如何在Python中将API响应时间减少89.30%
Posted 五包辣条!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何在Python中将API响应时间减少89.30%相关的知识,希望对你有一定的参考价值。
如果您要构建快速且可扩展的应用程序,则API响应时间是要寻找的重要因素。
在处理客户的项目时,我需要完成一项任务,需要为该项目集成第三方API。这意味着客户的项目API响应时间现在也将取决于此第三方API。
如果我们只需要对API进行单个查询并返回该查询的结果,那么一切都会很好,当我们需要进行多个查询并为我们进行的每个查询返回结果时,情况会变得越来越糟。
为了演示如何有效地发出多个请求,我们将使用此简单的Rhyming word API。
例如,假设我们要为[“ hello”,“ mellow”,“ cat”,“ rat”,“ dog”,“ frog”,“ mouse”,“ sparrow”,“男人”,“妇女”]可能会想到实现这样的代码。
import requests, time
words = ["hello", "mellow", "cat", "rat", "dog", "frog", "mouse", "sparrow", "man", "women"]
def make_req_syncronously(words_arr):
final_res = []
for word in words_arr:
url = f"https://api.datamuse.com/words?rel_rhy={word}&max=100"
response = requests.get(url)
json_response = response.json()
for item in json_response:
rhyming_word = item.get("word", "")
final_res.append({"word": word, "rhyming_word": rhyming_word})
return final_res
without_async_start_time = time.time()
response = make_req_syncronously(words)
time_without_async = time.time() - without_async_start_time
print("total time for with synchronous execution >> ", time_without_async, " seconds")
您会看到这种方法大约需要9.479秒的时间来搜索“单词”列表中存在的每个单词的押韵单词。您能想象您打开一个网站并花10秒钟来加载吗?只是因为有人在后端写了这个可怕的代码。
为了更好地理解这一点,请查看此图,了解我们如何以这种同步方式发出请求。

如您所见,我们向(“ hello”)单词发出第一个请求,然后等待它返回结果,然后将其附加到我们要返回的列表中,列表中的每个单词都相同。这是实现它们的极其耗时的方法。
那么,我们该如何改善呢?
好吧,这就是异步/等待为我们提供帮助的地方。让我们了解如何使用以下Python代码同时发出多个请求。
import asyncio
import aiohttp # external library
import time
words = ["hello", "mellow", "cat", "rat", "dog", "frog", "mouse", "sparrow", "man", "women"]
async def main():
headers = {'content-type': 'application/json'}
async with aiohttp.ClientSession(headers=headers) as session:
tasks = [] # for storing all the tasks we will create in the next step
for word in words:
task = asyncio.ensure_future(get_rhyming_words(session, word)) # means get this process started and move on
tasks.append(task)
# .gather() will collect the result from every single task from tasks list
# here we use await to wait till all the requests have been satisfied
all_results = await asyncio.gather(*tasks)
combined_list = merge_lists(all_results)
return combined_list
async def get_rhyming_words(session, word):
url = f"https://api.datamuse.com/words?rel_rhy={word}&max=1000"
async with session.get(url) as response:
result_data = await response.json()
return result_data
async_func_start_time = time.time()
response2 = asyncio.get_event_loop().run_until_complete(main(words))
time_with_async = time.time() - async_func_start_time
print("\\nTotal time with async/await execution >> ", time_with_async, " seconds")
print("\\nTotal time with async/await execution >> ", time_with_async, " seconds")
在这里,我们为每个请求创建一个Task,在Python中也称为Couritine。在此实现中,我们开始一个任务,但不等待它完成就可以继续前进并开始一个新任务。
最后,在完成所有任务的创建之后,我们等待直到获得每个任务的结果,然后我们简单地使用merge_lists函数合并任务的所有结果,并返回包含所有结果的组合列表。
在单词列表中为所有单词搜索有韵词的时间大约为1秒,这比我们以前的方法要好得多。
请求与时间的关系图现在看起来像
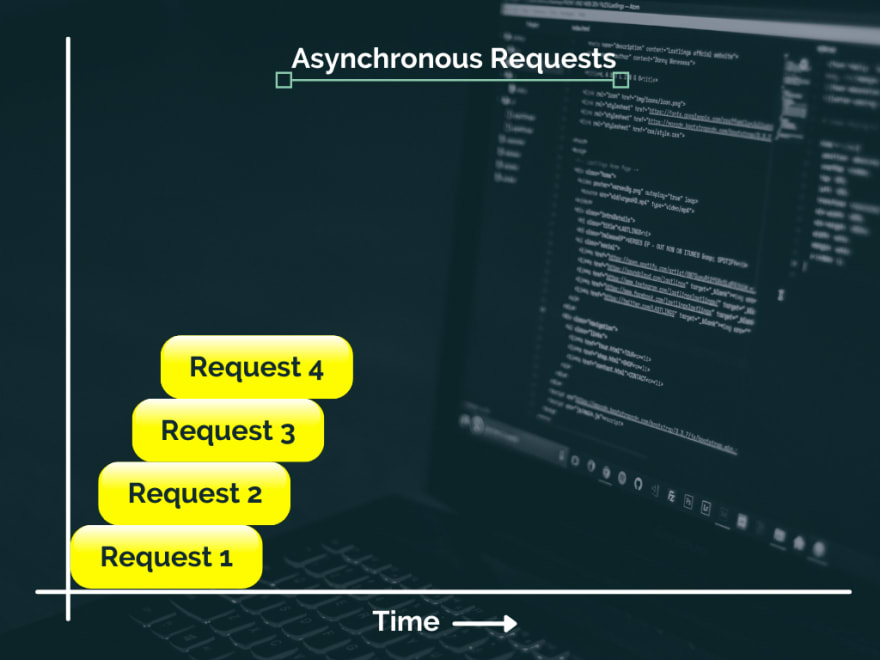
正如您在图表中看到的那样,当我们发起最终请求时,我们将已经完成一些先前的请求。
这是供您比较这两种实现的Python代码。
_import_ requests, time
words = ["hello", "mellow", "cat", "rat", "dog", "frog", "mouse", "sparrow", "man", "women"]
_def_ make_req_syncronously(words_arr):
final_res = []
_for_ word _in_ words_arr:
url = f"https://api.datamuse.com/words?rel_rhy={word}&max=100"
response = requests.get(url)
json_response = response.json()
_for_ item _in_ json_response:
rhyming_word = item.get("word", "")
final_res.append({"word": word, "rhyming_word": rhyming_word})
_return_ final_res
without_async_start_time = time.time()
response = make_req_syncronously(words)
time_without_async = time.time() - without_async_start_time
_#
print_ ("total time for with synchronous execution >> ", time_without_async, " seconds")
_import_ asyncio
_import_ aiohttp _# external library_
_def_ merge_lists(results_from_fc):
_"""
Function for merging multiple lists
"""_ combined_list = []
_for_ li _in_ results_from_fc:
combined_list.extend(li)
_return_ combined_list
_async def_ main():
headers = {'content-type': 'application/json'}
_async with_ aiohttp.ClientSession(headers=headers) _as_ session:
tasks = [] _# for storing all the tasks we will create in the next step
for_ word _in_ words:
task = asyncio.ensure_future(get_rhyming_words(session, word)) _# means get this process started and move on_
tasks.append(task)
_# .gather() will collect the result from every single task from tasks list
# here we use await to wait till all the requests have been satisfied_ all_results = _await_ asyncio.gather(*tasks)
combined_list = merge_lists(all_results)
_return_ combined_list
_async def_ get_rhyming_words(session, word):
url = f"https://api.datamuse.com/words?rel_rhy={word}&max=1000"
_async with_ session.get(url) _as_ response:
result_data = _await_ response.json()
_return_ result_data
async_func_start_time = time.time()
response2 = asyncio.get_event_loop().run_until_complete(main())
time_with_async = time.time() - async_func_start_time
_print_("\\nTotal time with async/await execution >> ", time_with_async, " seconds")
total_improvement = (time_without_async - time_with_async) / time_without_async * 100
_print_(f"\\n{'*' * 100}\\n{' ' * 32}Improved by {total_improvement} %\\n{'*' * 100}")
感谢您抽出宝贵的时间阅读我的博客。
以上是关于如何在Python中将API响应时间减少89.30%的主要内容,如果未能解决你的问题,请参考以下文章