TensorFlow2 入门指南 | 08 认识与搭建全连接层神经网络
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow2 入门指南 | 08 认识与搭建全连接层神经网络相关的知识,希望对你有一定的参考价值。
前言:
本专栏在保证内容完整性的基础上,力求简洁,旨在让初学者能够更快地、高效地入门TensorFlow2 深度学习框架。如果觉得本专栏对您有帮助的话,可以给一个小小的三连,各位的支持将是我创作的最大动力!
系列文章汇总:TensorFlow2 入门指南
Github项目地址:https://github.com/Keyird/TensorFlow2-for-beginner
文章目录
一、感知机与全连接层
(1)感知机
如今的全连接层其实是由感知机发展而来的,所以说起全连接不得不提到感知机模型。最原始的感知机是线性模型:y=Wx+b,但是这并不能处理线性不可分问题。所以后人在感知机模型的基础上,加入了激活函数,如下图所示,从此感知机可以用来完成二分类任务的分类。
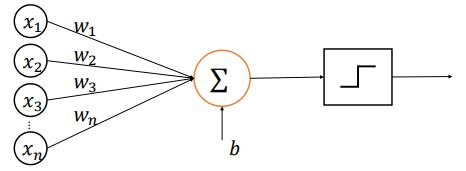
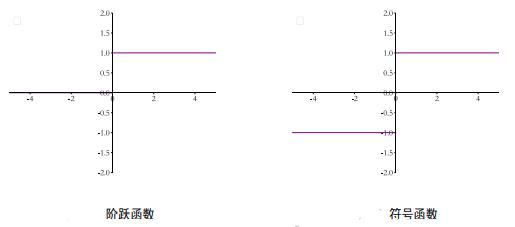
但是,当时采用的激活函数普遍是阶跃函数和符号函数,这两种函数在y = 0处是不连续的,其他位置导数为 0,因此无法利用梯度下降算法进行参数优化。
感知机模型的不可导特性严重约束了它的潜力,使得它只能解决极其简单的任务。所以之后,科学家在感知机的基础上,将不连续的阶跃激活函数换成了其他平滑连续激活函数,并通过堆叠多层网络层来增强网络的表达能力,于是就有了现代动辄数百万甚至上亿的参数规模的深度神经网络。实际上,深度学习的核心结构与感知机并没有多大差别。
(2)全连接层
全连接层(Fully Connected Layers)是全连接神经网络的基本单元。之所以叫全连接,是因为每个神经元与前后相邻层的每一个神经元都有连接关系。如下图所示,是一个简单的两层全连接网络,输入是的原始数据(或特征),输出是预测的结果。
全连接神经网络结构较为简单,一般分为输入层、中间层(隐藏层)和输出层。其中,输入层代表着数据的输入,中间层需要设定一定量的节点,输出层的节点与分类的类别数有关。
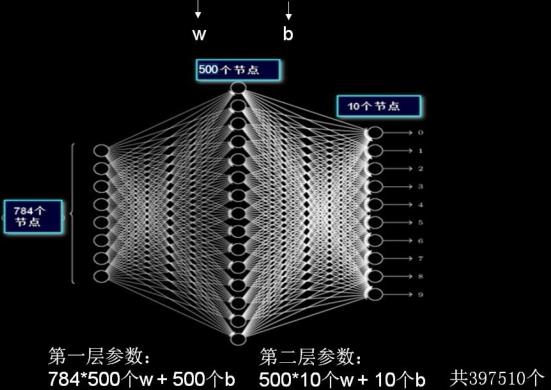
如上图所示的两层全连接网络,输入仅仅是 28x28 的黑白图像,经过拉直后可得到长度是784的一维向量,因此输入层的节点数是784;中间层的节点设定为500个,输出层的节点数是10,意味着进行10分类。
全连接层的参数量是可以直接计算的,通过如下计算公式计算,可以得到上图所示的两层全连接网络一共包含397510个待优化参数。
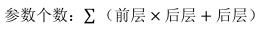
需要注意的是,在计算机视觉领域中,输入的通常是高分辨率的彩色图像,像素点更多,且为红绿蓝三通道信息。采用全连接网络的话,待优化的参数就会非常多, 容易导致模型过拟合。为避免这种现象,实际应用中一般不会将原始图片直接喂入全连接网络,而是会先对原始图像进行卷积特征提取,把提取到的特征喂给全连接网络,再让全连接网络计算出分类评估值。
二、全连接层类
在全连接层中主要会用到以下三个类:
(1)layers.Dense()
通过 layers.Dense() 可以设置中间层和输出层的节点个数,以及激活函数类型,比如设置当前层的节点个数是512,激活函数采用的是ReLU:
layers.Dense(512, activation=tf.nn.relu)
(2)layers.Dropout()
在全连接网络中,相邻层的节点相互连接,当节点过多时,网络就会过于稠密。这时常常会采取dropout手段,对神经网络中的参数传递进行随机失活:
layers.Dropout(rate=0.5)
(3)layers.Flatten()
有的时候,输入的数据不是向量形式,而是二维的图像形式。那么在数据送入全连接网络组之前,就需要先通过Flatten()函数,将二维矩阵拉直成一维的向量形式。比如:下面将28x28的图片拉直成长度为784的向量:
layers.Flatten(input_shape=(28, 28))
通过拉直之后,可以进行一系列的操作的了。
三、实现全连接层
现在假设一个全连接层的输入节点为784个,中间层节点为500个,输出节点为10个。在TensorFlow2中,我们可以采取以下三种方式去是实现。
(1)张量形式
当采用张量形式进行构建时,对于多层神经网络,需要分别定义各层的权值矩阵 w 和偏置向量 b。
import tensorflow as tf
# 输入层
# 输入两个样本,每个样本的特征长度是784
x = tf.random.normal([2, 784])
# 中间层
# 中间层节点为500,所以定义权重举阵w1的shape为[784, 500]
w1 = tf.Variable(tf.random.truncated_normal([784, 500], stddev=0.1))
# 定义中间层的偏置
b1 = tf.Variable(tf.zeros([500]))
# 中间层输出
o1 = tf.matmul(x, w1) + b1
# 激活函数
o1 = tf.nn.relu(o1) # 激活函数
# 输出层
# 输出层节点为10,进行10分类,故权重举阵w2的shape为[500,10]
w2 = tf.Variable(tf.random.truncated_normal([500, 10], stddev=0.1))
# 定义中间层的偏置
b2 = tf.Variable(tf.zeros([10]))
# 中间层输出
o2 = tf.matmul(o1, w2) + b2
# 激活函数
o2 = tf.nn.relu(o2)
# 打印输出shape:[2,10]
print(o2.shape)
(2)层方式实现
通过层方式实现起来更加简洁,首先新建各个网络层,并指定各层的激活函数类型;然后,在前向计算时,依序通过各个网络层即可。
import tensorflow as tf
from tensorflow.keras import layers
# 新建各个网络层
fc1 = layers.Dense(500, activation=tf.nn.relu)
fc2 = layers.Dense(10, activation=tf.nn.relu)
# 前向计算
x = tf.random.normal([2, 28*28]) # 模拟输入
o1 = fc1(x)
o2 = fc2(o1)
# 输出层的shape:[2,10]
print(o2.shape)
通过层方式实现,我们可以轻松查看各全连接层的权重参数,下面以 fc1 层为例:
# 获取中间层的权值矩阵
print(fc1.kernel)
# 获取中间层偏置向量
print(fc1.bias)
# 返回待优化参数列表
print(fc1.trainable_variables)
# 返回所有参数列表
print(fc1.variables)
(3)Sequential 容器实现
对于这种数据依次向前传播的网络,也可以通过 Sequential 容器封装成一个网络大类对象,调用大类的前向计算函数即可完成所有层的前向计算:
import tensorflow as tf
from tensorflow.keras import Sequential, layers
model = Sequential([
layers.Dense(500, activation=tf.nn.relu), # 创建隐藏层
layers.Dense(10, activation=None), # 创建输出层
])
# 模拟输入
x = tf.random.normal([2, 28*28])
# 输出
out = model(x)
# [2,10]
print(out.shape)
需要注意的是:使用前两种方式构建网络时,最好将前向计算过程放置在tf.GradientTape()环境中,这样方便通过 TensorFlow 自动求导。而采用Sequential 容器实现的话,可以直接通过TF2中的内置函数 compile() 和 fit() 进行模型的装载和训练。
四、使用 Sequential 容器搭建第一个全连接网络
结合 TensorFlow2 入门指南 | 07 数据集的加载、预处理、数据增强 学过的数据集加载、预处理等内容,下面使用TensorFlow2 中的 Sequential 容器搭建第一个全连接网络,实现对手写数字图像(来自mnist数据集)的分类。
import tensorflow as tf # 导入TF库
from tensorflow.keras import datasets, Sequential, layers # 导入TF子库
# 数据集预处理
def preprocess(x, y):
x = tf.cast(x, dtype=tf.float32)/255. # 归一化,将像素值缩放到0~1
y = tf.cast(y, dtype=tf.int32)
return x, y
# 数据集准备
def mnist_dataset():
(x, y), (x_test, y_test) = datasets.mnist.load_data()
db_train = tf.data.Dataset.from_tensor_slices((x, y))
db_train = db_train.map(preprocess).shuffle(60000).batch(32)
db_test = tf.data.Dataset.from_tensor_slices((x_test, y_test))
db_test = db_test.map(preprocess).shuffle(60000).batch(32)
return db_train, db_test
# 模型搭建
network = Sequential([
layers.Flatten(input_shape=(28, 28)),
layers.Dense(128, activation='relu'),
layers.Dropout(0.2),
layers.Dense(10, activation='softmax')
])
# 数据集准备
db_train, db_test = mnist_dataset()
# 模型的装配
network.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
# 模型的训练
network.fit(db_train, epochs=5)
# 模型的评估
network.evaluate(db_test, verbose=2)
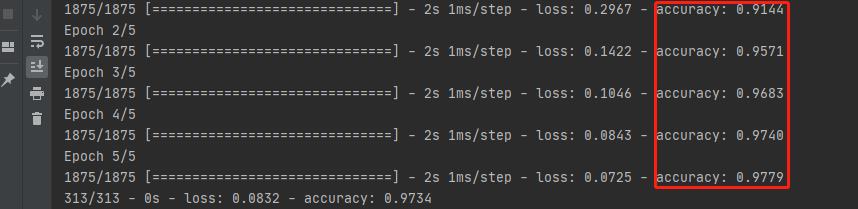
训练了5个epoch,各阶段的训练精度如下:
本专栏所有代码会逐渐上传github仓库:https://github.com/Keyird/TensorFlow2-for-beginner
如果对你有帮助的话,欢迎star收藏~

以上是关于TensorFlow2 入门指南 | 08 认识与搭建全连接层神经网络的主要内容,如果未能解决你的问题,请参考以下文章