Python 从菜鸟到大咖的必经之路
Posted Amo Xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 从菜鸟到大咖的必经之路相关的知识,希望对你有一定的参考价值。
目录
在 超详细的 Python 基础语句总结(多实例、视频讲解持续更新) 一文中,博主详细讲解了 Python 常用的基础语句并给出了大量实例,如运算符操作、流程控制、函数定义、异常使用等,除开这些基础语句外,还有一些其他语句也是我们必须掌握的,比如文件读写、导包操作、面向对象操作、常用的一些内置函数、模块等,那本文就来对这些知识点进行补充。
一、模块和包
1.1 模块的基础知识
1. 在 Python 中,一个以 .py 为扩展名的文件就叫作一个模块(Module),每一个模块在 Python 里都是一个独立的文件。
2. 模块可以被其他模块、脚本,甚至是交互式解析器导入(import) 使用,也可以被其他程序引用。
3. 使用模块的好处。
- 提高代码的可维护性。
- 提高代码的重用性。
- 避免命名冲突,避免代码污染。
4. Python 模块分为3种类型。
- 内置标准模块,又称为标准库,如 sys、time、math、json 模块等。内置 Python 模块一般都位于安装目录下 Lib 文件夹中。
- 第三方开源模块。这类模块一般通过
pip install 模块名进行在线安装。如果 pip 安装失败,也可以直接访问模块所在官网下载安装包,在本地离线安装。 - 自定义模块。由开发者自己开发的模块,方便在其他程序或脚本中使用。
5. 自定义的模块名称不能与系统模块重名,否则有覆盖掉内置模块的风险。例如,自定义一个 sys.py 模块后,就不能再使用系统的 sys 模块。并且自定义模块名必须要符合 Python 标识符的命名规则。
6. 当 Python 解释器在源代码中解析到 import 关键字时,会自动在搜索路径中寻找对应的模块,如果发现就会立即导入。导入成功,会运行这个模块的源码并进行初始化,然后就可以使用该模块了。
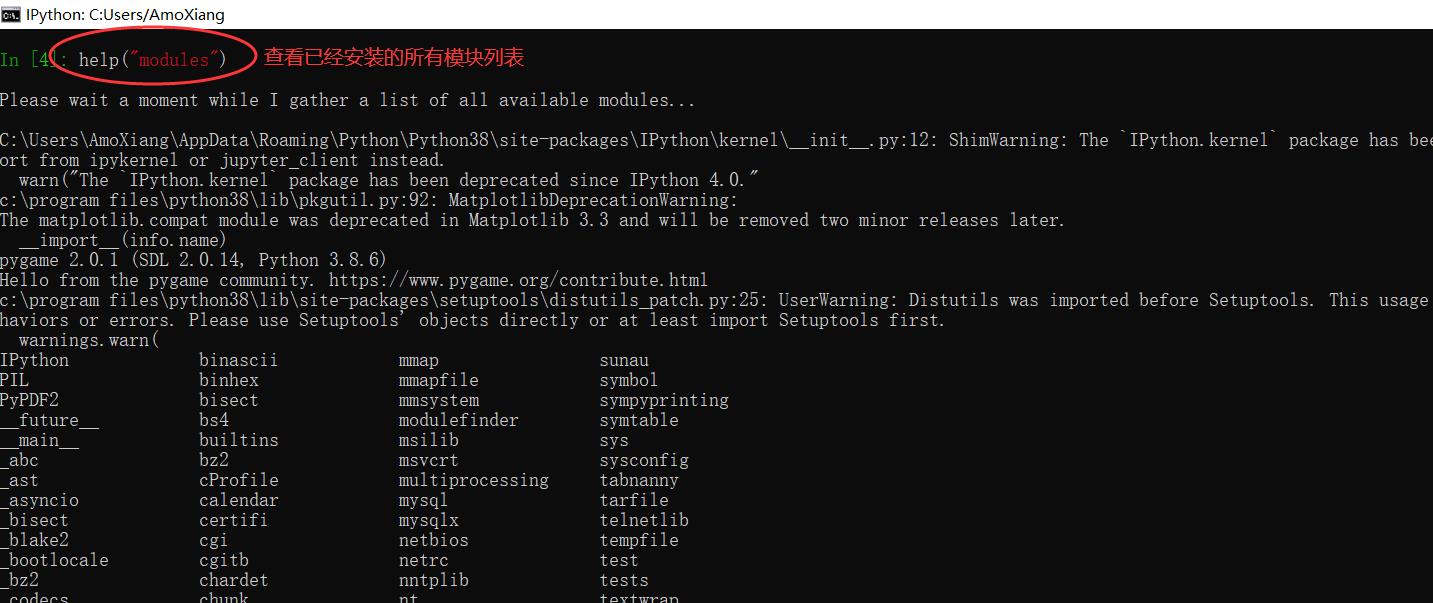
7. 模块的搜索路径。import sys sys.path查看。模块搜索顺序:当前目录 ⇒ PYTHONPATH(环境变量)下的每个目录 ⇒ Python 安装目录
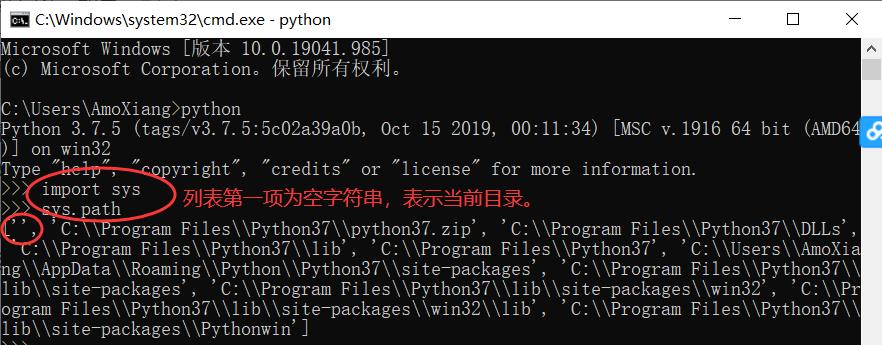
在脚本中手动添加搜索路径:
import sys
sys.path.append("路径")
1.2 模块的导入
1.2.1 import
# 1. 导入模块
import 模块名
import 模块名1, 模块名2... # 但是pep8建议分行进行模块的导入
# 2. 调用功能
模块名.功能名()
import math
print(math.sqrt(9))
# 3.导入模块之后,可以使用 dir(模块名) 方法查看该模块中可用的成员。
import math
print(dir(math))
# 4.每当导入新的模块,sys.modules 会自动记录该模块
# 5.一般 import 命令放在脚本文档的顶端。在一个文档中,
# 不管执行了多少次 import 命令,一个模块仅导入一次,防止滥用 import 命令。
1.2.2 from…import…
# 语法:from 模块名 import 功能1, 功能2, 功能3...
from random import randint
print(randint(1, 10))
1.2.3 from … import *
# 语法:from 模块名 import *
from math import *
print(sqrt(9))
1.2.4 as定义别名。如果模块名字比较长,在导入模块时可以给它起一个别名。
# 模块定义别名 语法: import 模块名 as 别名
import numpy as np
# 功能定义别名 语法: from 模块名 import 功能 as 别名
In [17]: from math import sqrt as s
In [18]: s(16)
Out[18]: 4.0
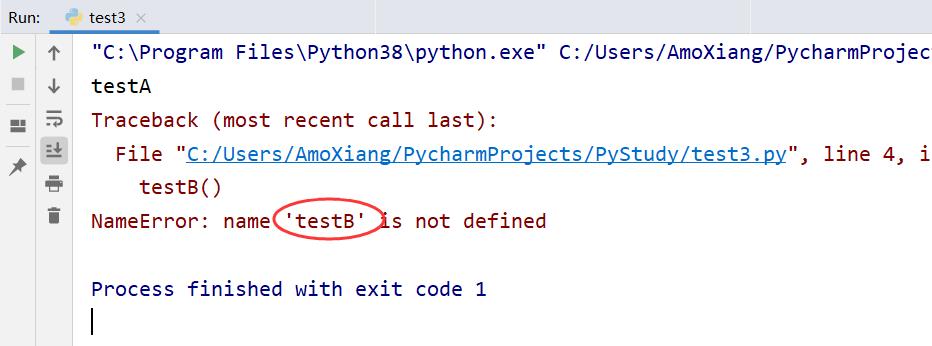
1.2.5 如果一个模块文件中有 __all__ 变量,当使用 from xxx import * 导入时,只能导入这个列表中的元素。
# test.py 代码如下
__all__ = ['testA']
def testA():
print('testA')
def testB():
print('testB')
# test3.py 代码如下
from test import *
testA()
testB()
执行结果如下图所示:
1.3 使用第三方模块
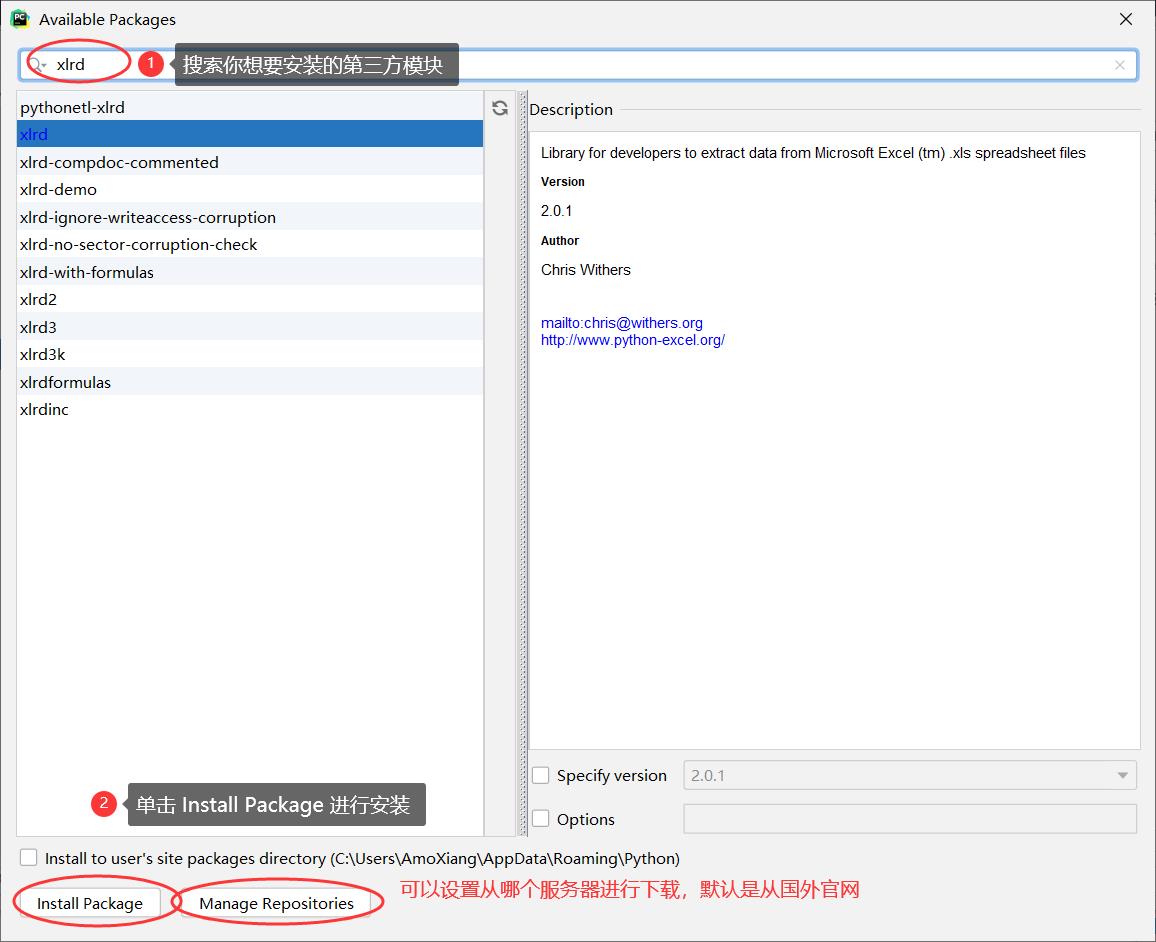
除了使用 Python 内置的标准模块外,也可以使用第三方模块。访问 https://pypi.org/,可以查看 Python 开源模块库。
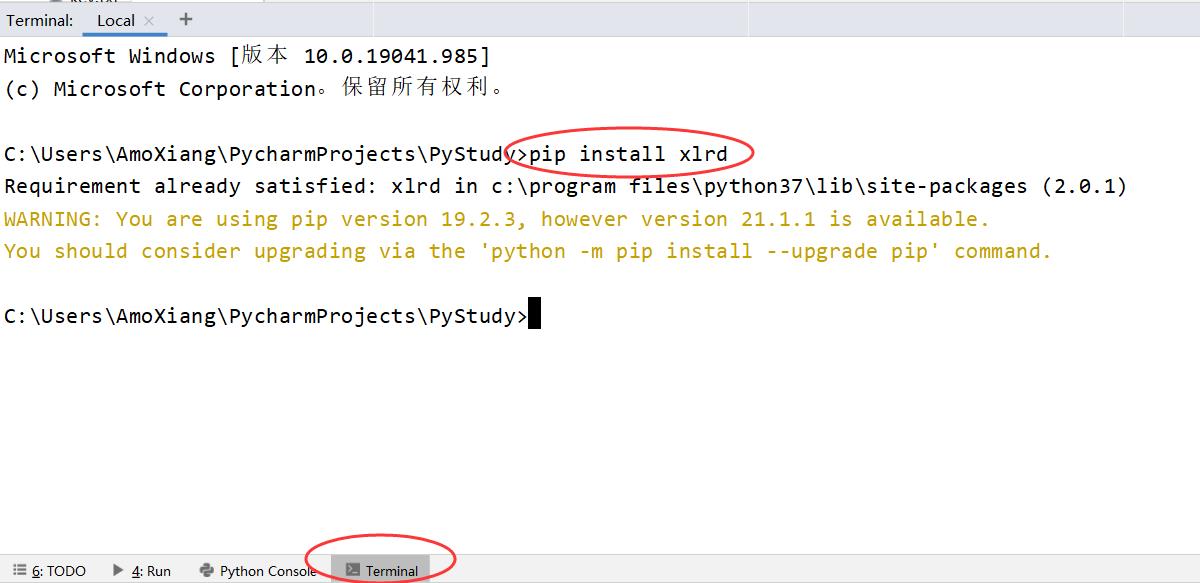
1. 使用 pip 命令安装 语法格式:pip install 模块名 默认连接在国外的 Python 官方服务器下载。
Windows 中权限不够可以使用命令:pip install --user 模块名(不能用于虚拟环境)
提高下载速度可以使用命令:
pip install --user -i http://pypi.douban.com/simple --trusted-host pypi.douban.com 模块名
pip uninstall 模块名 卸载指定模块
pip list 显示已经安装的第三方模块
pip 可以在 cmd 窗口中输入,如下图所示:

也可以在 Pycharm 下方的 Terminal 中输入,如下图所示:
2. 离线安装。在 PyPI 首页搜索模块,找到需要的模块后,单击 Download files 进入下载页面,然后可以选择下载二进制安装文件(.whl) 或者源代码压缩包(.gz)
1.对于二进制文件,直接使用 pip 命令进行安装,安装时把模块名
替换为二进制安装文件即可。注意:在命令行下要改变当前目录到安装文件的目录下。
2.对于源代码压缩包,先解压,并进入目录,然后执行下面的命令完成安装。
编译源码:python setup.py build
安装源码:python setup.py install
3. Pycharm 安装。File ⇒ Settings ⇒ Project: 你的项目名 ⇒ Python Interpreter
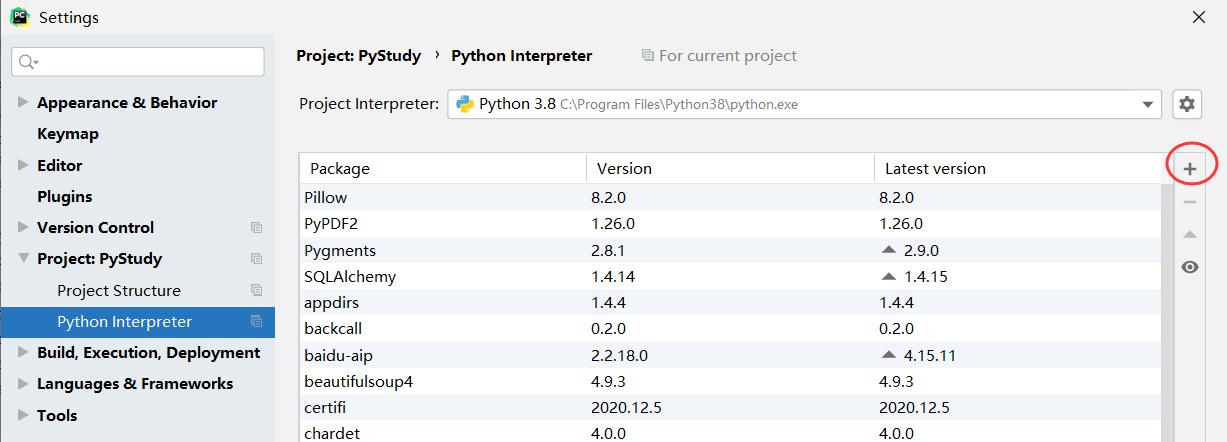
1.4 包
包将有联系的模块组织在一起,即放到同一个文件夹下,并且在这个文件夹创建一个名字为 __init__.py 文件,那么这个文件夹就称之为包。导入方式如下:
import 包名.模块名
包名.模块名.目标
from 包名 import *
模块名.目标
二、文件和目录操作
2.1 open() 函数——打开文件并返回文件对象
open() 函数用于打开文件,返回一个文件读写对象,然后可以对文件进行相应读写操作。语法格式如下:
open(filename, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
参数说明:
-
filename:必需参数,文件路径,表示需要打开文件的相对路径(相对于程序所在路径,例如,要创建或打开程序所在路径下的
test.txt文件,则可以直接写成相对路径test.txt,如果是程序所在路径下的soft子路径下的test.txt文件,则可写成soft/test.txt或者绝对路径(需要输入包含盘符的完整文件路径,如D:/test.txt)。文件路径注意需要使用单引号或双引号括起来。 -
mode:可选参数,用于指定文件的打开模式。常见的打开模式有 r(以只读模式打开)、w(以只写模式打开)、a(以追加模式打开),默认的打开模式为只读(即 r)。实际调用的时候可以根据情况进行组合,mode 参数的参数值及说明如下表所示。
模式 功能 说明 ‘t’ 文本模式 默认,以文本模式打开文件。一般用于文本文件 ‘b’ 二进制模式 以二进制格式打开文件。一般用于非文本文件,如图片等。 ‘r’ 只读模式 默认。以只读方式打开一个文件,文件指针被定位到文件头的位置。如果该文件不存在,则会报错 ‘w’ 只写模式 打开一个文件只用于写入,如果该文件已存在,则打开文件,清空文件内容,并把文件指针定位到
文件头位置开始编辑。如果该文件不存在,则创建新文件,打开并编辑。‘a’ 追加模式 打开一个文件用于追加,仅有只写权限,无权读操作。如果该文件已存在,文件指针定位到文件尾
新内容被写入到原内容之后。如果该文件不存在,则创建新文件并写入。‘+’ 更新模式 打开一个文件进行更新,具有可读、可写权限。注意,该模式不能单独使用,需要与r、w、a模式
组合使用。打开文件后,文件指针的位置由r、w、a组合模式决定。‘x’ 只写模式 新建一个文件,打开并写入内容,如果该文件已存在,则会报错。 ‘r+’ 文本格式读写 打开文件后,可以读取文件内容,也可以写入新的内容覆盖原有内容(从文件开头进行覆盖)
如果该文件不存在,则会报错。‘rb’ 二进制格式只读 以二进制格式打开文件,并且采用只读模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等。如果该文件不存在,则会报错。 ‘rb+’ 二进制格式读写 以二进制格式打开文件,并且采用读写模式。文件的指针将会放在文件的开头。一般用于非文本文件,如图片、声音等。如果该文件不存在,则会报错。 ‘w+’ 文本格式读写 打开文件后,先清空原有内容,使其变为一个空的文件,对这个空文件有读写权限 ‘wb’ 二进制格式只写 以二进制格式打开文件,并且采用只写模式。一般用于非文本文件,如图片、声音等 ‘wb+’ 二进制格式读写 以二进制格式打开文件,并且采用读写模式。一般用于非文本文件,如图片、声音等 ‘a+’ 文本格式读写 以读写模式打开文件。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写 ‘ab’ 二进制格式只写 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于写入 ‘ab+’ 二进制格式读写 以二进制格式打开文件,并且采用追加模式。如果该文件已经存在,文件指针将放在文件的末尾(即新内容会被写入到已有内容之后),否则,创建新文件用于读写 -
buffering:可选参数,用于指定读写文件的缓冲模式,值为 0 表示不缓冲,直接写入磁盘;值为 1 表示缓冲(默认为缓冲模式),缓冲区碰到 \\n 换行符时写入磁盘;如果大于 1,则缓冲区文件大小达到该数字大小时,写入磁盘。
-
encoding:表示读写文件时所使用的文件编码格式,一般使用 UTF-8。
-
errors:表示读写文件时碰到错误的报错级别。
-
newline:表示用于区分换行符(只对文本模式有效,可以取的值有 None、’\\n’、’\\r’、’\\r\\n’)
-
closefd:表示传入的 file 参数类型(缺省为True),传入文件路径时一定为 True,传入文件句柄则为 False。
-
opener:传递可调用对象。
2.2 文件操作的常用方法
打开文件后对文件读取操作通常有三种方法:read() 方法表示读取全部内容;readline() 方法表示逐行读取;readlines() 方法表示读取所有行内容。下面分别进行介绍。
1. read() 方法。读取文件的全部或部分内容,对于连续的面向行的读取,则不使用该方法。语法如下:
fp.read([size])
其中,size 为可选参数,用于指定要读取文件内容的字符数(所有字符均按一个计算,包括汉字,如 name:无 的字符数为 6),如 read(8),表示读取前 8 个字符。如果省略,则返回整个文件的内容。注意:使用 read() 方法读取文件内容时,如果文件大于可用内存,则不能实现文件的读取,而是返回空字符串。
2. readline() 方法。返回文件中一行的内容,具体语法为:
file.readline([size])
其中,size为可选参数,用于指定读取一行内容的范围,如 readline(8),表示指读取一行中前8个字符的内容。如果省略,则返回整行的内容。
3. readlines() 方法。返回一个列表,列表中每个元素为文件中的一行数据,语法如下:
file.readlines()
除了对文件读取操作,还可以对文件进行写入、获取文件指针位置和关闭文件等操作。具体方法如下:
4. write() 方法。将内容写入文件,语法如下:
f.write(obj)
其中,obj 为要写入的内容。
5. tell() 方法。返回一个整数,表示文件指针的当前位置,即在二进制模式下距离文件头的字节数,语法如下:
f.tell()
说明:使用 tell() 方法返回的位置与为 read() 方法指定的 size 参数不同。tell() 方法返回的不是字符的个数,而是字节数,其中汉字所占的字节数根据其采用的编码有所不同,如果采用 GBK 编码,则一个汉字按两个字符计算;如果采用 UTF-8 编码,则一个汉字按 3 个字符计算。
6. seek() 方法。将文件的指针移动到新的位置,位置通过字节数进行指定。这里的数值与tell()方法返回的数值的计算方法一致。语法如下:
file.seek(offset[,whence])
参数说明:
- file:表示已经打开的文件对象;
- offset:用于指定移动的字符个数,其具体位置与whence有关;
- whence:用于指定从什么位置开始计算。值为 0 表示从文件头开始计算, 1 表示从当前位置开始计算,2 表示从文件尾开始计算,默认为 0。
7. close() 方法。关闭打开的文件,语法如下:
file.close()
2.3 应用
【示例1】常用文件读取操作。
""" 一次读取文件的全部内容"""
f = open('test.txt') # 以只写模式打开文件
f.read()
print('--------------------------------------')
f = open('test.txt') # 以只写模式打开文件
lines = f.readline(20000) # 设置读取的字符足够大
print(lines) # 输出读取到的文件内容
f.close() # 关闭文件
print('--------------------------------------')
''' 读取文件或者每行的前几个字符'''
f = open('test.txt') # 以只写模式打开文件
f.read(8)
print('--------------------------------------')
f = open('test.txt') # 以只写模式打开文件
while True:
line = f.readline(5) # 一次读取一行中的5个字符
print(line) # 输出读取的内容
if line == '': # 如果读取的内容为空
break # 跳出循环
f.close() # 关闭文件
print('--------------------------------------')
''' 逐行读取文件内容'''
f = open('test.txt') # 以只写模式打开文件
line = f.readline() # 读取一行
while line:
print(line) # 输出读取的一行内容
line = f.readline() # 读取一行
f.close() # 关闭文件
print('--------------------------------------')
f = open('test.txt') # 以只写模式打开文件
while True:
line = f.readline() # 读取一行
print(line) # 输出读取的一行内容
if line == '': # 如果读取的内容为空
break # 跳出循环
f.close() # 关闭文件
print('--------------------------------------')
for line in open('test.txt'):
print(line) # 输出一行内容
【示例2】使用 with open 语句打开文件。
with open('test.txt', 'r') as f: # 以只读方式打开文件
print(f.read()) # 读取全部文件内容并输出
with open('test.txt', 'r') as f: # 以只写模式打开文件
lines = f.readlines() # 读取全部内容
for line in lines: # 遍历每行内容
print(line.rstrip()) # 输出每行中去掉右侧空白字符的内容
【示例3】在相对路径下创建或写入文件。
with open('lift.txt', 'w') as f: # 以只写模式打开文件
f.write('生命美妙之处, 就在于你的勇气会成就更美的你。')
【示例4】读取操作文件时去除空格,空行等。
with open('lift.txt', 'r') as f: # 以只读模式打开文件
for line in f.readlines():
print(line.strip()) # 去除空格
print(line.strip('\\n')) # 去除换行符
print(line.strip('\\t')) # 去除制表符
【示例5】读取非UTF-8编码的文件。
with open('test.txt', 'r', encoding='gbk') as f: # 以只读模式打开文件
print(f.readlines()) # 读取全部内容
with open('test.txt', 'r', encoding='gbk', errors='ignore') as f: # 以只读模式打开文件
print(f.readlines()) # 读取全部内容
【示例6】在指定目录(绝对路径)下生成TXT文件。
with open('D:/lift.txt', 'w') as fp: # 以只写模式打开文件
fp.write(' *' * 10 + '生命之美妙' + ' *' * 10)
fp.write('\\n 生命美妙之处, 就在于你的勇气会成就更美的你。')
【示例7】以二进制方式打开图片文件。
file = open('python.jpg', 'rb') # 以二进制方式打开图片文件
print(file)
【示例8】多个文件的读取操作。
f1 = open('lift.txt', 'r') # 打开一个文件,命名为f1
f2 = open('test.txt', 'r') # 打开一个文件,命名为f2
f3 = open('digits.txt', 'r') # 打开一个文件,命名为f3
i = f1.readline() # 读取一行
j = f2.readline() # 读取一行
k = f3.readline() # 读取一行
print(i, j, k) # 输出读取到的数据
f1 = open('lift.txt', 'r') # 打开一个文件,命名为f1
f2 = open('test.txt', 'r') # 打开一个文件,命名为f2
f3 = open('digits.txt', 'r') # 打开一个文件,命名为f3
for i, j, k in zip(f1, f2, f3): # 读取每个文件的内容
print(i, j, k)
【示例9】读取一个文件夹下所有文件。
import os # 导入文件与系统操作模块
path = './temp' # 待读取文件的文件夹相对地址
names = os.listdir(path) # 获得目录下所有文件的名称列表
all_list = [] # 保存文件信息的列表
for item in names: # 读取每一个文件
f = open(path + '/' + item, encoding="utf8") # 打开文件
new = [] # 保存单个文件内容的列表
for i in f: # 按行读取文件内容
new.append(i)
all_list.append(new) # 将new添加到列表中
for i in all_list: # 遍历并输出列表
print(i)
【示例10】将文件的写入和读取写入类。
class Operatxt(object): # 定义操作文件类
def __init__(self, encoding):
self.enc = encoding
def write_txt(self, s): # 写入文件的方法
with open("test.txt", "a+", encoding=self.enc) as fileInfo:
fileInfo.write(s) # 写入内容
def read_txt(self): # 读取文件的方法
with open("test.txt", "r", encoding=self.enc) as fileInfo:
con = fileInfo.read() # 读取全部文件内容
return con
# 接收用户输入,将输入内容写入到文件,同时询问用户是读取文件还是继续写入文件
# 当用户选择读取文件时,将前面已经写入的内容读取出来并输出给用户,然后结束用户输入
while True:
content = input("请输入要写入到文件的内容:")
ot = Operatxt("utf-8") # 创建操作文件类的对象,指定编码为UTF-8
ot.write_txt(content) # 写入文件内容
yn = input("内容已写入文件,是否要读取?输入y则读取文件,继续写入请输入n:")
if yn == 'y':
s = ot.read_txt() # 读取文件
print("文件内容为:", s) # 输出文件内容
break # 退出循环
【示例11】查看文件最后一行。
with open("Grade.txt", "rb") as f:
data = f.readlines()
print("最后一行为:", data[-1].decode("utf-8")) # 解码方式以实际为准
with open("Grade.txt", "rb") as f:
data = list(f)[-1]
print("最后一行为:", data.decode("utf-8")) # 解码方式以实际为准
with open("Grade.txt", "rb") as f:
obj = f.__iter__() # 获取迭代器对象
print("最后一行为:", list(obj)[-1].decode("utf-8")) # 解码方式以实际为准
with open("Grade.txt", "rb") as f:
for i in f:
offset = -10 # 光标定位偏移量,根据实际情况调整其大小
while True:
f.seek(offset, 2) # 光标定位从文件尾部开始向前计数
data = f.readlines()
if len(data) > 1:
end_data = data[-1]
print("最后一行数据为:", end_data.decode("utf-8")) # 解码方式以实际为准
break
offset *= 2
三、面向对象
3.1 面向对象基础语法
# -*- coding: utf-8 -*-
# @Time : 2019/12/9 14:33
# @Author : 我就是任性-Amo
# @FileName: 1.面向对象基础语法.py
# @Software: PyCharm
# @Blog :https://blog.csdn.net/xw1680
"""
1.类: 类是对一群具有相同特征或者行为的事物的一个统称,是抽象的,不能直接使用
特征被称为属性
以上是关于Python 从菜鸟到大咖的必经之路的主要内容,如果未能解决你的问题,请参考以下文章