数据流压缩原理实现(huffman编码,LZ77压缩算法)
Posted sesiria
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据流压缩原理实现(huffman编码,LZ77压缩算法)相关的知识,希望对你有一定的参考价值。
1. 压缩原理deflate算法
a) LZ77 算法原理
b) Huffman算法原理
c) Huffman算法测试实例
2. 关于zlib库的实际应用以及gzip格式分析查看下一篇
一、数据压缩的原理
规则压缩:已知数据的排列组合模式,通过抽象用数学公式来表示。比如矢量图,3D模型的顶点数据等。
对于未知规则的数据:则是采用一种更高效的编码来代替原有数据的编码。一种方法是找出数据中那些重复出现的字符串,然后用更短的符号代替。
比如有一条句子中大量出现了以下短语:
“中华人民共和国”
如果通过一种映射关系,用"中国"来代替它,则就缩短了5个字符,如果用"华"来代替,则缩短了6个字符。
只要保证前后的队应关系,可以用任意字符来代替那些重复出现的字符。
本质上,“压缩”就是找出文件内容的概率分布,将那些出现概率高的部分代为更短的形式。所以内容越是重复的文件,可以压缩的更小。
比如 "ABABABABABABAB" 可以通过一种编码压缩成 "7AB"
相应地,如果内容毫无重复,就很难压缩。极端情况就是,遇到那些均匀分布的随机字符, 可能往往一个字符都压缩不了。
比如 任意排列的10个阿拉伯数字。 (5271839406) 就是无法压缩的;再比如,无理数(Π)也很难压缩。
1. 压缩极限
香农极限定理:假设一个串可以用N种符号来编码表示,每种符号出现的概率为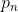
定义信息熵:表示编码这段信息需要的二进制比特数。
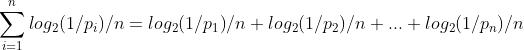
1)下面是一个例子。假定两个文件都包含1024个符号,在ASCII码的情况下,它的长度是相等的,都是1KB。
甲文件的内容50%是a, 30%是b, 20%是c, 文本里只有abc, 则根据上面信息熵的定义。平均每个符号要占用1.49个二进制位。
计算过程如下
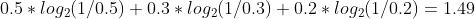
2)比如每个字节的概率是0~255, 均匀分布每个数值出现的概率是1/256 ,如果一段文字的字节值是平均分布,则 pn = 1/ 256, 计算出极限位8 (bit).
2. Deflate压缩算法
deflate是zip压缩文件的默认算法。其实deflate不光用在zip文件,7z,xz等其他压缩文件中都使用。它是一种压缩数据流的算法。任何需要流式压缩的地方都可以使用。
deflate算法下的压缩器有三种压缩模型:
1)不压缩数据,对于已经压缩过的数据,这是一种明智的选择。
2)压缩,先用LZ77, 然后再用huffman编码。在这个模型中压缩的树是Deflate规范定义的,所以不需要额外空间来存储这个树。
3)压缩,先用LZ77, 然后用huffman编码。压缩树是由压缩器生成的,并于数据一起存储。
数据被分割成不同的块,每个快使用单一的压缩模式。如果压缩器要在这三种压缩模式中互相切换,必须先结束当前的快,重新开始一个新的块。
3. 信息熵
数据为何是可以压缩的?因为数据都会表现出一定的特性,称为信息熵。(也就是上面的香农极限定理)绝大多数的数据锁表现出来的容量往往大于其信息熵锁建议的最佳容量。
也就是数据会存在一定的冗余性,我们可以把冗余的数据采用更少的位对频繁出现的字符进行标记,也可以基于数据的一些特性基于字典编码,代替重复多余的短语。
二. LZ77算法原理
Ziv 和 Lempel 于 1977 年发表题为“顺序数据压缩的一个通用算法(A Universal Algorithm for Sequential Data Compression ) 。 LZ77 压缩算法采用字典的方式进行压缩,
是一个简单但十分高效的数据压缩算法。其方式就是把数据中一些可以组织成短语(最 长字符)的字符加入字典,然后再有相同字符出现采用标记来代替字典中的短语,如此通
过标记代替多数重复出现的方式以进行压缩。要理解这种算法, 需先了解 3 个关键词:短语字典,滑动窗口和向前缓冲区。
1. 关键词术语
a. 向前缓冲区
每次读取数据的时候,先把一部分数据预载入前向缓冲区。为移入滑动窗口做准备。
b. 滑动窗口
一旦数据通过缓冲区,那么它将以动到滑动窗口中,编程字典的一部分。滑动窗口需要预设一个定值。
c. 短语字典
从字符序列S1 .... Sn, 组成n个短语。比如字符(A,B,D),可以组合的短语为 {(A), (A,B), (A, B, D), (B), (B, D), (D)}
如果这些字符在滑动窗口里面,就可以记为当前短语的字典,因为滑动窗口不断向前滑动,所以短语字典也是不断的变化。
LZ77的主要是废逻辑 是,先通过前向缓冲区预读取数据,然后再向滑动窗口移入(滑动窗口有一定的长度), 不断寻找能与字典中短语匹配的最长短语,然后通过标记符标记。
比如以字符“ABD”为例子,看下图:
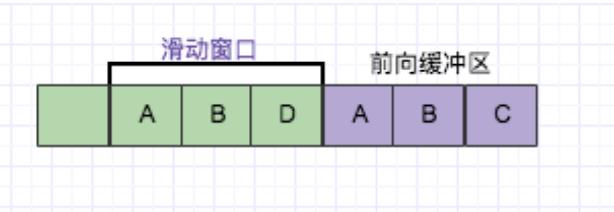
目前,前向缓冲区中可以与滑动窗口中可以匹配的最长短语就是 “AB", 然后向前移动的时候再次遇到
(A,B)的时候采用标记符代替。
2. LZ77压缩算法
在数据压缩的过程中,前向缓冲区与滑动窗口之间在做短语匹配的时候会存在2种情况:
1)找不到匹配时,将未匹配的符号编码成符号标记(多数都是字符本身)
2)找到匹配时,将其最长的匹配编码成短语标记
短语标记包含三部分信息:
1)滑动窗口的偏移量(从匹配开始的地方计算);
2) 匹配中的符号个数;
3) 匹配结束后的前向缓冲区中的第一个符号。
一旦把n个符号编码并生成相应的标记,就将这n个符号从滑动窗口一端移出,并用前向缓冲区中同样数量的符号来代替他们,
如此,滑动窗口中始终有最新的短语。
可以看以下图例:
1) 开始

2)滑动窗口终没有数据,所以没有匹配到短语,将字符A标记为A

3)滑动窗口中有A,没有从缓冲区中字符(BABC)中匹配到短语,依然把B标记为B

4)缓冲区字符(ABCB)在滑动窗口的位移6位置找到AB, 成功匹配到短语AB, 将AB编码为(6,2,C),之所以是6,是因为窗口的A在滑动窗口的索引[6]的位置。

5. 缓冲区字符(BABA)在滑动窗口位移4的位置匹配到短语BAB, 将BAB编码为(4,3,A), 因为B在滑动窗口中的起使位置索引是4.


6. 缓冲区字符(BCAD)在滑动窗口位移2的位置匹配到短语BC, 将BC编码为(2,2,A)

7. 缓冲区字符D,在滑动窗口中没有找到匹配短语,标记为D

8. 缓冲区中没有数据进入了,结束

这就完成了整个LZ77的编码过程
以下代码将实现LZ77的编码(压缩)
typedef std::tuple<int, int, char> encodeUnit;
// the longestMatch will be used by the LZ77 compress funciton.
encodeUnit longestMatch(const std::string& inputBuffer, int cursor, int windowSize, int bufferSize) {
int pos = -1;
int len = -1;
char c = '\\0'; // the candidate string.
int endBuffer = std::min(cursor + bufferSize, (int)inputBuffer.size());
// i indicate the end of the candidate substring.
// we search from a max silding window to small,
// as a result, if we find a match it must be the longestMatch one.
int startIndex = std::max(0, cursor - windowSize); // the start position of the window
for (int i = endBuffer; i > cursor; i--) {
std::string subStr(inputBuffer, cursor, i - cursor);
// the candidate string.
for (int j = startIndex; j < cursor && (cursor - j) >= subStr.size(); j++) {
std::string candidate(inputBuffer, j, subStr.size());
if (candidate == subStr) {
pos = j + windowSize - cursor;
len = candidate.size();
// if we meet the end of the string.
//adjust the length.
if (i == endBuffer) {
len--;
i--;
}
c = inputBuffer[i];
break;
}
}
// there is a match
if (len != -1)
break;
}
// if there is not any match we push the current character
if (pos == -1 || len == -1)
return std::make_tuple(0, 0, inputBuffer[cursor]);
return std::make_tuple(pos, len, c);
}
/* the compress routine of the Lz77 algorithm.
inputBuffer: the buffer to be compressed.
windowSize: the size of the sliding window
bufferSize: the size of the buffer.
the output is a vector of the tuples which indicates the pos, len, and the next character.
*/
std::vector<encodeUnit> lz77Compress(const std::string& inputBuffer, int windowSize, int bufferSize)
{
int lenData = inputBuffer.size();
int curSor = 0;
std::vector<encodeUnit> compressData;
while (curSor < lenData) {
auto ret = longestMatch(inputBuffer, curSor, windowSize, bufferSize);
curSor += (std::get<1>(ret) + 1);
compressData.push_back(ret);
}
return compressData;
}
输出结果:

3. LZ77 解压
解压类似于压缩的逆向过程,通过解码标记和保持滑动窗口中的符号来更新解压数据。
字符标记:直接将标记编码的字符拷贝到滑动窗口中
短语标记:在滑动窗口中查找相应的偏移量,同时找到指定长短的短语进行替换。
1)开始

2)符号标记A解码

3)符号标记B解码

4. 短语标记(6, 2, C)解码

根据步骤3中的索引[6]开始,得到AB, 就是重复AB再加上C,就变成了ABABC,并且滑动窗口滑到最右边的位置
5. 短语标记(4, 3, A)解码

6. 短语标记(2, 2, A)解码

7. 符号标记D解码

优缺点:
大多数情况下LZ77压缩算法的压缩 比相当高,当然也和选择的滑动窗口大小以及前向缓冲区大小,以及数据熵有关系。 其压缩过程是比较和耗时的。因为要花费很多事件寻找滑动窗口中的短语匹配。
不过解压的过程会很快,因为每个标记都明确告知在哪个位置可以读取了。
解压算法的实现:
/* the decompress routine of the Lz77 algorithm.
compressedData: the compressed data include vector of tuples (pos, len, character).
windowSize: the size of the sliding window
bufferSize: the size of the buffer.
the output is a string of the decompress data.
*/
std::string lz77Decompress(std::vector<encodeUnit>& compressedData, int windowSize, int bufferSize)
{
int cursor = 0;
std::string out;
for (auto& unit : compressedData) {
int pos = std::get<0>(unit), len = std::get<1>(unit);
char c = std::get<2>(unit);
// normal character
if (len > 0)
out.append(std::string(out, cursor - windowSize + pos, len));
out.append(1, c);
cursor += (len + 1);
}
return out;
}测试用例:
// test functions
void printEncodeUnit(const encodeUnit& eu) {
std::cout << std::get<0>(eu) << ", ";
std::cout << std::get<1>(eu) << ", ";
std::cout << std::get<2>(eu) << "\\n";
}
void testLZ77Compress()
{
std::string str = "ABABCBABABCAD";
//std::string str = "ABCDEFABCDEF";
auto compressData = lz77Compress(str, 8, 8);
for (auto& e : compressData)
printEncodeUnit(e);
}
void testLZ77Decompress()
{
std::string str = "ABABCBABABCAD";
//std::string str = "ABCDEFABCDEF";
auto compressData = lz77Compress(str, 8, 8);
auto ret = lz77Decompress(compressData, 8, 8);
assert(ret == str);
if (ret == str)
std::cout << "test decompress successful!\\n";
else
std::cout << "test decompress failed!\\n";
}
int main()
{
testLZ77Compress();
testLZ77Decompress();
return 0;
}运行结果如下:

三. Huffman算法原理
1. 前缀码
在一个字符集中,任何一个字符的编码都不是另一个字符编码的前缀,即前缀码。例如,有两个码字,111与1111. 这两个码字就不符合前缀码的规则,因为111是1111的前缀。
放到二叉树里来讲,只用叶子节点编码的码才是前缀码。如果同时使用中间节点和叶子节点编码,那结果就不是前缀码。因为压缩经过编码的码字全部都是前缀码,所以在对
照码表解压的时候,碰到哪个码字就是哪个码字,不用哦杠担心出现某个字符的编码是另一个字符编码的前缀的情况。
关于前缀码,参考算法导论中的定义:”前缀码的作用是简化解码过程。由于没有码字是其他码字的前缀,编码文件的开始码字是无歧义的“
2. 哈弗曼编码
哈夫曼设计了一个贪心算法来构造最优前缀码,被称为哈夫曼编码(huffman code)。哈夫曼编码可以很有效的压缩数据,具体压缩率依赖于数据本身的特性。首先定义几个概念:
码字: 每个字符可以用一个唯一的二进制串来表示,这个二进制串称为这个字符的码字。
码长:这个二进制串的长度称为这个码字的码字长度。
定长编码:码长固定的编码
变长编码:码长度不同的编码
哈夫曼编码是基于哈夫曼树来构造的,比如以下例子:
| 字符 | a | b | c | d | e | f |
| 出现频率 | 45 | 13 | 12 | 16 | 9 | 5 |
构造过程如下图所示






哈夫曼树的构建步骤如上图,在一开始每个字符都已经按照出现频率大小排好顺序,在后续的步骤中,每次都将频率最低的两颗树合并,然后用合并的树再次排序。(这里可以使用最小堆实现)。在构建好哈夫曼树以后,从根节点开始向左为0,向右为1.一次遍历到叶节点路径的编码即为一个字符的码字。
| 字符 | a | b | c | d | e | f |
| 出现频率 | 45 | 13 | 12 | 16 | 9 | 5 |
| 编码 | 0 | 101 | 110 | 111 | 1101 | 1100 |
利用最小堆实现的huffman树
/**
* The Huffman Tree algorithm implementation
* FileName: HuffmanTree.hpp
* Author: Sesiria 2021-05-22
* Not support concurrency!
*/
#ifndef _HUFFMAN_TREE_H_
#define _HUFFMAN_TREE_H_
#include <iostream>
#include <queue>
#include <vector>
// the definition of the huffmanTreeNode struct
template <typename T>
struct HuffmanTreeNode
{
HuffmanTreeNode(const T&weight,
HuffmanTreeNode * pLeft = nullptr,
HuffmanTreeNode * pRight = nullptr,
HuffmanTreeNode * pParent = nullptr)
:_pLeft(pLeft),
_pRight(pRight),
_pParent(pParent),
_weight(weight)
{
}
HuffmanTreeNode * _pLeft;
HuffmanTreeNode * _pRight;
HuffmanTreeNode* _pParent;
T _weight;
};
// the definition of the HuffmanTree Encoding class implementation
template<typename T>
class HuffmanTree
{
typedef HuffmanTreeNode<T>* pNode;
public:
HuffmanTree() :_pRoot(nullptr) {}
~HuffmanTree() {
_destory(_pRoot);
}
HuffmanTree(T* array, size_t size, const T& invalid) {
_createHuffmanTree(array, size, invalid);
}
pNode getRoot() {
return _pRoot;
}
private:
// create the HuffmanTree
void _createHuffmanTree(T* array, size_t size, const T& invalid) {
struct PtrNodeCompare {
// override the operator ()
bool operator()(pNode lhs, pNode rhs) {
return lhs->_weight < rhs->_weight;
}
};
std::priority_queue<pNode, std::vector<pNode>, PtrNodeCompare> hp; // define the minHeap
for (size_t i = 0; i < size; ++i) {
if (array[i] != invalid) {
hp.push(new HuffmanTreeNode<T>(array[i])); // push into the minHeap
}
}
if (hp.empty())
_pRoot = nullptr;
// build the huffmanTree
while (hp.size() > 1) {
pNode pLeft = hp.top();
hp.pop();
pNode pRight = hp.top();
hp.pop();
pNode pParent = new HuffmanTreeNode<T>{ pLeft->_weight + pRight->_weight,
pLeft, pRight };
pLeft->_pParent = pRight->_pParent = pParent;
hp.push(pParent);
}
_pRoot = hp.top(); // the left only one node is the root of the tree
}
void _destory(pNode& pRoot) {
if (pRoot) {
_destory(pRoot->_pLeft);
_destory(pRoot->_pRight);
delete pRoot;
pRoot = nullptr;
}
}
public:
pNode _pRoot;
};
#endif
利用Huffman树实现的文件压缩与解压
https://github.com/sesiria/Algs/tree/master/Lib/CompressLibrary
以上是关于数据流压缩原理实现(huffman编码,LZ77压缩算法)的主要内容,如果未能解决你的问题,请参考以下文章