2021年大数据基础:分布式技术
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021年大数据基础:分布式技术相关的知识,希望对你有一定的参考价值。
目录
分布式技术
为什么需要分布式
计算问题
无论是我们在学校刚开始学编程,还是在刚参加工作开始处理实际问题,写出来的程序都是很简单的。因为面对的问题很简单。以处理数据为例,可能只是把一个几十K的文件解析下,然后生成一个词频分析的报告。很简单的程序,十几行甚至几行就搞定了。
直到有一天,给你扔过来1000个文件,有些还特别大,好几百M了。你用之前的程序一跑,发现跑的时间有点长。于是想要去优化下。1000 个文件,互相还没业务联系,用多线程呀,一个线程处理一个文件,结果再汇总就搞定了。如果多线程效果不够好,比如像 Python 的多线程,没法利用多核的威力,那就用多进程。
无论是线程、进程,本质上,目的都是为了计算的并行化,解决的是算的慢的问题。而如果计算量足够大,就算榨干了机器的计算能力,也算不过来,咋办?
一台机器不够,那就多搞几台机器嘛。所以就从多线程/进程的计算并行化,进化到计算的分布式化(当然,分布式一定程度上也是并行化)。
存储问题
另一方面,如果处理的数据有10T,而你手上的机器只有500G 的硬盘,怎么办?
一种办法是纵向扩展,搞一台几十T硬盘的机器;另一种是横向扩展,多搞几台机器,分散着放。前者很容易到瓶颈,毕竟数据无限,而一台机器的容量有限,所以在大数据量的情况下,只能选后者。把数据分散到多台机器,本质上解决的是存不下的问题。
同时,刚才提到计算分布式化后,总不能所以程序都去同一台机器读数据吧,这样效率必然会受到单台机器性能的拖累,比如磁盘 IO、网络带宽等,也就逼着数据存储也要分散到各个机器去了。基于这两个原因,数据存储也分布式起来了。
分布式系统概述
分布式系统是一个硬件或软件组件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调的系统。简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。
分布式意味着可以采用更多的普通计算机(相对于昂贵的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
从分布式系统的概念中我们知道,各个主机之间通信和协调主要通过网络进行,所以,分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被放在不同的机柜上,也可能被部署在不同的机房中,还可能在不同的城市中,对于大型的网站甚至可能分布在不同的国家和地区。
分布式实现方案
分布式系统
小明的公司有3个系统:系统A,系统B和系统C,这三个系统所做的业务不同,被部署在3个独立的机器上运行,他们之间互相调用(当然是跨域网络的),通力合作完成公司的业务流程。
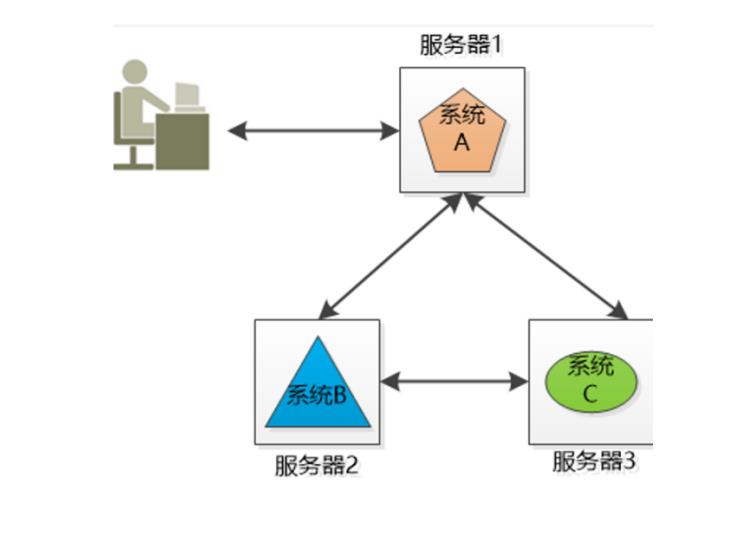
将不同的业务分部在不同的地方,就构成了一个分布式的系统,现在问题来了,系统A是整个分布式系统的脸面,用户直接访问,用户访问量大的时候要么是速度巨慢,要么直接挂掉,怎么办?
由于系统A只有一份,所以会引起单点失败。
集群(Cluster)
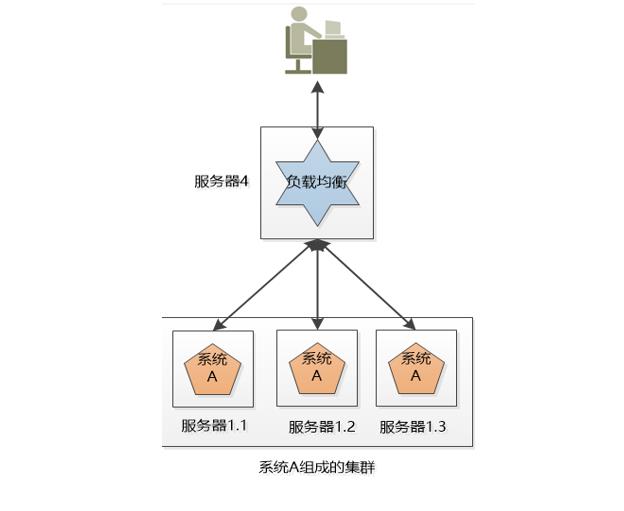
小明的公司不差钱,就多买几台机器吧, 小明把系统A一下子部署了好几份(例如下图的3个服务器),每一份都是系统A的一个实例,对外提供同样的服务,这样,就不怕其中一个坏掉了,还有另外两个呢。
这三个服务器的系统就组成了一个集群。

可是对用户来说,一下子出现这么多系统A,每个系统的IP地址都不一样,到底访问哪一个呢?
如果所有人都访问服务器1.1,那服务器1.1会被累死,剩下两个闲死,成了浪费钱的摆设。
负载均衡(Load Balancer)
小明要尽可能的让3个机器上的系统A工作均衡一些,比如有3万个请求,那就让3个服务器各处理1万个(理想情况),这叫负载均衡
很明显,这个负载均衡的工作最好独立出来,放到独立的服务器上(例如nginx):
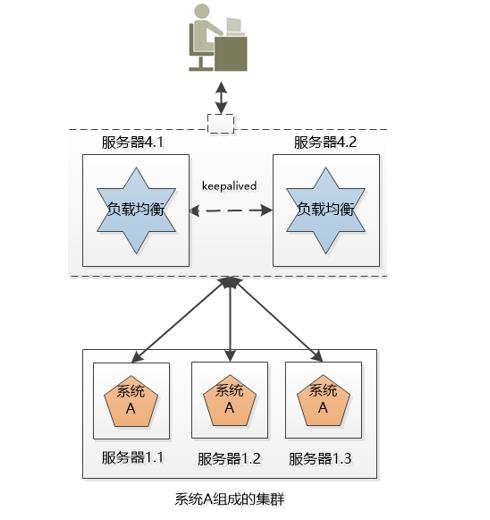
后来小明发现,这个负载均衡的服务器虽然工作内容简单,就是拿到请求,分发请求,但是它还是有可能挂掉,单点失败还是会出现。没办法,只好把负载均衡也搞成一个集群,这个集群和系统A的集群有两点不同:
1.我们可以用某种办法,让这个机器对外只提供一个IP地址,也就是用户看到的好像只有一个机器。
2.同一时刻,我们只让一个负载均衡的机器工作,另外一个原地待命,如果工作的那个挂掉了,待命的那个就顶上去。
弹性(伸缩性)
如果3个系统A的实例还是满足不了大量请求,例如双十一,可以申请增加服务器,双十一过后,新增的服务器闲置,成了摆设,于是小明决定尝试云计算,在云端可以轻松的创建,删除虚拟的服务器,那样就可以轻松的随着用户的请求动图的增减服务器了。
失效转移
上面的系统看起来很美好,但是做了一个不切实际的假设:所有的服务都是无状态的,换句话说,假设用户的两次请求直接是没有关联的。但是现实是,大部分服务都是有状态的,例如购物车。
用户访问系统,在服务器上创建了一个购物车,并向其中加了几个商品,然后服务器1.1挂掉了,用户后续访问就找不到服务器1.1了,这时候就要做失效转移,让另外几个服务器去接管,去处理用户的请求。
可是问题来了,在服务器1.2,1.3上有用户的购物车吗?如果没有,用户就会抱怨,我刚创建的购物车哪里去了?还有更严重的,假设用户登录过得信息保存到了该服务器1.1上登录的,用户登录过的信息保存到了该服务器的session中,现在这个服务器挂了,用的session就不见了,会把用户踢到了登录界面,让用户再次登录!
处理不好状态的问题,集群的威力就大打折扣,无法完成真正的失效转移,甚至无法使用。
怎么办?
一种办法是把状态信息在集群的各个服务器之间复制,让集群的各个服务器达成一致。
还有一种办法, 就是把几种状态信息存储在一个地方,让集群服务器的各个服务器都能访问到。
以上是关于2021年大数据基础:分布式技术的主要内容,如果未能解决你的问题,请参考以下文章