Pytorch学习笔记
Posted Real&Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch学习笔记相关的知识,希望对你有一定的参考价值。
Pytorch学习笔记
-
class torchvision.transforms.RandomCrop(size, padding=0)
切割中心点的位置随机选取。size可以是tuple也可以是Integer。 -
class torchvision.transforms.RandomHorizontalFlip
随机水平翻转给定的PIL.Image,概率为0.5。即:一半的概率翻转,一半的概率不翻转。 -
class torchvision.transforms.ToTensor 转为tensor:transforms.ToTensor
功能:将PIL Image或者 ndarray 转换为tensor,并且归一化至[0-1]
注意事项:归一化至[0-1]是直接除以255,若自己的ndarray数据尺度有变化,则需要自行修改。 -
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None, num_workers=0, collate_fn=, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None): 数据加载器。组合了一个数据集和采样器,并提供关于数据的迭代器。
-
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
milestones为一个数组,如 [50,70]. gamma为倍数。如果learning rate开始为0.01 ,则当epoch为50时变为0.001,epoch 为70 时变为0.0001。 -
当last_epoch=-1,设定为初始lr。
-
当网络中有 dropout,bn 的时候。训练的要记得 net.train(), 测试 要记得 net.eval()
-
在测试的时候 创建输入 Variable 的时候 要记得 volatile=True
-
torch.sum(Tensor), torch.mean(Tensor) 返回的是 python 浮点数,不是 Tensor。
在不需要 bp 的地方用 Tensor 运算。
Batch Normalization
BN主要时对网络中间的每层进行归一化处理,并且使用变换重构(Batch Normalizing Transform)保证每层所提取的特征分布不会被破坏,详细参加Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。该算法主要如下:

训练时是正对每个min-batch的,但是在测试中往往是针对单张图片,即不存在min-batch的概念。由于网络训练完毕后参数都是固定的,因此每个批次的均值和方差都是不变的,因此直接结算所有batch的均值和方差。所有Batch Normalization的训练和测试时的操作不同
Dropout
Dropout能够克服Overfitting,在每个训练批次中,通过忽略一半的特征检测器,可以明显的减少过拟合现象,详细见文章:Dropout: A Simple Way to Prevent Neural Networks from Overtting具体如下所示:
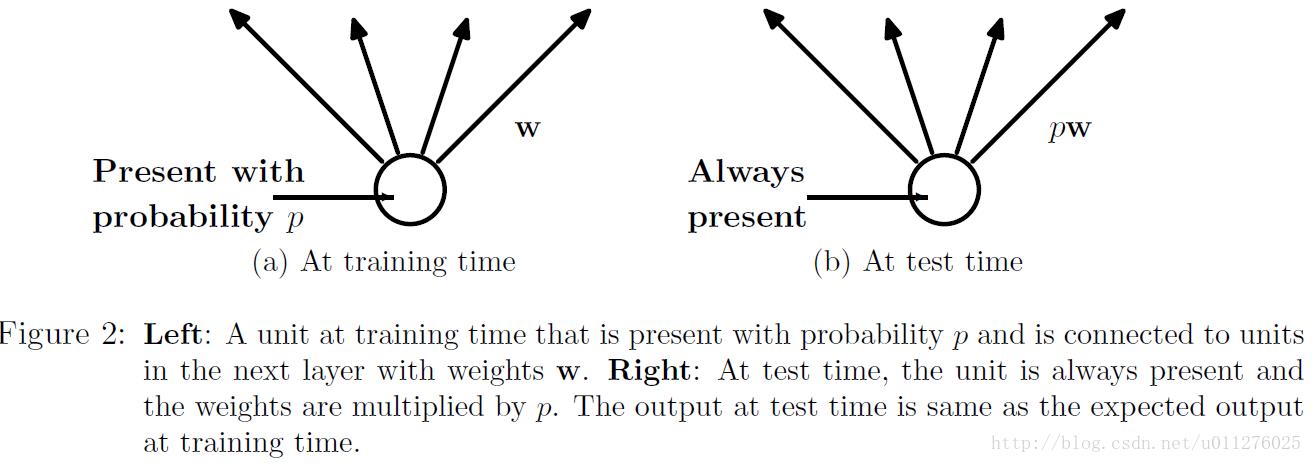
在训练中,每个隐层的神经元先乘概率P,然后在进行激活,在测试中,所有的神经元先进行激活,然后每个隐层神经元的输出乘P。
optim.lr_scheduler.ReduceLROnPlateau(opt, ‘min’, factor=0.5)
class torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.1, patience=10,
verbose=False, threshold=0.0001, threshold_mode='rel', cooldown=0, min_lr=0, eps=1e-08)
optimer指的是网络的优化器
- mode (str) ,可选择‘min’或者‘max’,min表示当监控量停止下降的时候,学习率将减小,max表示当监控量停止上升的时候,学习率将减小。默认值为‘min’
- factor 学习率每次降低多少,new_lr = old_lr * factor
- patience=10,容忍网路的性能不提升的次数,高于这个次数就降低学习率
- verbose(bool) - 如果为True,则为每次更新向stdout输出一条消息。 默认值:False
- threshold(float) - 测量新最佳值的阈值,仅关注重大变化。 默认值:1e-4
- cooldown: 减少lr后恢复正常操作之前要等待的时期数。 默认值:0。
- min_lr,学习率的下限
- eps ,适用于lr的最小衰减。 如果新旧lr之间的差异小于eps,则忽略更新。 默认值:1e-8。
optimizer.param_groups
- optimizer.param_groups:是长度为2的list,其中的元素是2个字典;
- optimizer.param_groups[0]:长度为6的字典,包括[‘amsgrad’, ‘params’, ‘lr’, ‘betas’, ‘weight_decay’, ‘eps’]这6个参数
- optimizer.param_groups[1]:好像是表示优化器的状态的一个字典
torch.optim.lr_scheduler.MultiStepLR(optimizer, milestones, gamma=0.1, last_epoch=-1)
milestones为一个数组,如 [50,70]. gamma为倍数。如果learning rate开始为0.01 ,则当epoch为50时变为0.001,epoch 为70 时变为0.0001。
以上是关于Pytorch学习笔记的主要内容,如果未能解决你的问题,请参考以下文章