PR详解及二分类的PR曲线绘制
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PR详解及二分类的PR曲线绘制相关的知识,希望对你有一定的参考价值。
PR详解及二分类的PR曲线绘制
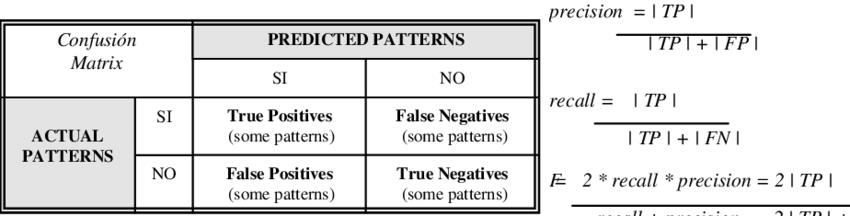
从混淆矩阵可见:
要提高Precesion,只要让预测为正样本的阈值尽可能高(最高为1,即只有当100%认为是正样本时才会被预测为正),即只有极大概率为正才会被预测为正,这样一来,在正样本数巨多的情况下,recall接近0,但precision会很高(有限的被预测为正的样本都有极大可能是正样本)
反过来,若要提高recall,只需让阈值很低,取极限,阈值为0,所有样本都被预测为正样本,那recall=1(阈值为0时,recall一定由图可见,当召回率接近于0时,模型A的精确率为0.9,模型B的精确率是1, 这说明模型B得分前几位的样本全部是真正的正样本,而模型A即使得分最高的几 个样本也存在预测错误的情况。并且,随着召回率的增加,精确率整体呈下降趋 势。但是,当召回率为1时,模型A的精确率反而超过了模型B。这充分说明,只用 某个点对应的精确率和召回率是不能全面地衡量模型的性能,只有通过P-R曲线的 整体表现,才能够对模型进行更为全面的评估。是等于1,而不是趋近于1);
以上是关于PR详解及二分类的PR曲线绘制的主要内容,如果未能解决你的问题,请参考以下文章