查找专题
Posted Rainbowman 0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了查找专题相关的知识,希望对你有一定的参考价值。
1. 静态查找
静态查找 vs 动态查找
静态查找只做查询操作,而动态查找表还需要做插入和删除操作,如:若查找的元素不在表中,则进行插入;或删除查找到的元素。
静态查找中主要想说二分查找,这是一种很简单但很高效的查找方式,但只能针对有序表,无序表不能进行二分查找。
最好情况下时间复杂度为O(1)
最坏情况下时间复杂度为O(logn)
来道leetcode例题
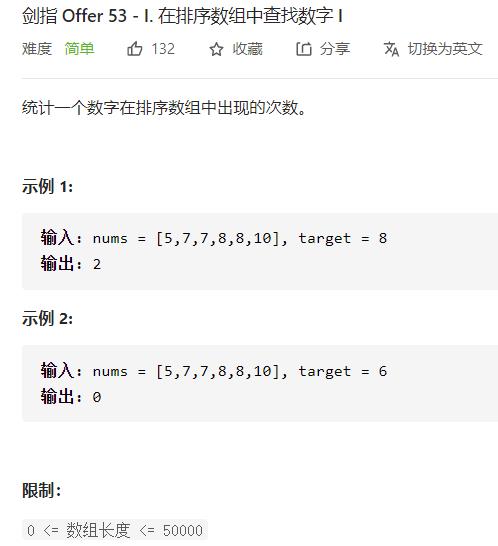
class Solution {
public:
int search(vector<int>& nums, int target) {
if(nums.empty()) return 0;
int l = 0, r = nums.size()-1;
int count = 0;
int i;
while(l<=r){
i = (l + r)/2;
if(nums[i]==target) break;
if(nums[i]<target) l = i + 1;
else r = i - 1;
}
if(l>r) return 0;
for(int j=i-1; j>=0; j--){
if(nums[j]!=target) break;
count++;
}
for(int j=i; j<nums.size(); j++){
if(nums[j]!=target) break;
count++;
}
return count;
}
};
2. 动态查找
动态查找主要想说的是二叉排序树的查找、增加和删除结点的问题。
二叉排序树的左子树结点的值均小于根结点,右子树结点的值均大于根结点,左右子树也是二叉搜索树(递归定义)。
二叉排序树有一条重要性质:
使用中序遍历二叉排序树,得到的是一递增序列。
二叉排序树的查找:
因为二叉排序树的特殊性质,所以查找某一元素是否在二叉排序树中时,不需要像别的二叉树一样使用先序(或中序或后序)遍历所有的元素,而只需:
比较要查找的元素N和根元素的大小:
(1)若相等,则返回指向根结点的指针;
(2)若小于根元素,则继续查找根结点的左子树;
(3)若大于根元素,则继续查找根结点的右子树;
若最后找到,则返回找到结点的指针;若未找到,则返回空指针。
感觉有点二分查找的味道~
二叉排序树的插入:
插入是建立在查找的基础上完成的:在查找过程中,若没找到则返回空指针,之所以返回空指针是因为找到最后的叶子结点的孩子结点了(当然为空)还没找到,而我们要插入的元素即为该叶子节点的孩子(左孩子或有孩子)。
因此,查找过程中需要有一个先驱指针f指向目前对比结点p的父亲结点,若目前对比结点已经为空(说明没有查到),则将要查找的元素插入到f结点的孩子结点(左孩子或右孩子)。
注意: 若二叉排序树为空树,则新插入的结点为新的根结点;否则,新插入的结点必为一个新的叶子结点,其插入位置由查找过程得到。
二叉排序树的删除:
删除某结点有三种情况:
(1)要删除的是叶子结点:
直接删除,然后将其父亲结点的相应指针置为空;
(2)要删除的结点只有左子树(或右子树):
将其父亲结点的相应指针指向其左子树(或右子树),然后删除该结点;
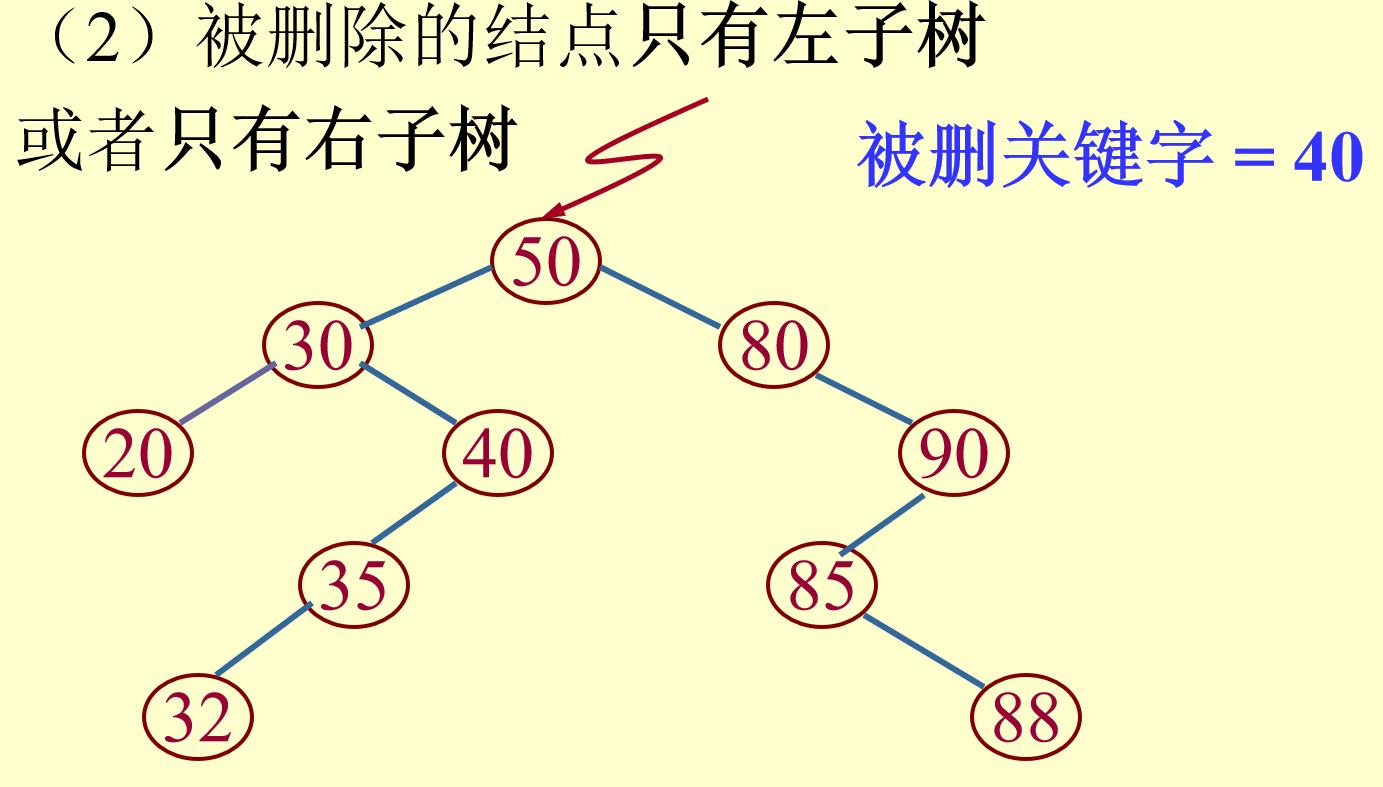
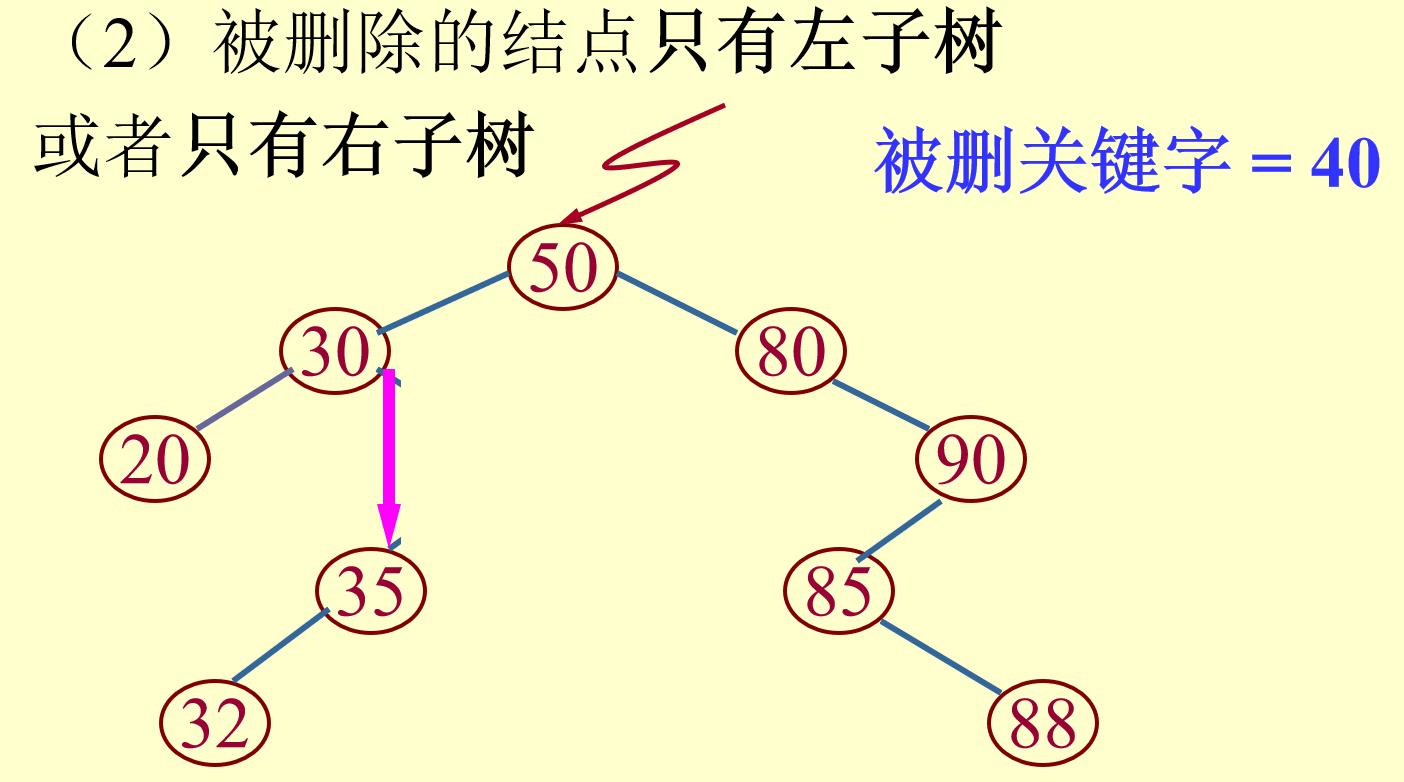
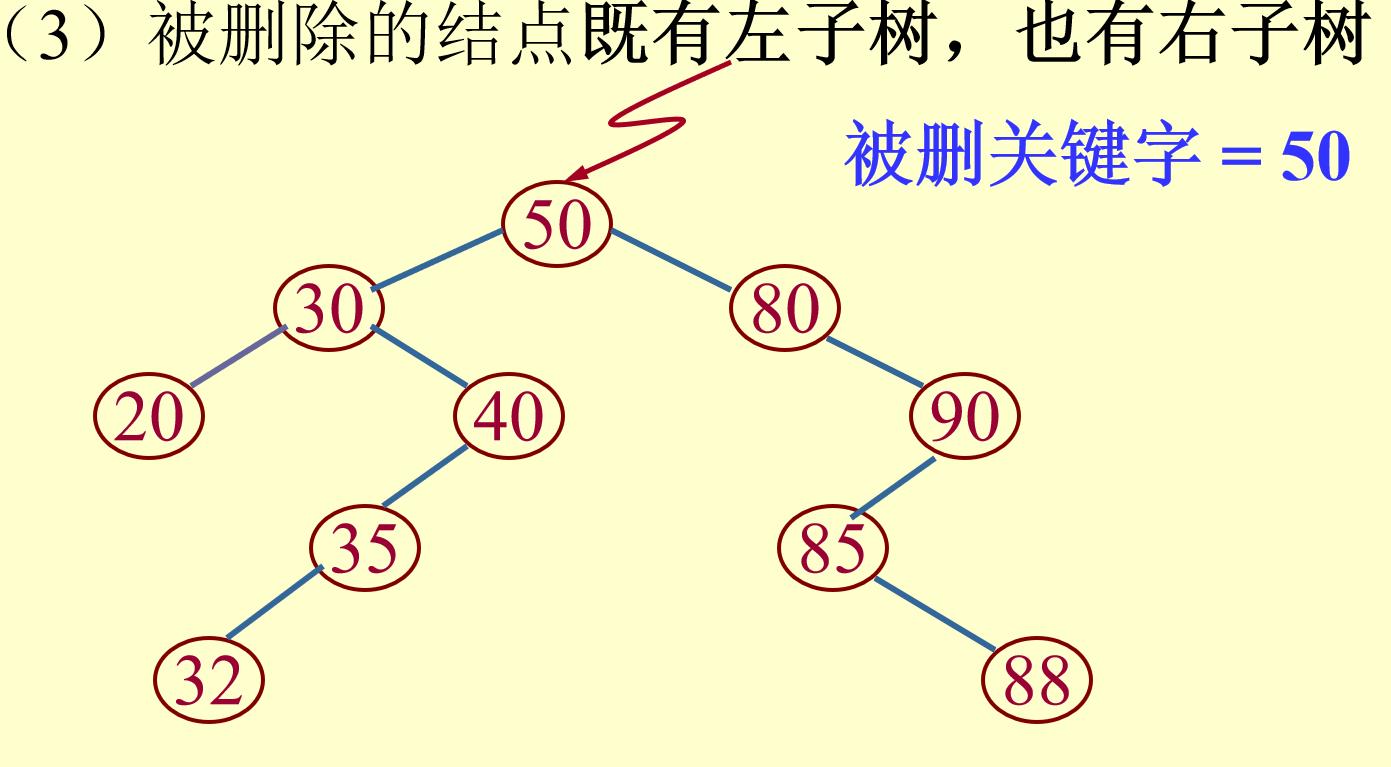
(3)要删除的结点既有左子树又有右子树:
找到其前驱节点,即该二叉排序树中第一个比要删除的结点小的结点(位于要删除结点的左子树的最右边,即其没有右子树),将要删除的结点的值置为前驱结点的值,然后将前驱结点的父结点的指针指向前驱结点的左子树(即删除前驱节点;)
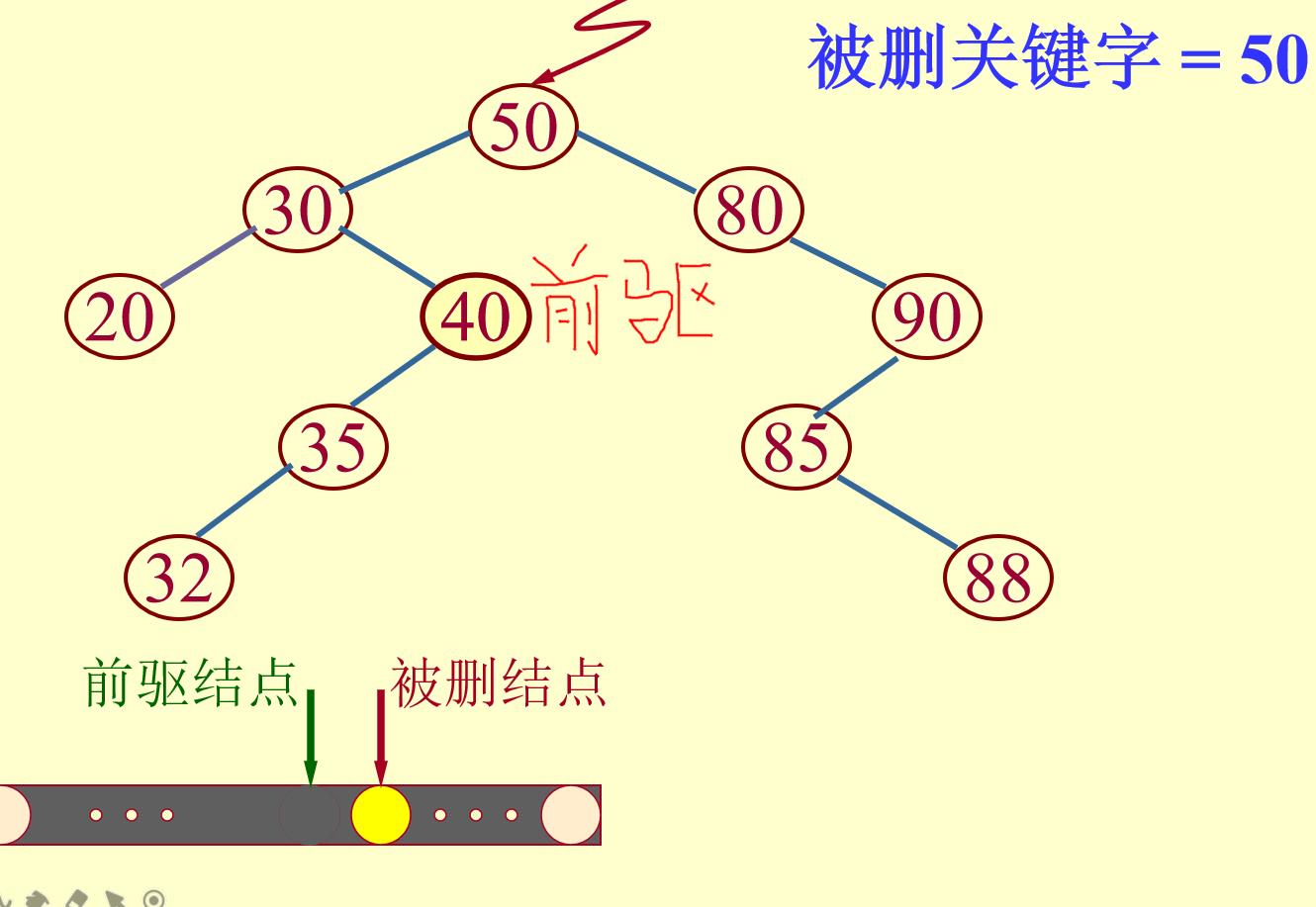
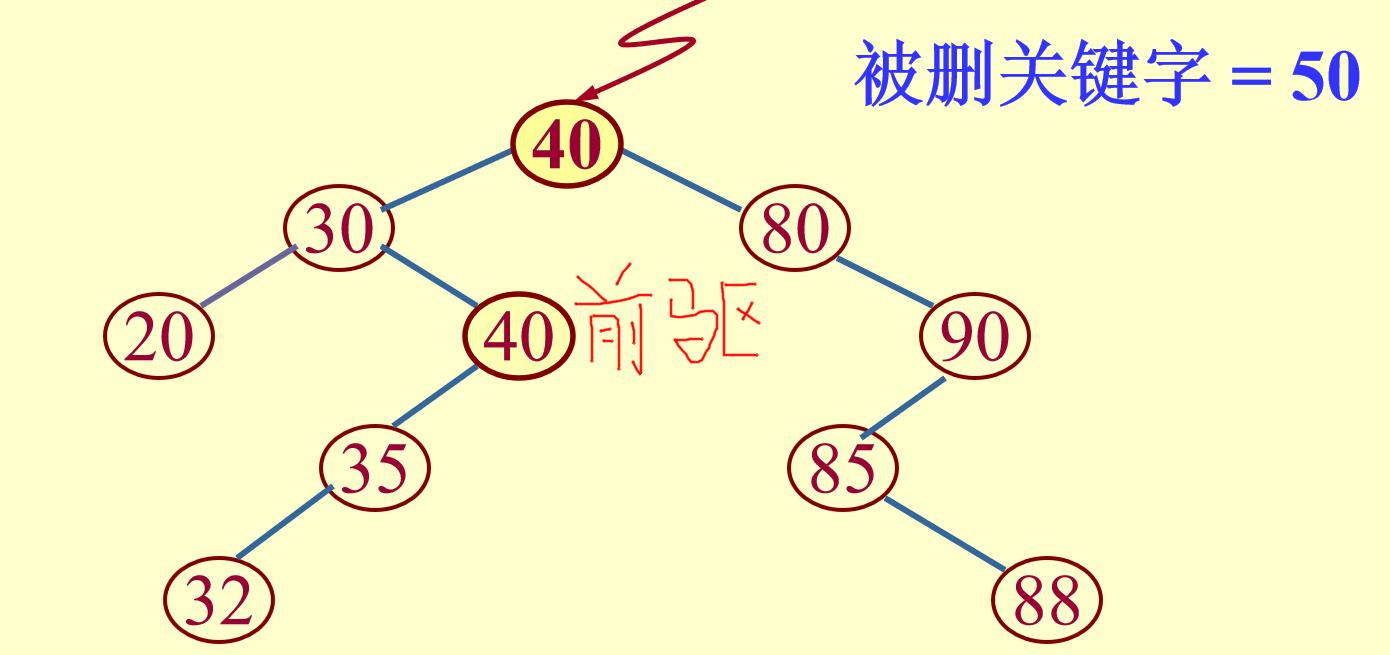
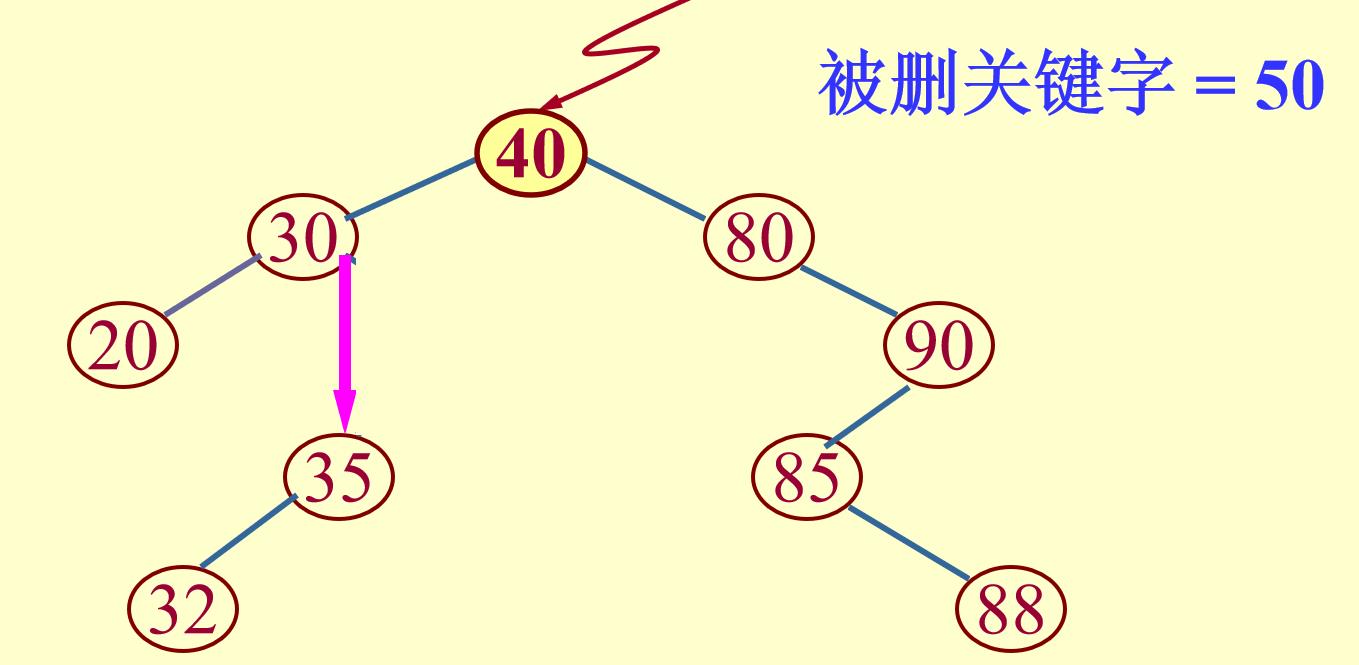
二叉排序树的插入、查找、删除代码:
#include <iostream>
#include <stdlib.h>
using namespace std;
struct BiTreeNode
{
int data;
BiTreeNode *lchild;
BiTreeNode *rchild;
};
typedef BiTreeNode * BiTree;
bool SearchBST(BiTree T,int N,BiTreeNode *f,BiTreeNode * &p)
{
if(!T){p=f;return false;}
else if(T->data==N) {p=T;return true;}
else if(N<T->data) SearchBST(T->lchild,N,T,p);
else if(N>T->data) SearchBST(T->rchild,N,T,p);
}
//插入特点:新插入的结点一定是个叶子结点,而且是
//查找不成功时p指向查找路径上的最后一个结点(要插入的结点为该结点的左孩子或右孩子)
bool InsertBST(BiTree &T,int N)
{
BiTreeNode *f=0;
BiTreeNode *p=0;
if(!SearchBST(T,N,f,p))
{
BiTreeNode *s=new BiTreeNode();
s->data=N;
s->lchild=0;s->rchild=0;
//这一个别忘了!!
if(!p)T=s;
else if(N<p->data)p->lchild=s;
else if(N>p->data)p->rchild=s;
return true;
}
return false;
}
void InOrdTraverse(BiTree T)
{
if(T)
{
InOrdTraverse(T->lchild);
cout<<T->data<<" ";
InOrdTraverse(T->rchild);
}
}
// 删除节点
bool Delete(BiTree &p)
{
if(!p->lchild)
{
BiTree q=p;
p=p->rchild;
free(q);
return true;
}
else if(!p->rchild)
{
BiTree q=p;
p=p->lchild;
free(q);
return true;
}
else
{
BiTree q=p;
BiTree s=p->lchild;
while(s->rchild){q=s;s=s->rchild;}
p->data=s->data;
if(q!=p)q->rchild=s->lchild;
if(q==p)p->lchild=s->lchild;
free(s);
return true;
}
return false;
}
bool DeleteBST(BiTree &T,int N)
{
if(!T) return false;
if(N==T->data){Delete(T);return true;}
else if(N<T->data){DeleteBST(T->lchild,N);}
else DeleteBST(T->rchild,N);
}
const int N=5;
int main()
{
BiTree T=0;
int a[N];
for(int i=0;i<N;i++)cin>>a[i];
for(int i=0;i<N;i++){InsertBST(T,a[i]);}
InOrdTraverse(T);
int b[N];
for(int i=0;i<N;i++){
cin>>b[i];
DeleteBST(T,b[i]);
InOrdTraverse(T);
}
return 0;
}
3. 哈希表
哈希表是以空间换时间的策略,重点有哈希函数的构建和如何解决冲突。
哈希函数有很多种,主要是需要保证元素能均匀分布在哈希表中。
如何解决冲突?
(1)开放定址法:
思想:当经过映射函数(哈希函数)找到的地址发生冲突时,在该地址的基础上寻找别的地址。
Hi= ( H(key)+di ) MOD m, i= 1,2, … k ( k ≤ m-1) m 为表长, di 的取法:
① di=1,2,3, …, m-1 称线性探测再散列;
② di=12,-12,22,-22,32,-32,…±k2 (k ≤ m/2), 称为二次探测再散列;
③ di=伪随机数系列; 伪随机探测再散列。
(2)再哈希法:
思想:当发生地址冲突时,使用别的哈希函数重新计算地址,直到地址不发生冲突为止(增加了计算时间)
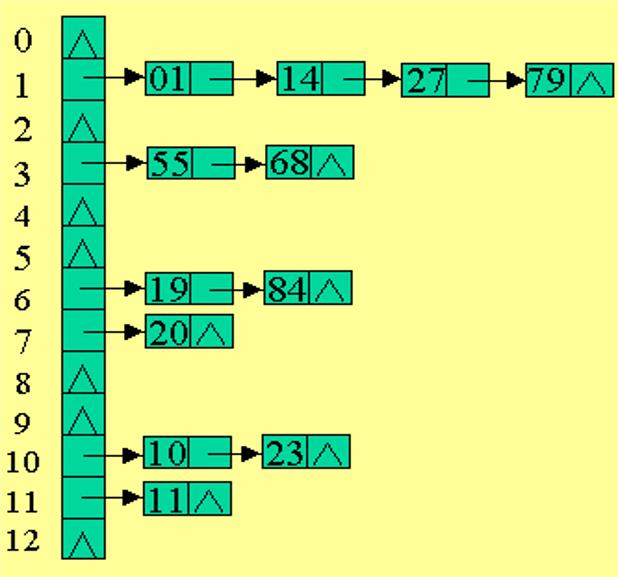
(3)链表法:
思想:将所有关键字为同义词的记录存储在同一线性链表中
例子:已知一组关键字为:(19,14,23,01,68,20,84,27,55,11,10,79);哈希函数 H(key)=key MOD 13 ;用链地址法处理冲突所得哈希表如下图。
以上是关于查找专题的主要内容,如果未能解决你的问题,请参考以下文章