R语言时间序列分析常用步骤
Posted 基督徒Isaac
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言时间序列分析常用步骤相关的知识,希望对你有一定的参考价值。
常用步骤代码:
#载入数据
d <- WWWusage
x <- ts(d,start = 1) # 其实WWWusage本身就是时间序列格式的,这里是为了提醒大家记得ts
plot(x)
#差分并观察
x.dif <- diff(x,1,2)
plot(x.dif)
#差分序列ADF检验
library(tseries)
adf.test(x.dif) # p越小越好
#确定差分阶数d
#序列纯随机性检验
for(i in 1:2)print(Box.test(x.dif, lag=6*i))
#p大,拒绝序列为白噪声的假设,说明序列有规律可提取,有研究价值,可继续建模
#判断p、q
acf(x.dif)
pacf(x.dif)
#根据auto.arima辅助判断
library(forecast)
auto.arima(x.dif) # AIC 实际值越小越好
x.fit <- arima(x.dif,order = c(2,0,0));x.fit
#多对比几次结果
#AIC是赤池统计量,当增加了一个变量后,如果这个变量对模型有足够的解释力,就会使赤池统计量变小
#AIC的值为负的时候也是越小越好,也就说是实际值而不是绝对值越小越好,比如-2与-1.9,就选-2那个
#AIC和BIC是似然函数和乘法函数的线性组合,不同之处在于惩罚力度不同。都是越小越好
#loglik是对数似然,模型比较时越大越好
#残差白噪声检测,考察拟合效果,p越大,说明残差纯随机性越显著,信息充分提取
for(i in 1:2) print(Box.test(x.fit$residuals,lag = 6*i))
#通过检测的模型进行预测
library(zoo)
library(forecast)
x.fore <- forecast(x.fit,h = 10) #预测未来10期
plot(x.fore)
x.fore模型阶数判定:
以datasets包自带WWWusage数据为例,2阶差分后拟合模型,AIC实际值(不是绝对值)越小越好,实验如下:
win.graph();par(mfrow=c(1,2));acf(x.dif);pacf(x.dif)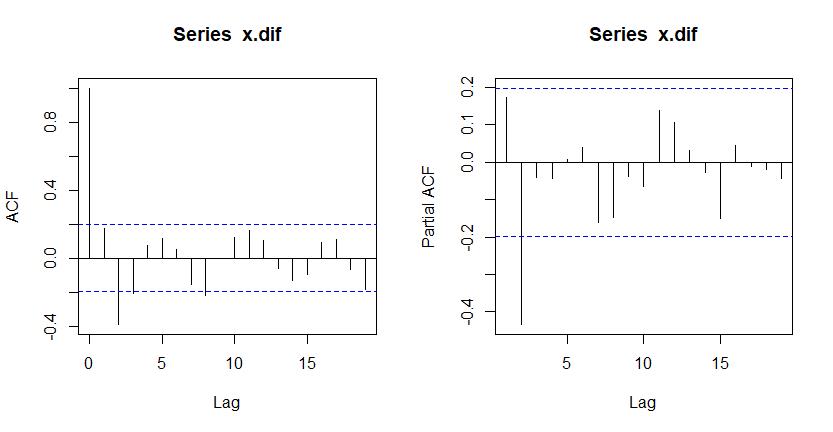
结合acf图和pacf图,结果似乎是p=2,q=2最佳,但对比AIC值却不是如此:
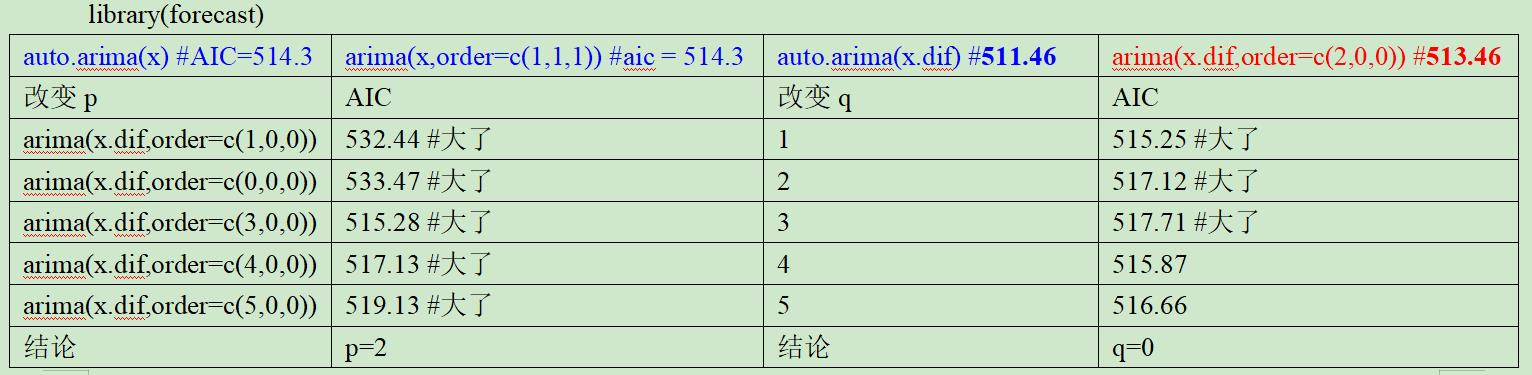
结果表明对x <- ts(WWWusage)来说,arima(2,2,0)的拟合效果最好,AIC值为511.46。
为什么偏自相关图判断的结果不是拟合效果最好的呢?希望哪位老师同学可以指点我,谢谢!
我的微信:1961812312
更新:
之前没有对p,q作为组合代入模型寻找最小aic值,
在下一篇文章中,分析了36种组合的结果,找到aic值最小的结果为p=5,q=5,aic值为509.8135
但还是与自相关图和偏自相关图结果给出的建议不一样,这一点还是希望有老师同学指点一下!
参考文献:
https://people.duke.edu/~rnau/411arim.htm
https://bbs.pinggu.org/forum.php?mod=viewthread&action=printable&tid=226732
https://bbs.pinggu.org/thread-3226868-1-1.html
https://www.zybuluo.com/evilking/note/851533
wikimirror
感谢上帝的恩典。
另:根据ARIMA模型得到公式结果,可以参考wiki和Google的镜像资料代入得出。
更新:
以上是关于R语言时间序列分析常用步骤的主要内容,如果未能解决你的问题,请参考以下文章