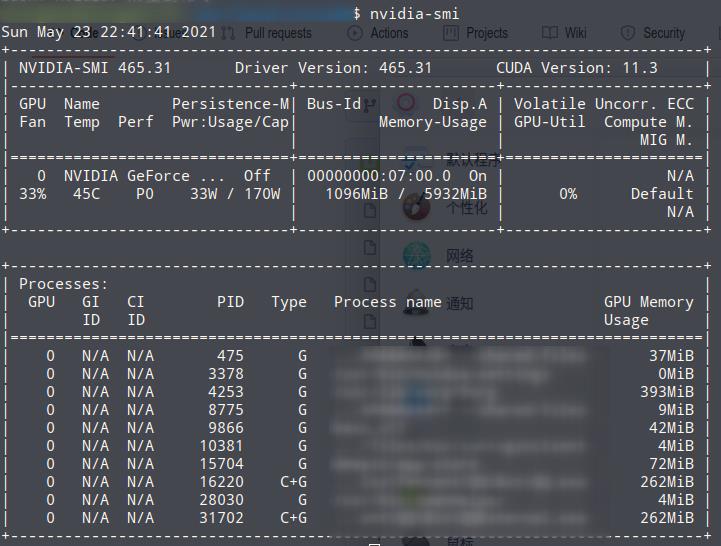
显卡驱动教程,我看人家的:
deepin20 显卡驱动安装
这个稍微和别人有点不一样的,自己装的时候意会一下就好啦
deepin 安装ubuntu的cuda
cuda安装,首先取官网下一个cuda,我直接下debian的deb没装好,装的ubuntu 的.run
什么版本看自己显卡吧
注意大写
$ nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2021 NVIDIA Corporation
Built on Mon_May__3_19:15:13_PDT_2021
Cuda compilation tools, release 11.3, V11.3.109
Build cuda_11.3.r11.3/compiler.29920130_0
到这里环境就算是搭建好啦
这是正经事
这里的代码都是c++调用GPU加速,这是正常人干的事,一般不会反人类吧
GPU不能cout注意啦
并行计算测试
要注意的几个点呢,
1 库链接,可以绝对路径,这个自己品味
2 编译的时候加上库的名字也是可以的
3 CmakeLists.txt 这个好,,就讲这个吧
注意,CmakeLists.txt ,多加了关键词cuda,不然编译会出问题
cuda_add_executable(cuda_xxx xxx.cpp)
好啦到这就可以贴代码啦
官方例程也贴下吧:
main.cu
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int main()
{
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaThreadExit must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaThreadExit();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaThreadExit failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, size_t size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel<<<1, size>>>(dev_c, dev_a, dev_b);
// cudaThreadSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaThreadSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaThreadSynchronize returned error code %d after launching addKernel!\\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
用nvcc -c编译:
$nvcc -c main.cu
./main
{1,2,3,4,5} + {10,20,30,40,50} = {11,22,33,44,55}
这里是C++调用cuda的结果,代码干啥就随意啦
main-> add.cpp
add.h
kernel.cu
kernel.cuh (这里没用用)
kernel.h(也可以用.h文件)
add.cpp
#include "add.h"
#define M2 1000000
#define Dlen 100*M2
void add(long int *a,long int *b,long int *c)
{
for (long int f = 0; f<Dlen; f++)
{
*c = (*a)*(*b);
}
}
int main(void)
{
CTest cTest;
long int a,b,c;
a = 102400;
b = 306900;
clock_t time_used;
clock_t start = clock();
add(&a,&b,&c);
cout << "CPU time use is " << (clock() - start)*1.0/CLOCKS_PER_SEC << endl;
cTest.Evolution();
}
add.h
#pragma once
// #include "/usr/local/cuda/include/cuda_runtime.h"
// #include "/usr/local/cuda/include/device_launch_parameters.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
// #include "kernel.cuh"
#include "kernel.h"
#include <iostream>
using namespace std;
#define M 1000000
#define DX 100*M
class CTest
{
public:
long int *a;
long int *b;
long int *c;
void SetParameter();
void AddNum();
void Show();
void Evolution();
};
void CTest::SetParameter()
{
cudaMallocManaged(&a, sizeof(long int) * DX);
cudaMallocManaged(&b, sizeof(long int) * DX);
cudaMallocManaged(&c, sizeof(long int) * DX);
for (long int f = 0; f<DX; f++)
{
a[f] = 102400;
b[f] = 306900;
}
}
void CTest::AddNum()
{
AddKernel(a, b, c, DX);
}
void CTest::Show()
{
cout << " a b c" << endl;
for (long int f = 0; f<DX; f++)
{
cout << a[f] << " + " << b[f] << " = " << c[f] << endl;
}
}
void CTest::Evolution()
{
SetParameter();
clock_t time_used;
clock_t start = clock();
AddNum();
cout << "GPU time use is " << (clock() - start)*1.0/CLOCKS_PER_SEC << endl;
cout << "sum finish !!!" << endl;
// Show();
}
kernel.cu
#include "kernel.h"
// #include "/usr/local/cuda/include/cuda_runtime.h"
// #include "/usr/local/cuda/include/device_launch_parameters.h"
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
__global__ void Add(long int *a,long int *b, long int *c,long int DX)
{
int f = blockIdx.x*blockDim.x + threadIdx.x;
if (f >= DX) return;
c[f] = a[f]*b[f];
}
void AddKernel(long int *a, long int *b, long int *c, long int DX)
{
dim3 dimBlock = (1024);
dim3 dimGrid = ((DX + 128 - 1) / 128);
Add << <dimGrid, dimBlock >> > (a, b, c, DX);
cudaDeviceSynchronize();
}
kernel.cuh
void AddKernel(long int *a, long int *b, long int *c,long int DX);
CMakeLists.txt
cmake_minimum_required (VERSION 2.8)
project (Cpp_rungpu)
#significant note: gcc version 5.4.0
set(CMAKE_CXX_FLAGS "-std=c++11 -DNDEBUG -O2 ") ##-g
find_package(CUDA QUIET REQUIRED)
include_directories("${CUDA_INCLUDE_DIRS}")
include_directories(/usr/local/include)
include_directories(/usr/local/cuda/include)
cuda_add_executable(Cpp_rungpu add.cpp kernel.cu ) ##关键语句
target_link_libraries(Cpp_rungpu)
readme这是一种编译方式
nvcc -c kernel.cu
$ g++ -c add.cpp
$ g++ -o test kernel.o add.o -L/usr/local/cuda/lib64 -lcudart
$ ./test
cmake编译就不讲了
结果如下:
./Cpp_rungpu
CPU time use is 1.1e-05
GPU time use is 0.366504
sum finish !!!
明显CPU时间短啦,,懂的都懂,为什么自己想想或者查查吧。
CudaFFT与FFTW对比
我装的是double的FFTW,FFTw这个很好装的啦,自己找找就好啦,装好后记得刷新(ldconfig)一下才可用哦。
cuda还有个cudafftw不是很清楚怎么用
文件
- main.cpp
- fftw_test.cpp
- fftw_test.h
- fft_cuda.cu
- fftw_cuda.cuh
- CMakeLists.txt
main.cpp
#include <iostream>
#include <fstream>
#include "fftw_test.h"
#include "fftw3.h"
#include "math.h"
using namespace std;
//现在计算机安装的是double版本的fftw
int main()
{
cout << "hello world !!!" << endl;
cout << "百万级别数据测试-哈哈哈" << endl;
clock_t time_used;
clock_t start = clock();
// data gen
long int i;
double Data[numFFT] = {0};
double fs = 1000000.000;//mpling frequency 1E6
double f0 = 200000.00;// signal frequency f 200k
for (i = 0; i < numFFT; i++)
{
Data[i] = 1.35 * cos(2 * pi * f0 * i / fs);//signal gen,
}
complex<double> *data_in;
data_in = (complex<double>*)fftw_malloc(sizeof(complex<double>)* numFFT); //分配内存
/*FFT数据*/
for (i = 0; i < numFFT; i++)
{
data_in[i] = complex<double>(Data[i],0);
}
cout << "----------********************--------" << endl;
cout << "data generate time use is " << (clock() - start)*1.0/CLOCKS_PER_SEC << endl;
start = clock();
//cpu result
fftw_cpu *fft_cpu_test;
fft_cpu_test = new fftw_cpu();
cout << "build cpu class fft time use is " << (clock() - start)*1.0/CLOCKS_PER_SEC << endl;
start = clock();
fft_cpu_test->fftw_cpu_deal(data_in);
cout << "CPU FFT time use is " << (clock() - start)*1.0/CLOCKS_PER_SEC << endl;
cout << "----------********************--------" << endl;
start = clock();
//gpu result
fft_gpu *fft_gpu_test;
fft_gpu_test = new fft_gpu(numFFT);
cout << "build gpu class fft time use is " << (clock() - start)*1.0/CLOCKS_PER_SEC << endl;
start = clock();
fft_gpu_test->fft_gpu_deal(data_in,numFFT);
cout << "GPU FFT time use is " << (clock() - start)*1.0/CLOCKS_PER_SEC << endl;
cout << "----------********************--------" << endl;
cout << "百万级别数据测试-啊啊啊啊啊" << endl;
return 0;
}
fftw_test.cpp
#include "fftw_test.h"
/**
* cpu
* */
fftw_cpu::fftw_cpu()
{
//分配内存
以上是关于linux-deepin-GPU-CudaFFT从入门到使用三天的主要内容,如果未能解决你的问题,请参考以下文章